






智能体(agent)就是某种能够采取行动的东西(agent来自拉丁语agere,意为“做”)。当然,所有计算机程序都可以完成一些任务,但我们期望计算机智能体能够完成更多的任务:自主运行、感知环境、长期持续存在、适应变化以及制定和实现目标。理性智能体(rational agent)需要为取得最佳结果或在存在不确定性时取得最佳期望结果而采取行动。
简而言之,人工智能专注于研究和构建做正确的事情的智能体,其中正确的事情是我们提供给智能体的目标定义。这种通用范式非常普遍,以至于我们可以称之为标准模型(standard model)。
1. 智能体与环境
任何通过传感器(sensor)感知环境(environment)并通过执行器(actuator)作用于该环境的事物都可以被视为智能体(agent)。一个人类智能体以眼睛、耳朵和其他器官作为传感器,以手、腿、声道等作为执行器。机器人智能体可能以摄像头和红外测距仪作为传感器,还有各种电动机作为执行器。软件智能体接收文件内容、网络数据包和人工输入(键盘/鼠标/触摸屏/语音)作为传感输入,并通过写入文件、发送网络数据包、显示信息或生成声音对环境进行操作。
这里的环境可以是一切,甚至是整个宇宙!实际上,我们在设计智能体时关心的只是宇宙中某一部分的状态,即影响智能体感知以及受智能体动作影响的部分。如下图:
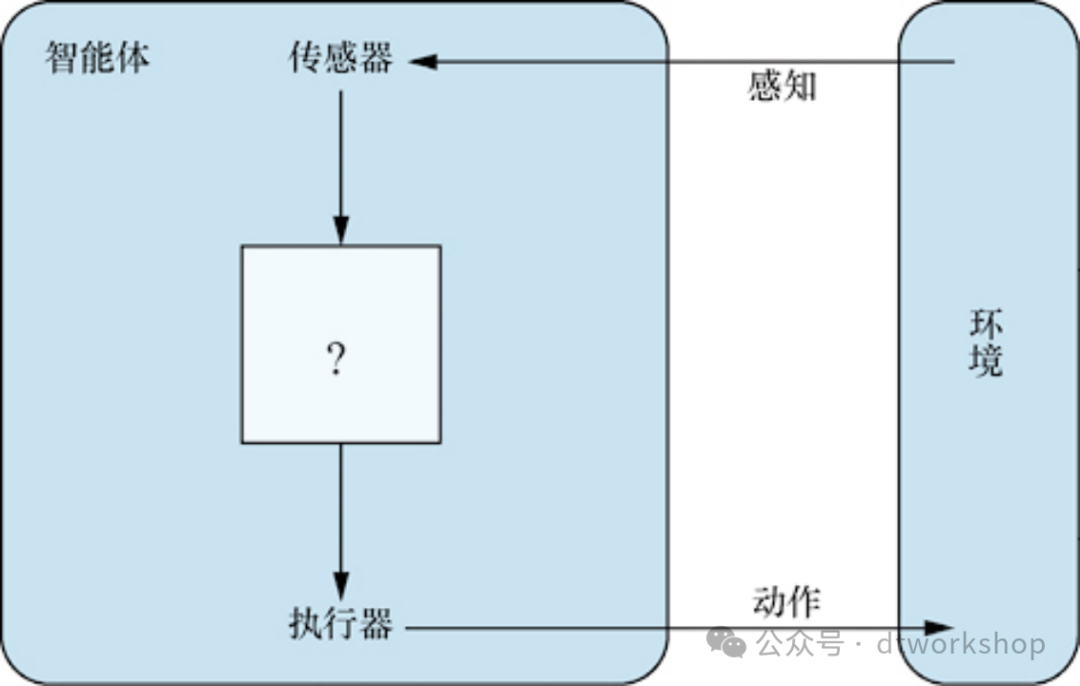
我们使用术语感知(percept)来表示智能体的传感器正在感知的内容。智能体的感知序列(percept sequence)是智能体所感知的一切的完整历史。一般而言,一个智能体在任何给定时刻的动作选择可能取决于其内置知识和迄今为止观察到的整个感知序列,而不是它未感知到的任何事物。