







不知道有没有小伙伴遇到过这样的情况:有时候使用Pytorch训练完模型,在测试数据上面得到的结果并不尽如人意。到底是什么原因导致pytorch训练结果不准确的呢?阅读这篇文章,你或许会找到答案。
当我们遇到训练结果不准确的情况的时候,可能需要检查一下定义的Model类中有没有 BN 或 Dropout 层,如果有任何一个存在
那么在测试之前需要加入一行代码:
#model是实例化的模型对象
model = model.eval()表示将模型转变为evaluation(测试)模式,这样就可以排除BN和Dropout对测试的干扰。
因为BN和Dropout在训练和测试时是不同的:
对于BN,训练时通常采用mini-batch,所以每一批中的mean和std大致是相同的;而测试阶段往往是单个图像的输入,不存在mini-batch的概念。所以将model改为eval模式后,BN的参数固定,并采用之前训练好的全局的mean和std;
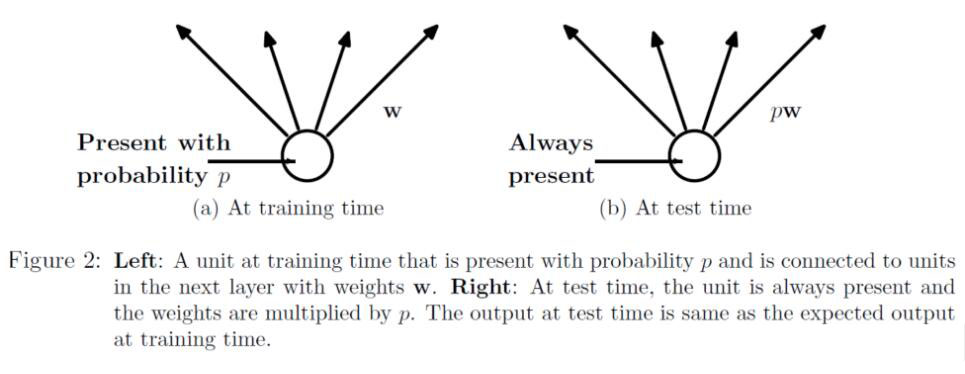
对于Dropout,训练阶段,隐含层神经元先乘概率P,再进行激活;而测试阶段,神经元先激活,每个隐含层神经元的输出再乘概率P。
如下图所示:
补充:pytorch中model.eval之后是否还需要model.train的问题
答案是:需要的
正确的写法是

for循环之后再开启train,
循环之后的评估model.eval之后就会再次回到model.train。
















 3487
3487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











