







Hbase基础
NoSQL
- NoSQL:not only SQL,非关系型数据库
- NoSQL是一个通用术语
- 指不遵循传统RDBMS模型的数据库
- 数据是非关系的,且不使用SQL作为主要查询语言
- 解决数据库的可伸缩性和可用性问题
- 不针对原子性或一致性问题
为什么使用NoSQL
- 互联网的发展,传统关系型数据库存在瓶颈
- 高并发读写
- 高存储量
- 高可用性
- 高扩展性
- 低成本
NoSQL和关系型数据库对比
- 主要有以下一些区别
| 对比 | NoSQL | 关系型数据库 |
|---|---|---|
| 常用数据库 | HBase、MongoDB、Redis | Oracle、DB2、MySQL |
| 存储格式 | 文档、键值对、图结构 | 表格式,行和列 |
| 存储规范 | 鼓励冗余 | 规范性,避免重复 |
| 存储扩展 | 横向扩展,分布式 | 纵向扩展(横向扩展有限) |
| 查询方式 | 结构化查询语言SQL | 非结构化查询 |
| 事务 | 不支持事务一致性 | 支持事务 |
| 性能 | 读写性能高 | 读写性能差 |
| 成本 | 简单易部署,开源,成本低 | 成本高 |
NoSQL的特点
- 最终一致性
- 应用程序增加了维护一致性和处理事务等职责
- 冗余数据存储
- NoSQL != 大数据
- NoSQL产品是为了帮助解决大数据存储问题
- 大数据不仅仅包含数据存储的问题
- Hadoop
- Kafka
- Spark,etc
NoSQL基础概念
- 三大基石
- CAP、BASE、最终一致性
- Indexing(索引)、Query(查询)
- MapReduce
- Sharding
三大基石-1
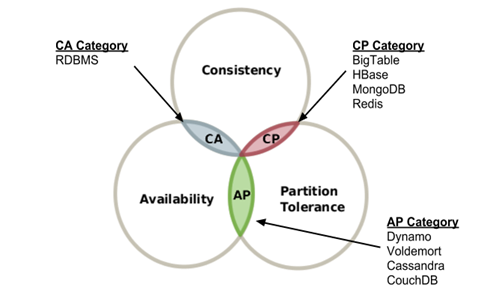
- CAP理论
- 数据库最多支持3个中的2个
- Consistency(一致性)
- Availability(可用性)
- Partition Tolerance(分区容错性)
- NoSQL不保证“ACID”
- 提供“最终一致性”
- 数据库最多支持3个中的2个
三大基石-2
- BASE
- Basically Availble(基本可用)
- 保证核心可用
- Soft-state(软状态)
- 状态可以有一段时间不同步
- Eventual Consistency(最终一致性)
- 系统经过一定时间后,数据最终能够达到一致的状态
- Basically Availble(基本可用)
- 核心思想是即使无法做到强一致性,但应用可以选择适合的方式达到最终一致性
三大基石-3
- 最终一致性
- 最终结果保持一致性,而不是时时一致
- 如账户余额,库存量等数据需强一致性
- 如catalog等信息不需要强一致性
- Causal consistency(因果一致性)
- Read-your-writes consistency
- Session consistency
假设有三个独立的Process A B C,
Causal consistency(因果一致性)
如果Process A通知Process B它已经更新了数据,那么Process B的后续读取操作则读取A写入的最新值,而与A没有因果关系的C则可以最终一致性。
Read-your-writes consistency
如果Process A写入了最新的值,那么Process A的后续操作都会读取到最新值。但是其它用户可能要过一会才可以看到。
Session consistency
此种一致性要求客户端和存储系统交互的整个会话阶段保证Read-your-writes consistency.Hibernate的session提供的一致性保证就属于此种一致性。
索引和查询
- Indexing(索引)
- 大多数NoSQL是按key进行索引
- 部分NoSQL允许二级索引
- HBase使用HDFS,append-only
- 批处理写入Logged
- 重新创建并排序文件
- Query(查询)
- 没有专门的查询语言,通常使用脚本语言查询
- 有些开始支持SQL查询
- 有些可以使用MapReduce代码查询
MapReduce、Sharding
- MapReduce
- 不是Hadoop的MapReduce,概念相关
- 可进行数据的处理查询
- Sharding(分片)
- 一种分区模式
- 可以复制分片
- 有利于灾难恢复
NoSQL分类
- 主要分为以下四类
| 键值存储数据库 (key-value) | Redis, MemcacheDB, Voldemort | 内容缓存等 |
|---|---|---|
| 列存储数据库 (WIDE COLUMN STORE) | Cassandra, HBase | 应对分布式存储的海量数据 |
| 文档型数据库 (DOCUMENT STORE) | CouchDB, MongoDB | Web应用(可看做键值数据库的升级版) |
| 图数据库 (GRAPH DB) | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等,专注于构建关系图谱 |
键值存储数据库(Key-Value)