通过为每个可能的感知序列指定智能体的动作选择,我们或多或少地说明了关于智能体的所有内容。从数学上讲,我们说智能体的行为由智能体函数(agent function)描述,该函数将任意给定的感知序列映射到一个动作。在内部,人工智能体的智能体函数将由智能体程序(agent program)实现。区别这两种观点很重要,智能体函数是一种抽象的数学描述,而智能体程序是一个具体的实现,可以在某些物理系统中运行。
(1)理性智能体
理性智能体(rational agent)是做正确事情的事物。
道德哲学发展了几种不同“正确事情”的概念,但人工智能通常坚持一种称为结果主义(consequentialism)的概念:我们通过结果来评估智能体的行为。当智能体进入环境时,它会根据接受的感知产生一个动作序列。这一动作序列会导致环境经历一系列的状态。如果序列是理想的,则智能体表现良好。这种可取性的概念由性能度量(performance measure)描述,该度量评估任何给定环境状态的序列。
在任何时候,理性取决于以下四方面:a. 定义成功标准的性能度量;b. 智能体对环境的先验知识;c. 智能体可以执行的动作;d. 智能体到目前为止的感知序列。
因此理性智能体的定义为:对于每个可能的感知序列,给定感知序列提供的证据和智能体所拥有的任何先验知识,理性智能体应该选择一个期望最大化其性能度量的动作。
(2)环境的本质
环境的本质是任务环境(task environment),它本质上是“问题”,理性智能体是“解决方案”。
在设计智能体时,第一步必须始终是尽可能完整地指定任务环境。可以依据PEAS(Performance,Environment,Actuator,Sensor)的框架来描述。一些智能体类型及其PEAS描述的示例如下:

2. 智能体的架构
人工智能的工作是设计一个智能体程序(agent program)实现智能体函数,即从感知到动作的映射。假设该程序将运行在某种具有物理传感器和执行器的计算设备上,我们称之为智能体架构(agent architecture):
智能体 = 架构 + 程序
显然,我们选择的程序必须是适合相应架构的程序。如果程序打算推荐步行这样的动作,那么对应的架构最好有腿。架构可能只是一台普通PC,也可能是一辆带有多台车载计算机、摄像头和其他传感器的机器人汽车。通常,架构使程序可以使用来自传感器的感知,然后运行程序,并将程序生成的动作选择反馈给执行器。
(1)智能体程序
在本篇的智能体程序都有相同的框架:它们将当前感知作为传感器的输入,并将动作返回给执行器。
人工智能面临的关键挑战是找出编写程序的方法,尽可能从一个小程序而不是从一个大表中产生理性行为。
历史上有许多例子表明,在其它领域可以成功地做到这一点:例如, 20世纪70年代以前,工程师和学生使用的巨大平方根表格,现在已经被电子计算器上运行的仅有5行代码的牛顿方法所取代。现在问题是,人工智能能像牛顿处理平方根那样处理一般智能行为吗?我们相信答案是肯定的。
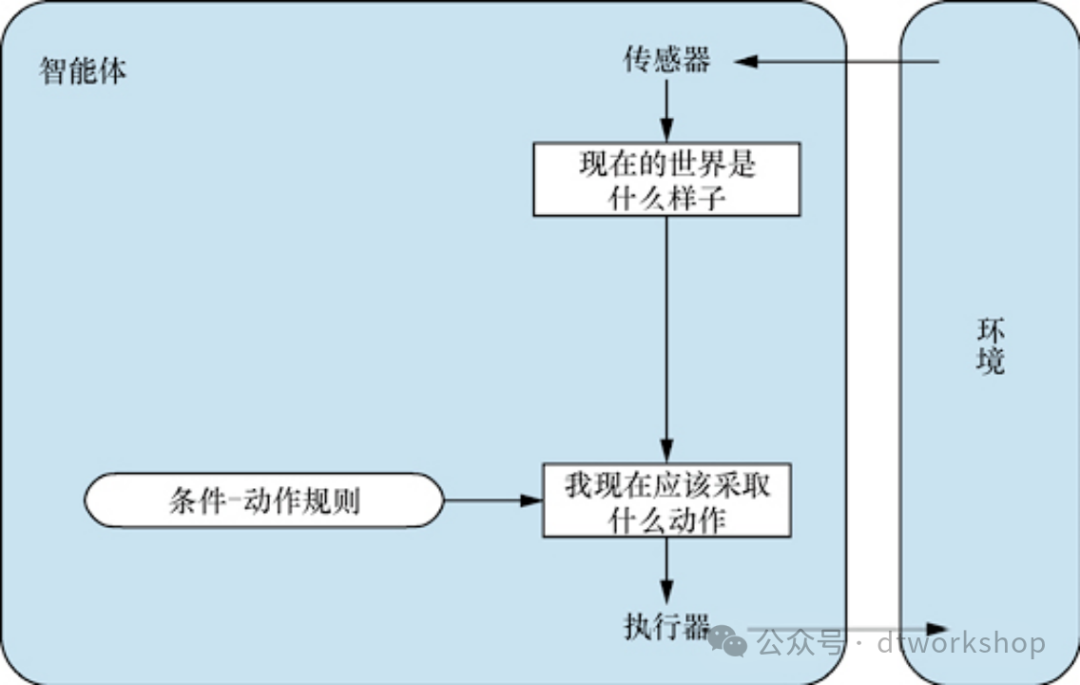
a. 简单反射性智能体
最简单的智能体是简单反射型智能体(simple reflex agent)。这些智能体根据当前感知选择动作,忽略感知历史的其余部分。简单反射型智能体的示意图如下。我们使用矩形表示智能体决策过程的当前内部状态,使用椭圆表示过程中使用的背景信息。
b. 基于模型的反射性智能体
