







本文无代码
本文只在r2r数据集上进行实验
Vision-Language Navigation with Self-Supervised Auxiliary Reasoning Tasks
摘要: 视觉语言导航(VLN)是一项任务,代理按照自然语言指令进行学习导航。这项任务的关键是依次感知视觉场景和自然语言。传统方法利用跨模态基础中的视觉和语言特征。然而,VLN任务仍然具有挑战性,因为先前的工作忽略了环境中包含的丰富语义信息(如隐式导航图或子轨迹语义)。
在本文中,我们介绍了辅助推理导航(AuxRN),这是一个具有四个自监督辅助推理任务的框架,以利用从语义信息中导出的附加训练信号。辅助任务有四个推理目标:解释先前的动作、估计导航进度、预测下一个方向以及评估轨迹一致性。
因此,这些额外的训练信号有助于主体获取语义表示的知识,以便推理其活动并建立对环境的彻底感知。我们的实验表明,辅助推理任务大大提高了主任务的性能和模型的可概括性。从经验上看,我们证明了用自我监督辅助推理任务训练的代理大大优于先前最先进的方法,这是标准基准上现有的最佳方法。
一,介绍
1.1 之前的工作有哪些问题
- 过去的行动会影响未来的行动。要采取正确的行动,代理人必须彻底了解其过去的活动。
- 代理无法将轨迹与指令显式对齐,因此,不确定视觉语言编码是否能够完全表示代理的当前状态。
- 代理人无法准确评估其取得的进度。