列存储数据库(Wide Column Store)

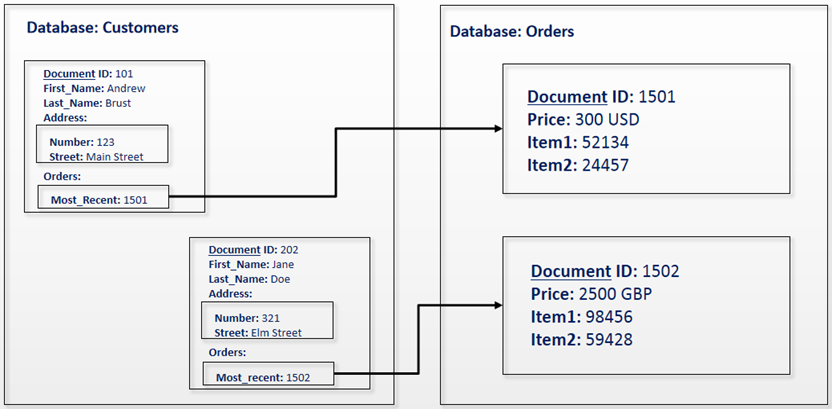
文档型数据库(Document Store)
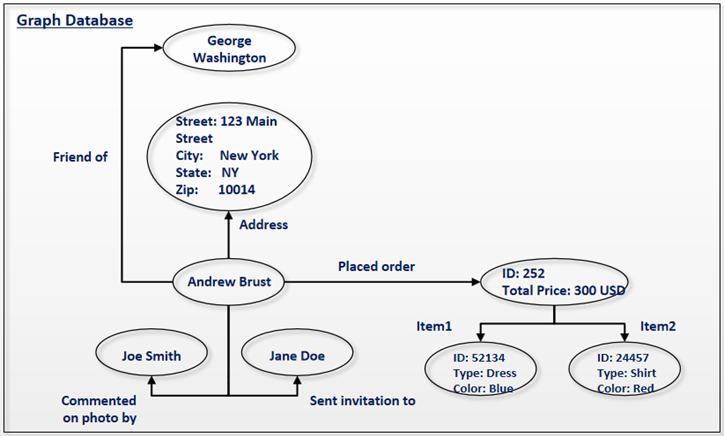
图数据库(Graph Databases)
NoSQL和BI、大数据的关系
- BI(Business Intelligence):商务智能
- 它是一套完整的解决方案
- BI应用涉及模型,模型依赖于模式
- BI主要支持标准SQL,对NoSQL支持弱于关系型数据库
- NoSQL和大数据相关性较高
- 通常大数据场景采用列存储数据库
- 如:HBase和Hadoop
HBase概述
- HBase是一个领先的NoSQL数据库
- 是一个面向列存储的数据库
- 是一个分布式hash map
- 基于Google Big Table论文
- 使用HDFS作为存储并利用其可靠性
- HBase特点
- 数据访问速度快,响应时间约2-20毫秒
- 支持随机读写,每个节点20k~100k+ ops/s
- 可扩展性,可扩展到20,000+节点
HBase发展历史
| 时间 | 事件 |
|---|---|
| 2006年 | Google发表了关于Big Table论文 |
| 2007年 | 第一个版本的HBase和Hadoop0.15.0一起发布 |
| 2008年 | HBase成为Hadoop的子项目 |
| 2010年 | HBase成为Apache顶级项目 |
| 2011年 | Cloudera基于HBase0.90.1推出CDH3 |
| 2012年 | HBase发布了0.94版本 |
| 2013-2014 | HBase先后发布了0.96版本/0.98版本 |
| 2015-2016 | HBase先后发布了1.0版本、1.1版本和1.2.4版本 |
| 2017年 | HBase发布1.3版本 |
| 2018年 | HBase先后发布了1.4版本和2.0版本 |
HBase用户群体

