






写在前面:踩了一天的雷,在一堆已经过时的帖子中不断寻找,终于解决了这个问题。
本文全部以stable diffusion为例,介绍了如何安装的方法,Stable Diffusion 支持多种操作模式,如 API 集成、直接运行预训练模型、以及与其他深度学习框架的结合。
!!!原则上适用于所有hugging face的大模型,无论你是想在本地或者服务器上下载安装使用都可以丝滑解决。
一、 关于hugging face
https://huggingface.co/![]() https://huggingface.co/在官网用邮箱创建自己的账户,建议使用gmail、outlook等邮箱,以防增加额外的工作量。
https://huggingface.co/在官网用邮箱创建自己的账户,建议使用gmail、outlook等邮箱,以防增加额外的工作量。
安装环境
安装 Python 以及一些依赖,如 torch、transformers、diffusers 。最简单的方式是使用 Python 或者 Conda 虚拟环境
stable-diffusion-v1-4配置环境参考以下文章,先不要着急点开
基于 huggingface diffuser 库本地部署 Stable diffusion_huggingface stable diffusion-CSDN博客
作者给的环境配置如下:
conda create -n diffenv python=3.8
conda activate diffenv
pip install diffusers==0.4.0
pip install transformers scipy ftfy
# pip install "ipywidgets>=7,<8" 这个是colab用于交互输入的控件安装好环境以后,如果纯小白或者跨领域的同学看到作者下面这一段话,简直半天摸不着头脑,几个网站跳来跳去也不知所措,其实很简单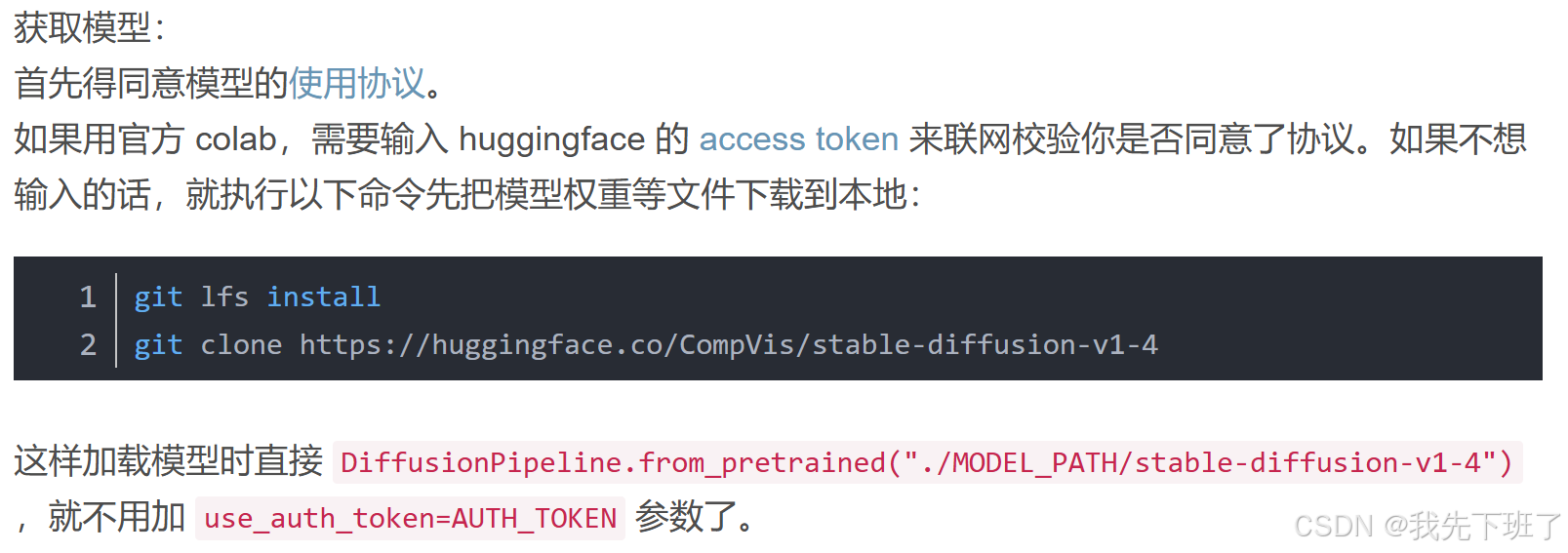
二、获取模型
有几个方法,如果你没有时间,我推荐第三个:
1. 不是一个好方法
没必要深究。在这里列出这种可能也是以防万一。
创建hugging_face账号并生成 access token(API 密钥)。然后,使用下面的代码来下载模型:
from diffusers import StableDiffusionPipeline
from huggingface_hub import login
login(token="your_huggingface_api_key")
# 加载 Stable Diffusion 模型
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v-1-4-original")
pipe.to("cuda") # 将模型加载到 GPU2. 不推荐
有部分同学使用服务器没有sudo权限、也没有git或者git-lfs,或者下载起来特别慢。如果你很幸运有网络支持,不会被墙困扰,可以用上述文章中作者的方法,代码如下:
git lfs install
git clone https://huggingface.co/CompVis/stable-diffusion-v1-43.!!!推荐!!!