处理部分可观测性的最有效方法是让智能体追踪它现在观测不到的部分世界。也就是说,智能体应该维护某种依赖于感知历史的内部状态(internal state),从而至少反映当前状态的一些未观测到的方面。
随着时间的推移,更新这些内部状态信息需要在智能体程序中以某种形式编码两种知识。首先,需要一些关于世界如何随时间变化的信息,这些信息大致可以分为两部分:智能体行为的影响和世界如何独立于智能体而发展。例如,当智能体顺时针转动方向盘时,汽车就会向右转;而下雨时,汽车的摄像头就会被淋湿。这种关于“世界如何运转”的知识(无论是在简单的布尔电路中还是在完整的科学理论中实现)被称为世界的转移模型(transition model)。
其次,我们需要一些关于世界状态如何反映在智能体感知中的信息。例如,当前面的汽车开始刹车时,前向摄像头的图像中会出现一个或多个亮起的红色区域;当摄像头被淋湿时,图像中会出现水滴状物体并部分遮挡道路。这种知识称为传感器模型(sensor model)。
转移模型和传感器模型结合在一起让智能体能够在传感器受限的情况下尽可能地跟踪世界的状态。使用此类模型的智能体称为基于模型的智能体(model-based agent)。
下图给出了基于模型的反射型智能体的结构,它具有内部状态,展示了当前感知如何与旧的内部状态相结合,并基于世界如何运转的模型生成当前状态的更新描述。
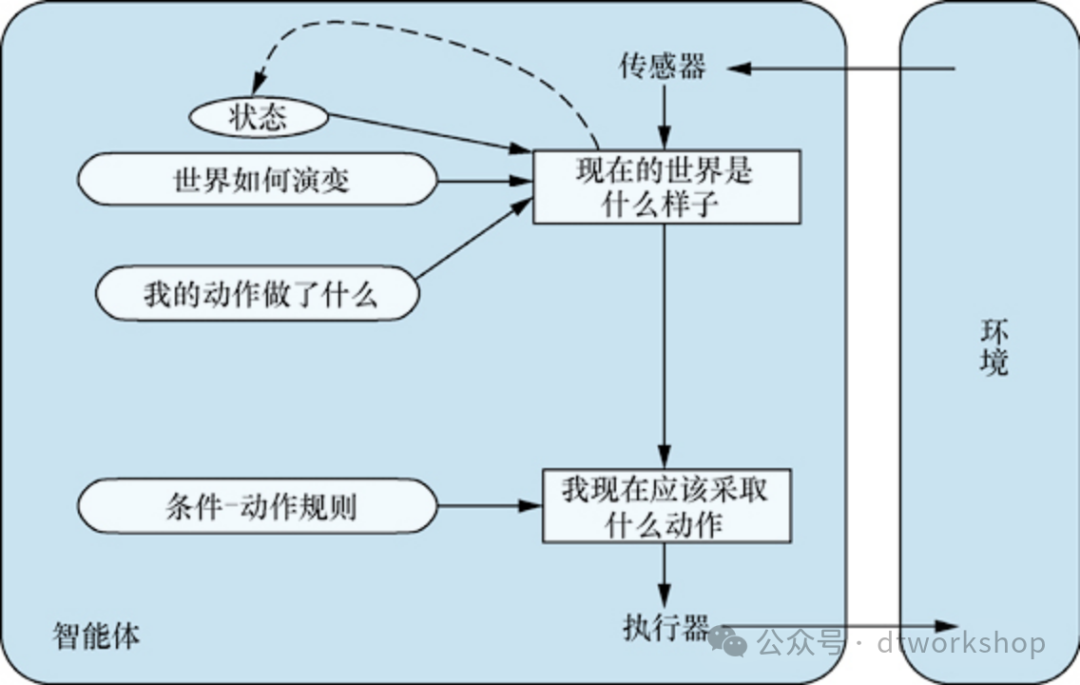
基于模型的反射型智能体。它使用内部模型追踪世界的当前状态,然后以与反射型智能体相同的方式选择动作。
c. 基于目标的智能体
