







2021.3.11 更新:
- 替换全部中文路径,解决某些情况下本地运行读取路径报错问题
- 将PaddleDetection挂载到数据集,解决git过慢问题
- 新增聚类生成初始anchor大小步骤
- 提供导出参数,可供大家直接部署使用
本文涉及内容
-
- 项目背景
-
- 数据集制作
-
- 模型训练与导出
-
- 模型部署
-
- 总结
1.项目背景

- gazebo作为一款功能强大且开源免费的仿真平台,对于疫情在家没有实物调试的大学生们来说,简直提供了完美的仿真环境去检验控制算法。刚好这段时间又开始研究智能车视觉导航,就针对其中锥桶检测整理出本项目,自制gazebo锥桶训练集,基于paddledetection完成训练最后导出模型,最终实现在gazebo仿真环境中的部署。帮助大家更好的在gazebo中检验各种算法
2.数据集制作
- 仿真环境的锥桶和真实世界锥桶还挺像的,但奈何没找到合适的以训练模型或者对应数据集,所以自己动手做了
- 图片是在gazebo环境中用手动方向键驱动仿真小车从各角度拍的锥桶视频,从视频中抽帧得到图片
- 标注采用的工具是开源的标注工具lableimg,标记后自动生成xml文件,符合VOC数据集读取格式。
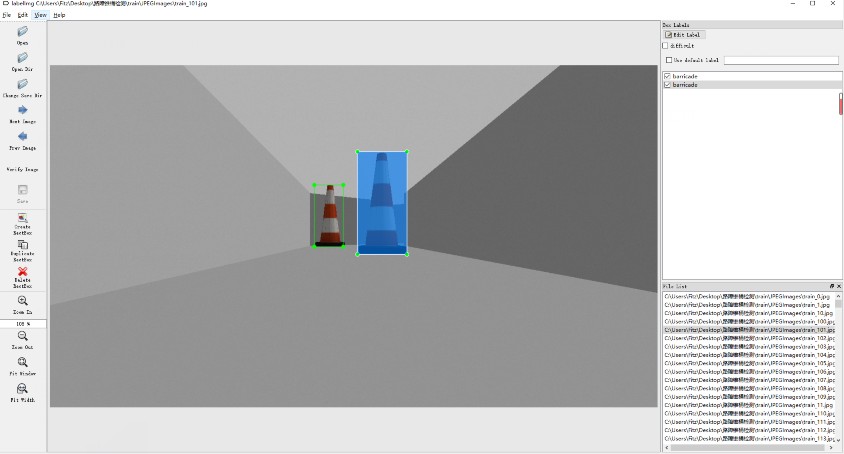
- 因为考虑到任务比较简单,最终从视频流中筛选出520张数据数据集
3.模型训练与导出
import os
import cv2
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
!unzip -o -q data/data43886/barricade.zip
print("done")
done
3.1 划分训练集和测试集
这里按照9:1划分了训练集和测试集并生成了对应的label_list.txt,同时要注意生成txt文件要符合PaddleDetection读取格式:
Img_Path/Img_name Xml_Path/Xml_name
!mkdir barricade/ImageSets
train = open('barricade/ImageSets/train.txt', 'w')
test = open('barricade/ImageSets/test.txt', 'w')
label_list = open('barricade/label_list.txt', 'w')
xml_path = "./Annotations/"
img_path = "./JPEGImages/"
count = 0
for xml_name in os.listdir('barricade/Annotations'):
data =img_path + xml_name[:-4] + ".jpg " + xml_path + xml_name + "\n"
if(count%10==0):
test.write(data)
else:
train.write(data)
count += 1
label_list.write("barricade")
train.close()
test.close()
label_list.close()
3.2 配置训练参数
PaddleDetection开发套件最方便的点就是不需要自己搭建复杂的模型,不仅可以快速进行迁移学习同时对训练中的参数也可以直接在yml环境文件中进行修改,简单方便易操作
具体步骤总结为:
-
- 点开PaddleDetection/configs目录,在其中挑选自己要用的模型
-
- 点开挑选好的模型yml文件,进行配置的修改,其中主要注意三点:
- —①数据集格式:PaddleDetecion支持读取的格式有VOC , COCO,wider_face和fruit四种数据集,对于初学者建议使用原本yml设置好的数据集格式使用
- —②数据集读取目录:将TrainReader,Testreder中数据集对应的文件,dataset_dir为数据集根目录,anno_path为3.1步中我们生成的txt文件。
- —③训练策略:主要改的几个参数是
| 名称 | 作用 |
|---|---|
| max_iters | 训练iter次数 |
| save_dir | 保存模型参数的路径 |
| snapshot_iter | 经过多少iter评估一次 |
| pretrain_weights | 预训练参数从哪里读取 |
| num_classes | 检测类别数,如果是双阶段检测模型得是分类数+1 |
| learning_rate | 学习率以及下面的PiecewiseDecay的milestones和warmup轮次设置 |
值得一提的是:
- 1.TestReader中也有anno_path,这个是设置推理时打出来的标签名的,是对应label_list.txt,是不是有同学在用PaddleDtection做infer的时候经常出现aeroplane这种莫名奇妙的标签,就是因为没有设置TestReader的anno_path导致的,这种情况中use_default_label也要都设成false哦
- 2.这里提到参数只是常用几个修改参数,更多yml参数作用看参考官方解释
因为本次检测任务目标种类单一、环境简单、特征明显,考虑到我们部署模型的时候还会运行其他ROS功能包,所以检测模型选择了轻量级的YOLOV3-MobilenetV1,对应的yml设置也附在了项目中
!unzip -o -q data/data73244/PaddleDetection-release-2.0-rc.zip
- 因为咱们使用的是YOLOV系列,也可以使用PaddleDetection提供的脚本在自己的数据集上实现聚类得到最佳初始anchor大小,并在yml中进行修改
