







接下来将以爬虫的步骤顺序,实战的角度,介绍爬虫所要了解的基础知识。
以爬取 新浪 新闻网页项目为例
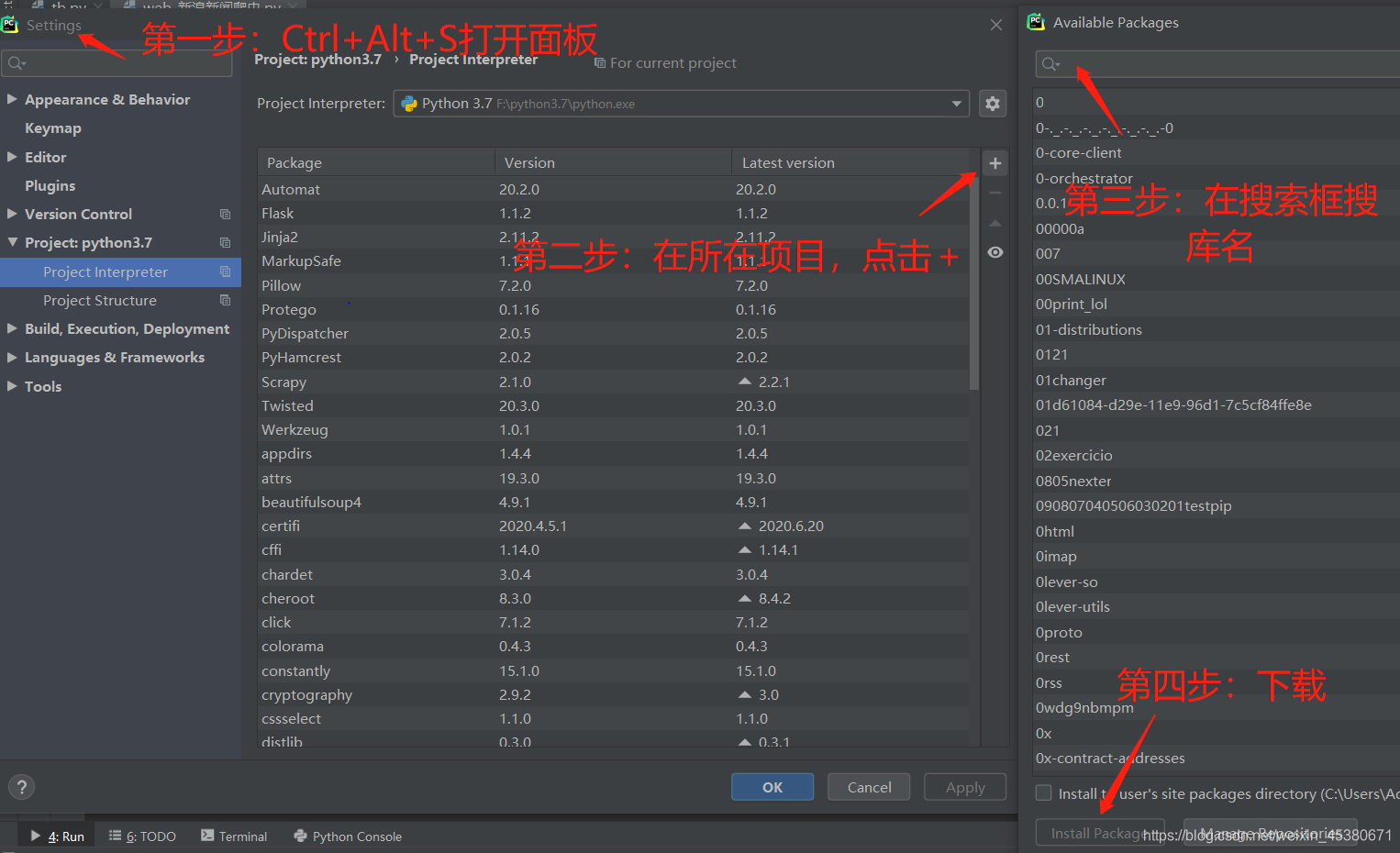
环境准备
pycharm下导入requests等库
爬虫三步走
爬虫第一步
① 发送请求,返回响应。
可以使用 get命令发送访问请求,再返回网页代码。
import requests #导入requests库
#获取url的html文件
def getHTMLText(url):
try:
r = requests.get(url) # url就是网页链接
r.encoding = r.apparent_encoding # 自动分析网页内容编码方式
return r.text # 返回网页的HTML文件代码
except:
return '请求失败'
爬虫第二步
② 解析网页,提取数据。
首先,我使用Google Chrome浏览器,按 F12 打开“开发者工具”,观察网页代码:

我们可以通过多次点击不同url连接,分析链接所在的标签情况,总结规律。
分析得出链接都处于<div class=‘main-content’ 标签下,并且链接都位于’a’标签 ,由此,我们可以得出以下代码:
#解析网页,提取数据
def parsePage(html, list):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5061
5061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