了解环境的现状并不总是足以决定做什么。例如,在一个路口,出租车可以左转、右转或直行。正确的决定取决于出租车要去哪里。换句话说,除了当前状态的描述之外,智能体还需要某种描述理想情况的目标信息,例如设定特定的目的地。智能体程序可以将其与模型(与基于模型的反射型智能体中使用的信息相同)相结合,并选择实现目标的动作。下图展示了基于目标的智能体结构。
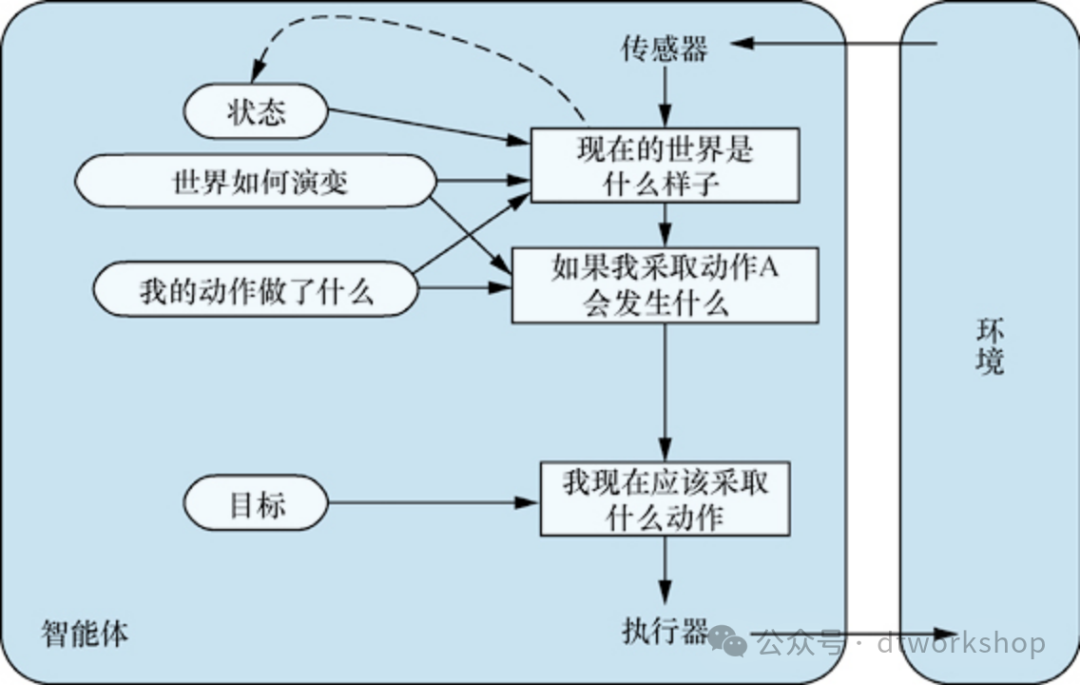
注意,这类决策从根本上不同于前面描述的条件-动作规则,因为它涉及对未来的考虑,包括“如果我这样做会发生什么?”和“这会让我快乐吗?”在反射型智能体设计中,这种信息并没有被明确地表示出来,因为内置规则直接从感知映射到动作。反射型智能体在看到刹车灯时刹车,但它不知道为什么。基于目标的智能体在看到刹车灯时会刹车,因为这是它预测的唯一动作,这个动作可以实现不撞到其他汽车的目标。
尽管基于目标的智能体看起来效率较低,但它更灵活,因为支持其决策的知识是显式表示的,并且可以修改。例如,只要将目的地指定为目标,就可以很容易地更改基于目标的智能体的行为,以到达不同的目的地。反射型智能体关于何时转弯和何时直行的规则只适用于单一目的地,这些规则必须全部更换才能去新的目的地。
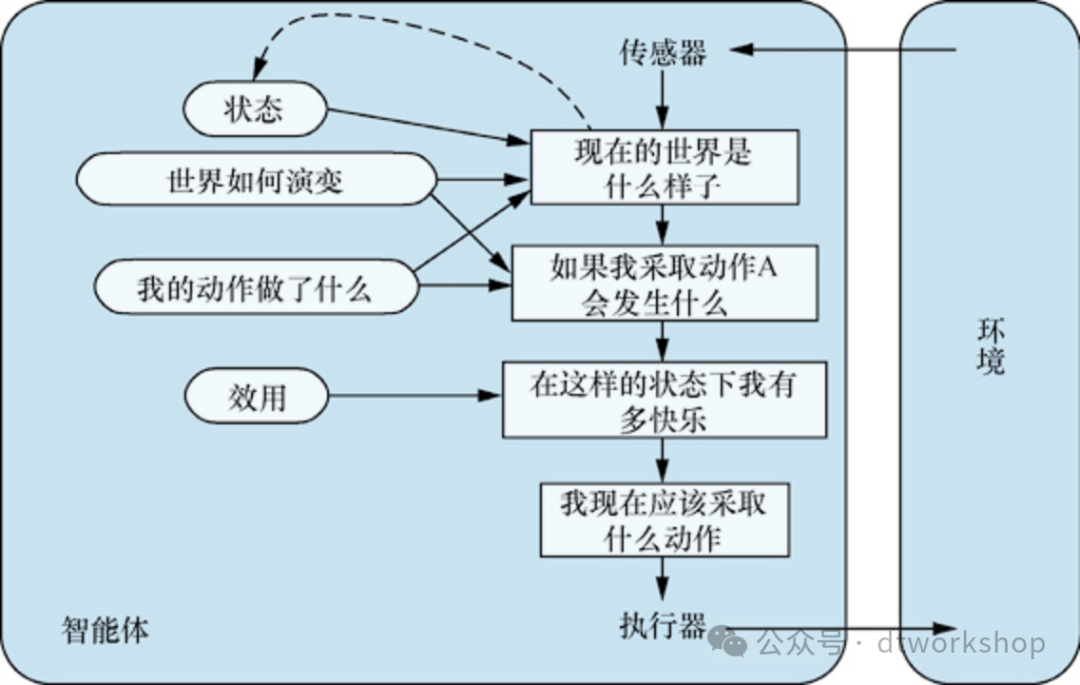
d. 基于效用的智能体
在大多数环境中,仅靠目标并不足以产生高质量的行为。例如,许多动作序列都能使出租车到达目的地(从而实现目标),但有些动作序列比其他动作序列更快、更安全、更可靠或更便宜。目标只是在“快乐”和“不快乐”状态之间提供了一个粗略的二元区别。更一般的性能度量应该允许根据不同世界状态的“快乐”程度对智能体进行比较。经济学家和计算机科学家通常用效用(utility)这个词来代替“快乐”,因为“快乐”听起来不是很科学。