!python PaddleDetection-release-2.0-rc/tools/anchor_cluster.py -c PaddleDetection-release-2.0-rc/configs/yolov3_mobilenet_v1_voc.yml -n 9 -s 416 -i 1666
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
/home/aistudio/PaddleDetection-release-2.0-rc/ppdet/utils/voc_utils.py:70: DeprecationWarning: invalid escape sequence \.
elif re.match('test\.txt', fname):
/home/aistudio/PaddleDetection-release-2.0-rc/ppdet/utils/voc_utils.py:68: DeprecationWarning: invalid escape sequence \.
if re.match('trainval\.txt', fname):
100%|██████████████████████████████████████| 468/468 [00:00<00:00, 48185.54it/s]
2021-03-11 17:27:26,108 - INFO - Running kmeans for 9 anchors on 713 points...
avg_iou: 0.9007: 0%| | 0/1666 [00:00<?, ?it/s]
2021-03-11 17:27:26,117 - INFO - 9 anchor cluster result: [w, h]
2021-03-11 17:27:26,117 - INFO - [22, 79]
2021-03-11 17:27:26,117 - INFO - [25, 84]
2021-03-11 17:27:26,117 - INFO - [27, 108]
2021-03-11 17:27:26,117 - INFO - [34, 124]
2021-03-11 17:27:26,117 - INFO - [39, 133]
2021-03-11 17:27:26,117 - INFO - [50, 172]
2021-03-11 17:27:26,117 - INFO - [80, 257]
2021-03-11 17:27:26,117 - INFO - [131, 303]
2021-03-11 17:27:26,118 - INFO - [195, 353]
3.3 开始训练
#训练
!python PaddleDetection-release-2.0-rc/tools/train.py -c PaddleDetection-release-2.0-rc/configs/yolov3_mobilenet_v1_voc.yml --eval --use_vdl=True --vdl_log_dir=vdl
3.4 导出模型
因为任务比较简单吼,训练几轮后指标都挺好的,测试集上mAP轻轻松松95+,我就直接导出了,PaddleDetection也提供导出工具
!python PaddleDetection-release-2.0-rc/tools/export_model.py -c PaddleDetection-release-2.0-rc/configs/yolov3_mobilenet_v1_voc.yml \
--output_dir=inference_model \
-o weights=output/yolov3_mobilenet_v1_voc/best_model
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
/home/aistudio/PaddleDetection-release-2.0-rc/ppdet/modeling/losses/yolo_loss.py:71: DeprecationWarning: The 'warn' method is deprecated, use 'warning' instead
"config YOLOv3Loss.batch_size is deprecated, "
2021-03-11 18:12:50,725 - WARNING - config YOLOv3Loss.batch_size is deprecated, training batch size should be set by TrainReader.batch_size
2021-03-11 18:12:52,820 - INFO - Load categories from barricade/label_list.txt
2021-03-11 18:12:52,823 - INFO - Export inference config file to inference_model/yolov3_mobilenet_v1_voc/infer_cfg.yml
2021-03-11 18:12:52,894 - INFO - save_inference_model pruned unused feed variables im_id
2021-03-11 18:12:52,894 - INFO - Export inference model to inference_model/yolov3_mobilenet_v1_voc, input: ['image', 'im_size'], output: ['multiclass_nms_0.tmp_0']...