HBase应用场景-1
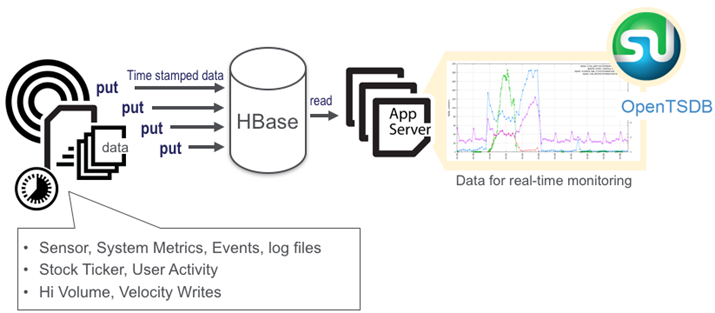
- 增量数据-时间序列数据
- 高容量,高速写入
HBase应用场景-2
- 信息交换-消息传递
- 高容量,高速读写

HBase应用场景-3
- 应用服务-Web后端应用程序
- 高容量,高速读写
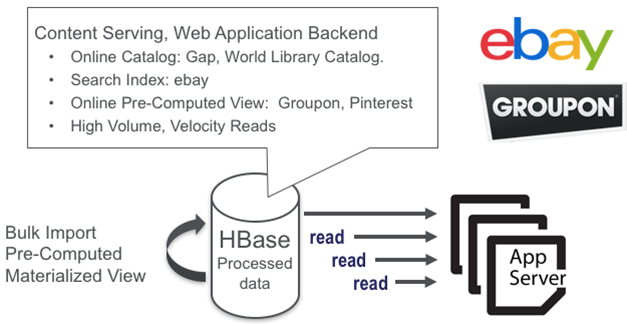
HBase应用场景示例
- Facebook
- 9000 memcached instances,4000 shards mysql
- 2011全部迁移到HBase
- Alibaba
- 自2010年以来,HBase一直为阿里搜索系统的核心存储
- 当前规模
- 3 个集群,每个有1000+ nodes
- 在Yarn上与Flink共享
- 每天提供超过10M+ ops/s 的服务
Apache HBase生态圈
- HBase生态圈技术
- Lily – 基于HBase的CRM
- OpenTSDB – HBase面向时间序列数据管理
- Kylin – HBase上的OLAP
- Phoenix – SQL操作HBase工具
- Splice Machine – 基于HBase的OLTP
- Apache Tephra – HBase事务支持
- TiDB – 分布式SQL DB
- Apache Omid - 优化事务管理
- Yarn application timeline server v.2 迁移到HBase
- Hive metadata存储可以迁移到HBase
- Ambari Metrics Server将使用HBase做数据存储
HBase物理架构-概述
- HBase采用Master/Slave架构
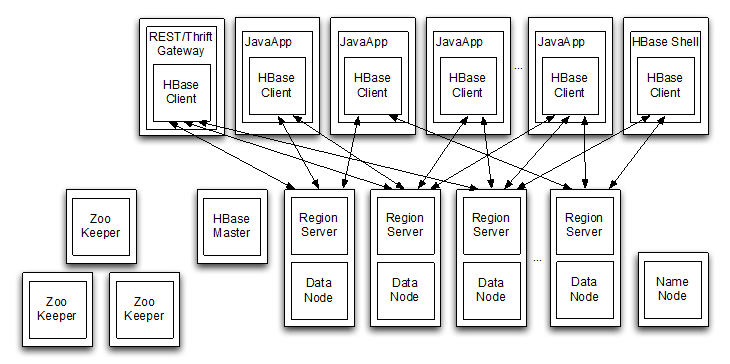
HBase物理架构 - HMaster
- HMaster的作用
- 是HBase集群的主节点,可以配置多个,用来实现HA
- 管理和分配Region
- 负责RegionServer的负载均衡
- 发现失效的RegionServer并重新分配其上的Region
HBase物理架构 - RegionServer
- RegionServer负责管理维护Region