- 由于导航图中只有相邻节点是可到达的,因此代理的动作空间是隐式限制的。因此,如果代理获得导航地图的知识并了解其下一个动作的结果,导航过程将更加准确和高效
1.2 本文怎么做的
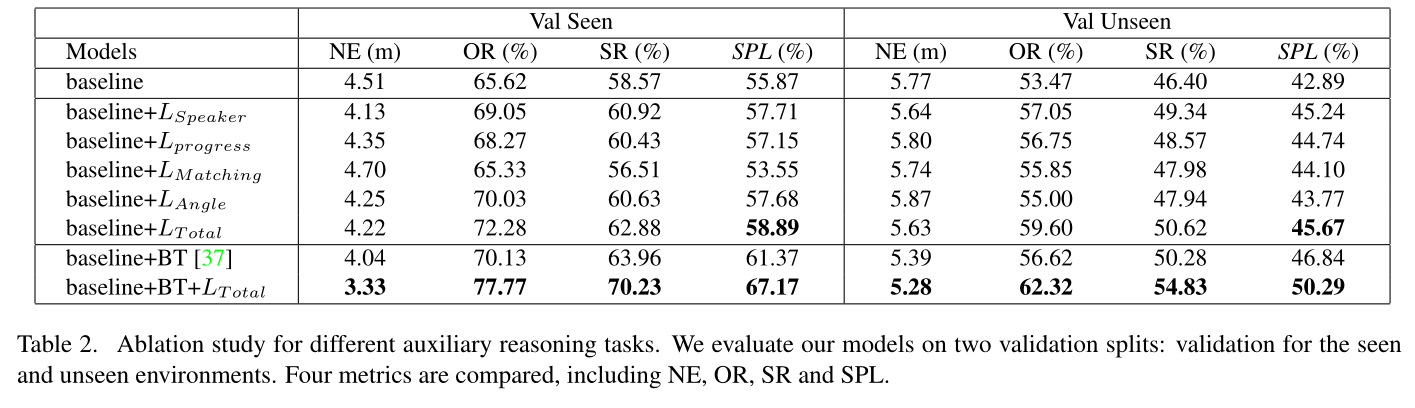
本文提出了以下几个辅助学习任务:
- 轨迹复述任务,使agent通过自然语言生成解释其先前的行为;
2) 进度估计任务,用于评估模型完成的轨迹百分比;
3) 角度预测任务,用于预测agent下一次转弯的角度。
4) 一种跨模式匹配任务,允许agent将视觉和语言编码对齐。
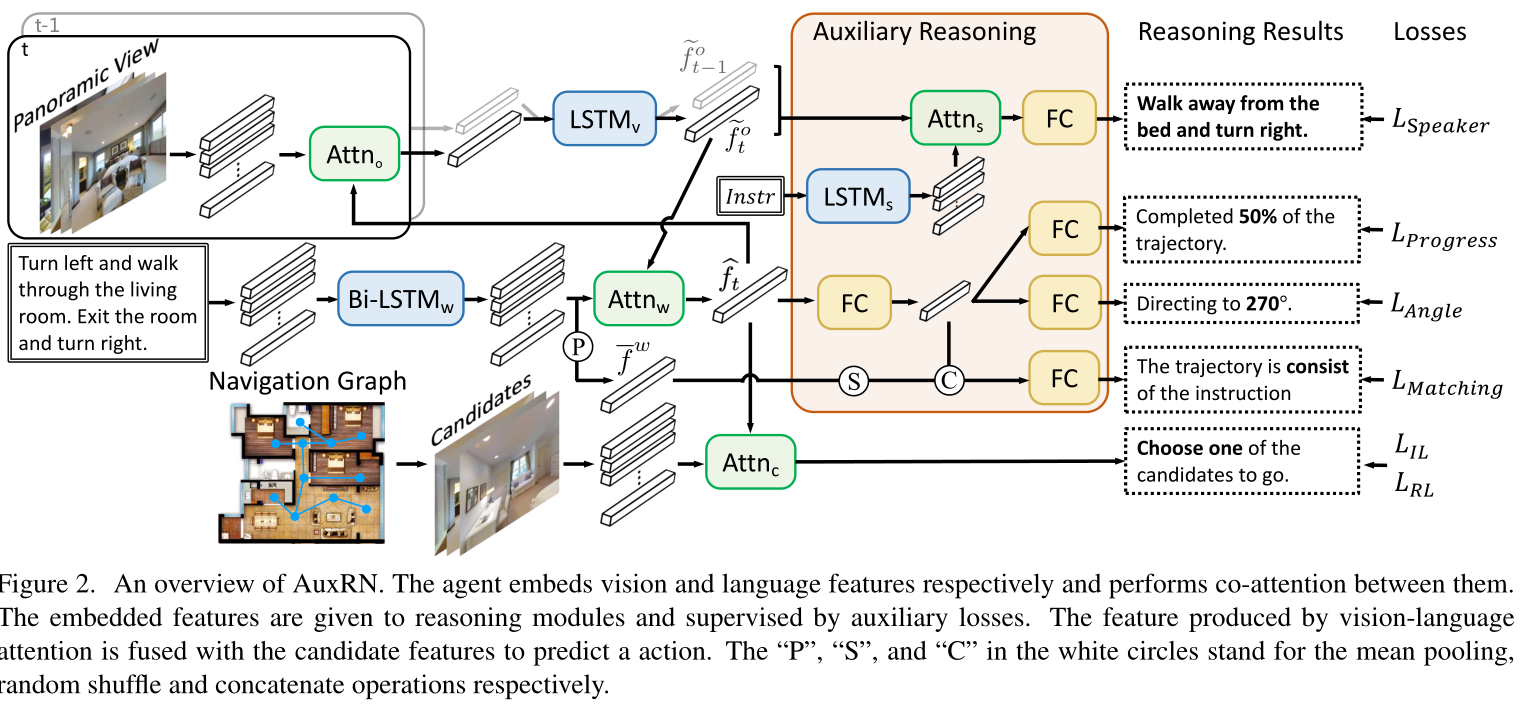
f
t
o
~
\tilde{f^{o}_{t}}
fto~,表示视觉内容
f ˉ w \bar{f}^w fˉw,表示语言内容
f t ^ \hat{f_{t}} ft^,表示跨模态内容
Trajectory Retelling Task
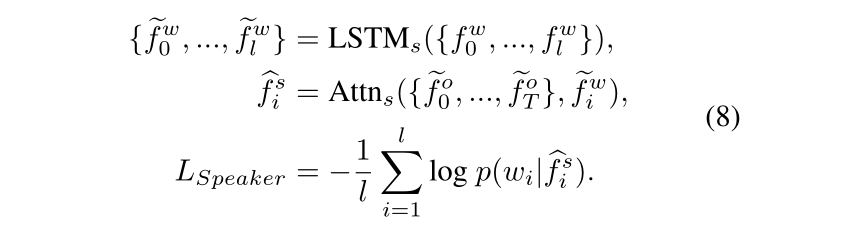
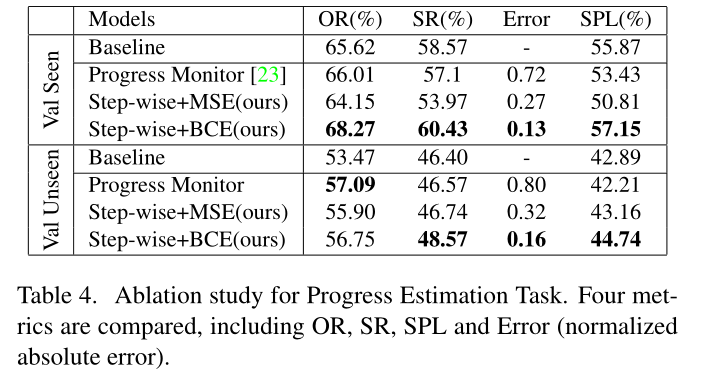
Progress Estimation Task
r
t
r_t
rt是steps的百分比
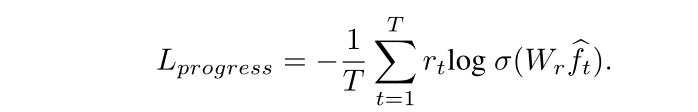
Cross-modal Matching Task
shuffled feature
f
′
ˉ
w
\bar{f^{'}}^w
f′ˉw