运行之后就会在设置的inference_model目录下生成我们的部署文件,一共有三个:model、params和infer_cfg.yml,有这三个文件我们就可以开始部署了。
4.模型部署
- 以上步骤咱们使用的是飞浆核心框架PaddlePaddle,这完成是模型的训练,大家知道训练过程中涉及反向传播是有很多参数的,而这些参数在实际使用正向推导时是没有用的,这也是3.4步导出模型的意义,把反向传播的一些参数全部去掉,只保留核心的推导参数,降低参数的,这样剩下的参数就全是对正向推导有用的了。
- 对于推理部署,飞浆提供了两种方法PaddleLite和Paddle Inference。两种推理工具在我使用下来感觉:Paddle Lite主要针对移动端,而Paddle Inference是针对服务器端、云端和无法使用Paddle Lite的嵌入式设备,两者都提供高性能推理引擎,这次咱们部署环境是x86 Linux,所以就采用Paddle Inference实现
4.1 Paddle Inference 2.0
- Paddle Inference是飞浆原生推理库,原生就意味Paddle能实现的op,Paddle Inference不需要通过任何类型转换就可以实现,同时提供C、C++、Python的预测API,为了能让大家理解的更方便,这里就选择使用Python API进行推理,也可以直接在AI Studio上直接运行
4.2 Paddle Inference安装
- 咱们部署环境是X86的Linux可以直接参考官网步骤安装Paddle调用Paddle Inference进行推理
- 本项目推理部署采用的Paddle Inference 2.0,请正确安装版本
4.3 Paddle Inference推理步骤
import cv2
import numpy as np
from paddle.inference import Config
from paddle.inference import create_predictor
4.3.1 配置Config
- PaddleInferen推理核心是创建推理引擎predictor,在创建前要配置Config
- Config类是所有属性配置,属性在Config实例化配置好后装载到predictor中,其方法全部是配置属性的,具体主要常用方法总结如下:
- set_model(“model”,“params”):读取模型和参数
- enable_use_gpu(memory,gpu_id):设置是否使用GPU,使用GPU分配的内存和使用的GPU的ID号
- enable_tensorrt_engine():开启tensorrt加速
- enable_mkldnn():开启MKLDNN
- 因为使用显卡跑虚拟机里的Gazebo会卡机,所以我的虚拟机环境是不加载显卡,对应推理时也是使用CPU推理,这也是为啥模型选MobilenetV1了哈哈哈
config = Config()
config.set_model("inference_model/yolov3_mobilenet_v1_voc/__model__","inference_model/yolov3_mobilenet_v1_voc/__params__")
config.disable_gpu()
config.enable_mkldnn()
4.3.2 创建Predictor
- 使用create_predictor(config)用于创建Predictor类
- Predictor类是推理引擎,其方法全是正向推理运行的
predictor = create_predictor(config)
4.3.3 配置推理引擎
- 创建推理引擎predictor之后我们要手动对其输入进行设置
4.3.3.1 查看输入格式
- 我们先手动调出,看看他的输入应该是啥
#获取推理引擎的输入的名字
input_names = predictor.get_input_names()
print(len(input_names))
#查看输入的两个变量属性
input_tensor_0 = predictor.get_input_handle(input_names[0])
input_tensor_1 = predictor.get_input_handle(input_names[1])
#可见都是输入的handle都是tensor类的变量
print(input_names)
print(input_tensor_0)
print(input_tensor_1)
2
['image', 'im_size']
<paddle.fluid.core_avx.PaddleInferTensor object at 0x7fee7c1ecab0>
<paddle.fluid.core_avx.PaddleInferTensor object at 0x7fee7c1eccb0>
- 可以看到上方cell的显示,推理引擎的输入格式应该是 : [图片,图片的大小] ,这就是我们等会向predictor内加载信息时的格式
4.3.3.2 图像预处理
- 知道输入格式,那咱们按格式读一张图片进去,看看输出是啥样
- 但在此前还得按照模型要求完成输入图像的预处理,对应预处理操作可以在导出的yml文件中查看
img = cv2.imread("test.jpg")
def preprocess(img , Size):
img = cv2.resize(img,(Size,Size),0,0)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = img / 255.0
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
img -= mean
img /= std
img = img.astype("float32").transpose(2,0,1)
img = img[np.newaxis,::]
return img
image = preprocess(img,416)
4.3.3.3 查看输出
- 看看输出是啥样
im_shape = np.array([416, 416]).reshape((1, 2)).astype(np.int32)
img = [image,im_shape]
for i,name in enumerate(input_names):
#定义输入的tensor
input_tensor = predictor.get_input_handle(name)
#确定输入tensor的大小
input_tensor.reshape(img[i].shape)
#对应的数据读进去
input_tensor.copy_from_cpu(img[i].copy())