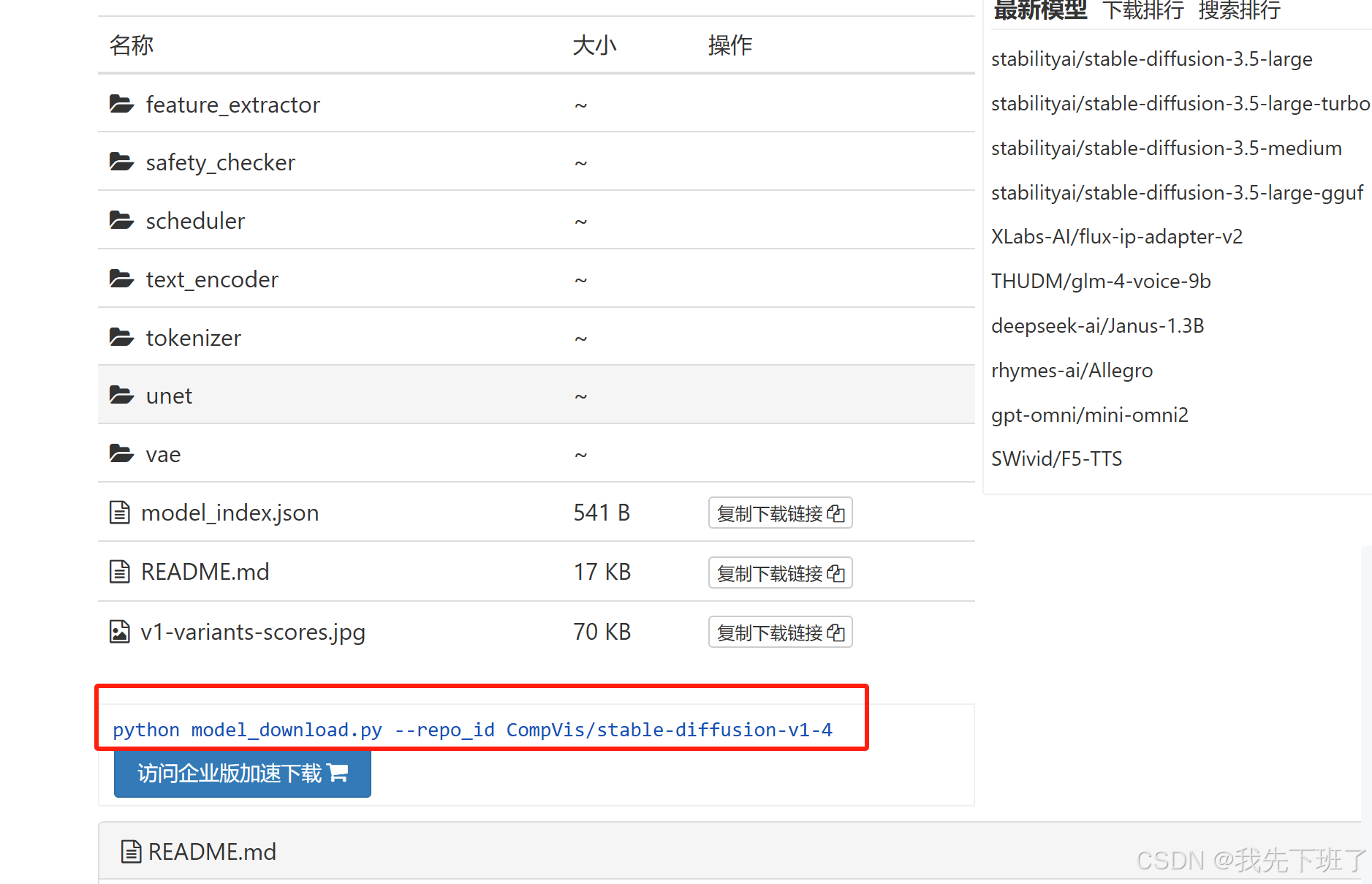
用hugging_face的国内镜像网站,在网站主页搜索你需要的大模型名字互链高科![]() https://aliendao.cn/models/CompVis/stable-diffusion-v1-4
https://aliendao.cn/models/CompVis/stable-diffusion-v1-4
wget https://aliendao.cn/model_download.py #用来下载大模型的脚本
python model_download.py --repo_id CompVis/stable-diffusion-v1-4 #下载模型其他的模型在搜索后寻找红框标记的代码语句
 三、使用模型
三、使用模型
楼上文章作者已经写得非常详细了,这里我补充一个如何使用初始图像对模型生成图像进行限制。
import torch
from PIL import Image
from diffusers import StableDiffusionPipeline
from torchvision import transforms
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v-1-4-original")
pipe.to("cuda") # gpu
init_image_path = "path_to_your_image.jpg" #初始图像的地址
init_image = Image.open(init_image_path).convert("RGB")
init_image = init_image.resize((512, 512))#调整大小
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
init_image_tensor = transform(init_image).unsqueeze(0).to("cuda")
prompt = "A futuristic city skyline at sunset" #文字提示
guidance_scale = 7.5 # 引导强度(文本对生成结果的影响)
num_inference_steps = 50 # 推理步数
#调用模型生成图像
generated_image = pipe(prompt=prompt, init_image=init_image_tensor,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale)["sample"][0]

















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