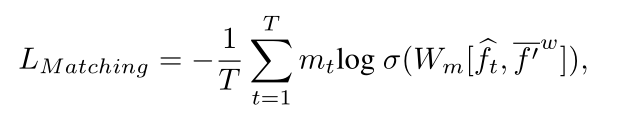
Angle Prediction Task
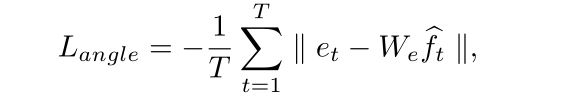
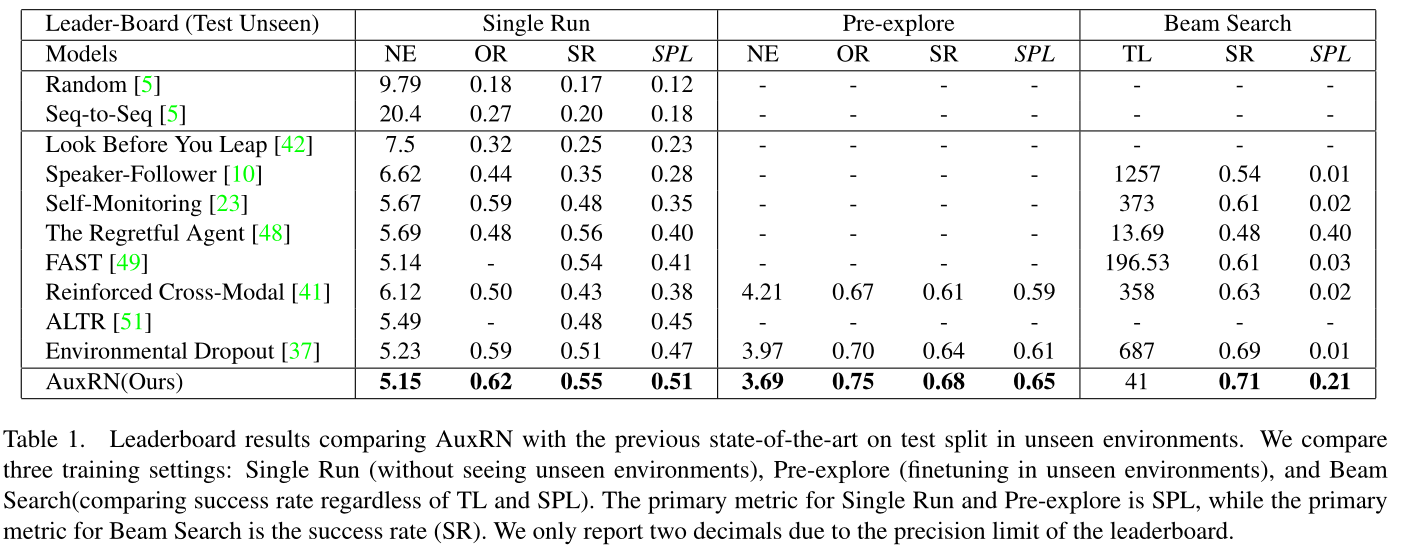
实验
- Single Run: without see-
ing the unseen environments and - Pre-explore: finetuning
a model in the unseen environments with self-supervised
approach. - Beam Search: predicting the trajectories with
the highest rate to success.
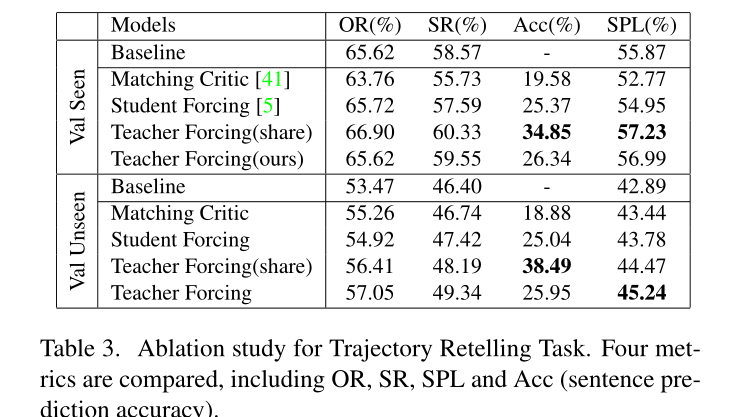
Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation. CVPR,2019 best-student paper
提出了一个匹配评判家,可以参考这个: https://blog.csdn.net/qq_40711769/article/details/104735036


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