# 运行predictor
predictor.run()
# 获取输出
output_names = predictor.get_output_names()
print(output_names)
results = []
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
print(output_data)
['save_infer_model/scale_0.tmp_0']
[[0.00000000e+00 4.25863624e-01 2.03892258e+02 1.01716118e+02
2.61180664e+02 2.33477722e+02]
[0.00000000e+00 9.27145109e-02 2.15066772e+02 1.11449356e+02
2.43748352e+02 1.95806931e+02]
[0.00000000e+00 7.39767328e-02 2.01971436e+02 1.57187057e+02
2.63916443e+02 2.11278336e+02]
[0.00000000e+00 1.74350999e-02 2.16398804e+02 1.34368530e+02
2.50863831e+02 2.27454163e+02]
[0.00000000e+00 1.18300365e-02 2.07281219e+02 6.60237885e+01
2.33852631e+02 2.59419739e+02]
[0.00000000e+00 1.08919265e-02 1.98264145e+02 1.29647232e+02
2.91898315e+02 2.02846115e+02]]
- 可以看到输出是 类别+置信度+x1+y1+x2+y2的格式,这样就可对其进行操作了
4.4 完整推理
- 完整程序也可在predict.py中查看
import cv2
import numpy as np
from paddle.inference import Config
from paddle.inference import create_predictor
def preprocess(img , Size):
img = cv2.resize(img,(Size,Size),0,0)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = img / 255.0
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
img -= mean
img /= std
img = img.astype("float32").transpose(2,0,1)
img = img[np.newaxis,::]
return img
def predicte(img,predictor):
input_names = predictor.get_input_names()
for i,name in enumerate(input_names):
#定义输入的tensor
input_tensor = predictor.get_input_handle(name)
#确定输入tensor的大小
input_tensor.reshape(img[i].shape)
#对应的数据读进去
input_tensor.copy_from_cpu(img[i].copy())
#开始预测
predictor.run()
#开始看结果
results =[]
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
if __name__ == '__main__':
#读入的摄像头信息根据大家自己ROS结点自己读入咯,这里我就直接用摄像头读取替代了,大家到时候这里自己更换进行
cap = cv2.VideoCapture(1)
config = Config()
config.set_model("inference_model/yolov3_mobilenet_v1_voc/__model__","inference_model/yolov3_mobilenet_v1_voc/__params__")
config.disable_gpu()
config.enable_mkldnn()
predictor = create_predictor(config)
im_size = 416
im_shape = np.array([416, 416]).reshape((1, 2)).astype(np.int32)
while(1):
success, img = cap.read()
if (success == False):
break
img = cv2.resize(img, (im_size,im_size),0, 0)
data = preprocess(img, im_size)
results = trash_detect(trash_detector, [data, im_shape])
for res in results[0]:
img = cv2.rectangle(img, (int(res[2]), int(res[3])), (int(res[4]), int(res[5])), (255, 0, 0), 2)
cv2.imshow("img", img)
cv2.waitKey(10)
, (int(res[2]), int(res[3])), (int(res[4]), int(res[5])), (255, 0, 0), 2)
cv2.imshow("img", img)
cv2.waitKey(10)
cap.release()
- 实际部署推理结果:

总结
- Gazebo环境中摄像头的ROS结点名因人而异,故predict.py脚本中需要大家自己更改读入的视频数据
- 后续的路径规划算法和Paddle无关,这里就不做太多叙述了,有兴趣的伙伴可以一起来讨论哇
- 本项目使用Paddle2.0完整展示了从数据集制作、模型选取、模型训练、模型导出以及模型部署的全流程实践,希望能帮助启发到大家
关于作者
-
姓名:Fitz
-
武汉理工大学信息工程专业2018级本科在读
-
感兴趣方向:计算机视觉、推理部署、迁移学习
-
AIstudio主页 : Fitzie
-
欢迎大家有问题一起交流讨论,共同进步~
运行代码请点击:https://aistudio.baidu.com/aistudio/projectdetail/1608121
运行方式如下:
















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