我们已经看到,性能度量会给任何给定的环境状态序列打分,因此它可以很容易地区分到达出租车目的地所采取的更可取和更不可取的方式。智能体的效用函数(utility function)本质上是性能度量的内部化。如果内部效用函数和外部性能度量一致,那么根据外部性能度量选择动作,以使其效用最大化的智能体是理性的。
部分可观测性和非确定性在真实世界中普遍存在,因此,不确定性下的决策也普遍存在。从技术上讲,基于效用的理性智能体会选择能够最大化其动作结果期望效用(expected utility)的动作,也就是在给定每个结果的概率和效用的情况下,智能体期望得到的平均效用。
基于模型、基于效用的智能体。它使用了一个世界模型以及一个效用函数来衡量它在各状态之间的偏好,然后选择产生最佳期望效用的动作,其中期望效用是通过对所有可能的结果状态和对应概率加权所得。如下图所示。
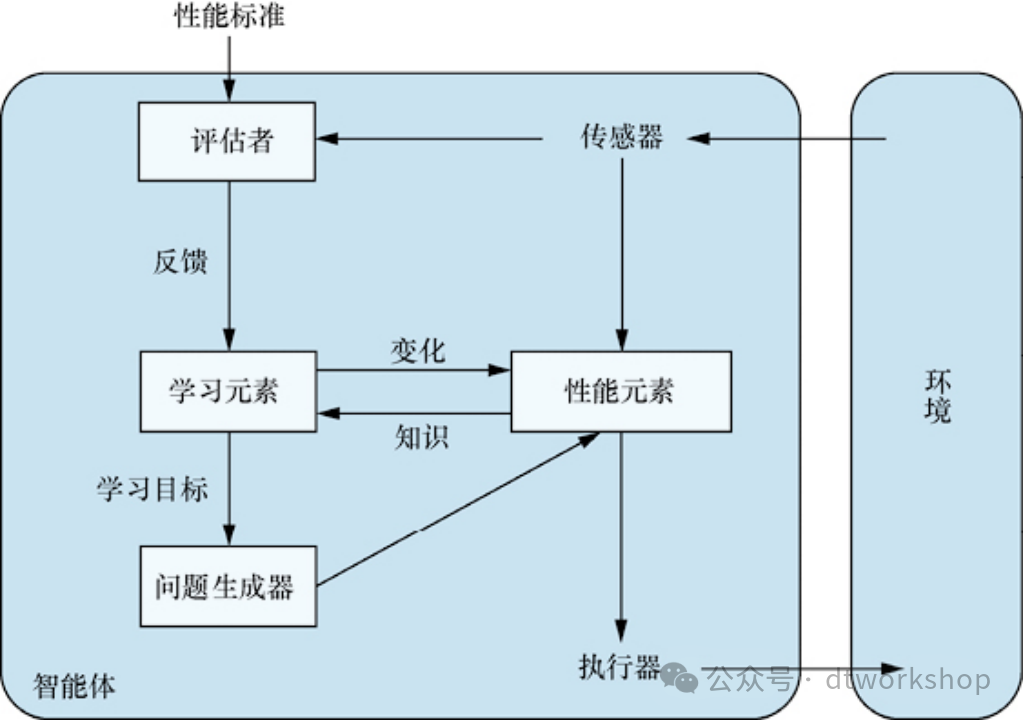
任何类型的智能体(基于模型、基于目标、基于效用等)都可以构建(或不构建)成学习型智能体。学习还有另一个优势:它让智能体能够在最初未知的环境中运作,并变得比其最初的知识可能允许的能力更强。
学习型智能体可分为4个概念组件如下图。最重要的区别在于负责提升的学习元素(learning element)和负责选择外部行动的性能元素(performance element)。性能元素是我们之前认为的整个智能体:它接受感知并决定动作。学习元素使用来自评估者(critic)对智能体表现的反馈,并以此确定应该如何修改性能元素以在未来做得更好。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