HBase物理架构 - Region和Table
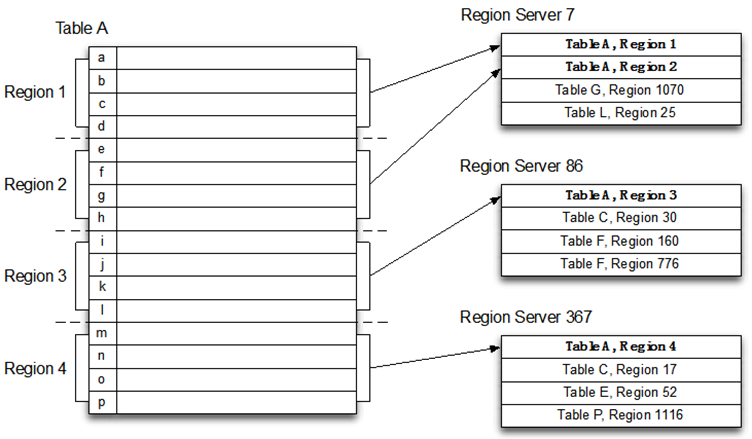
HBase逻辑架构 - Row
- Rowkey(行键)是唯一的并已排序
- Schema可以定义何时插入记录
- 每个Row都可以定义自己的列,即使其他Row不使用
- 相关列定义为列族
- 使用唯一时间戳维护多个Row版本
- 在不同版本中值类型可以不同
- HBase数据全部以字节存储

HBase数据管理
- 数据管理目录
- 系统目录表hbase:meta
- 存储元数据等
- HDFS目录中的文件
- Servers上的region实例
- 系统目录表hbase:meta
- HBase数据在HDFS上
- 可以通过HDFS进行修复File
- 修复路径
- RegionServer->Table->Region-
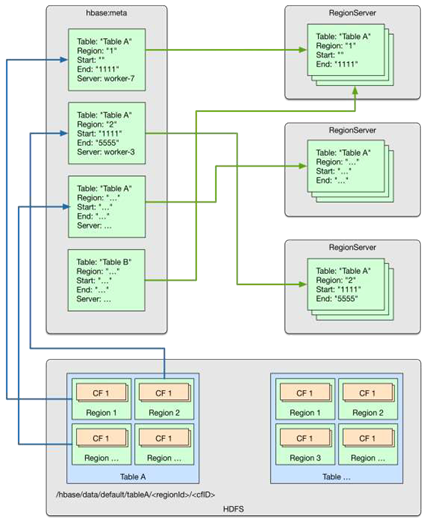
Hbase架构特点
- 强一致性
- 自动扩展
- 当Region变大会自动分割
- 使用HDFS扩展数据并管理空间
- 写恢复
- 使用WAL(Write Ahead Log)
- 与Hadoop集成
HBase Shell
- HBase Shell是一种操作HBase的交互模式
- 支持完整的HBase命令集
| 命令类别 | 命令 |
|---|---|
| General | version, status, whoami, help |
| DDL | alter, create, describe, disable, drop, enable, exists, is_disabled, is_enabled, list |
| DML | count, delete, deleteall, get, get_counter, incr, put, scan, truncate |
| Tools | assign, balance_switch, balancer, close_region, compact, flush, major_compact, move, split, unassign, zk_dump |
| Replication | add_peer, disable_peer, enable_peer, remove_peer, start_replication, stop_replication |
hbase基本命令:
用户权限:
user_permission ['表名'...]
grant '用户名','RWXCA'
表:
增:create '表名',{NAME=>'列簇名'},{NAME=>'列簇名'}...
删:disable '表名'----> drop '表名'
改:snapshot '表名','镜像名'
clone_snapshot '镜像名','新表名'
delete_snapshot '镜像名'
查:list
行:
put的时候:put '表名','行键','列簇名:列','值'[,时间戳]
可以单独删除行,行内的数据全部删除
列簇:
增:alter '表名',NAME=>'列簇名'
删:alter '表名',NAME=>'列簇名',METHOD=>'delete'
改:先加,后删
查:get '表名','行键','列簇名'
列:
cell:值+时间戳
批量导入文件:
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns="HBASE_ROW_KEY,emp:name,emp:job_title,emp:company,time:sDate,time:eDate" "emp_basic" /test/emp_basic.csv















 6371
6371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









