







本案例独立完成,没有参考任何资料。虽说不是什么高难度的JS逆向,但对新手来说还是有点难度的。话不多说,开始正题。本次破解的目标是音乐网站的歌曲下载。
目标网站:
未免侵权,此处省略。需要的私我。
基本思路:
搜索歌曲名字,获得歌曲地址,完成下载。
逆向过程:
1、搜索歌曲,通过手动观察和查找,不难在Network下的JS面板下找到目标请求信息。
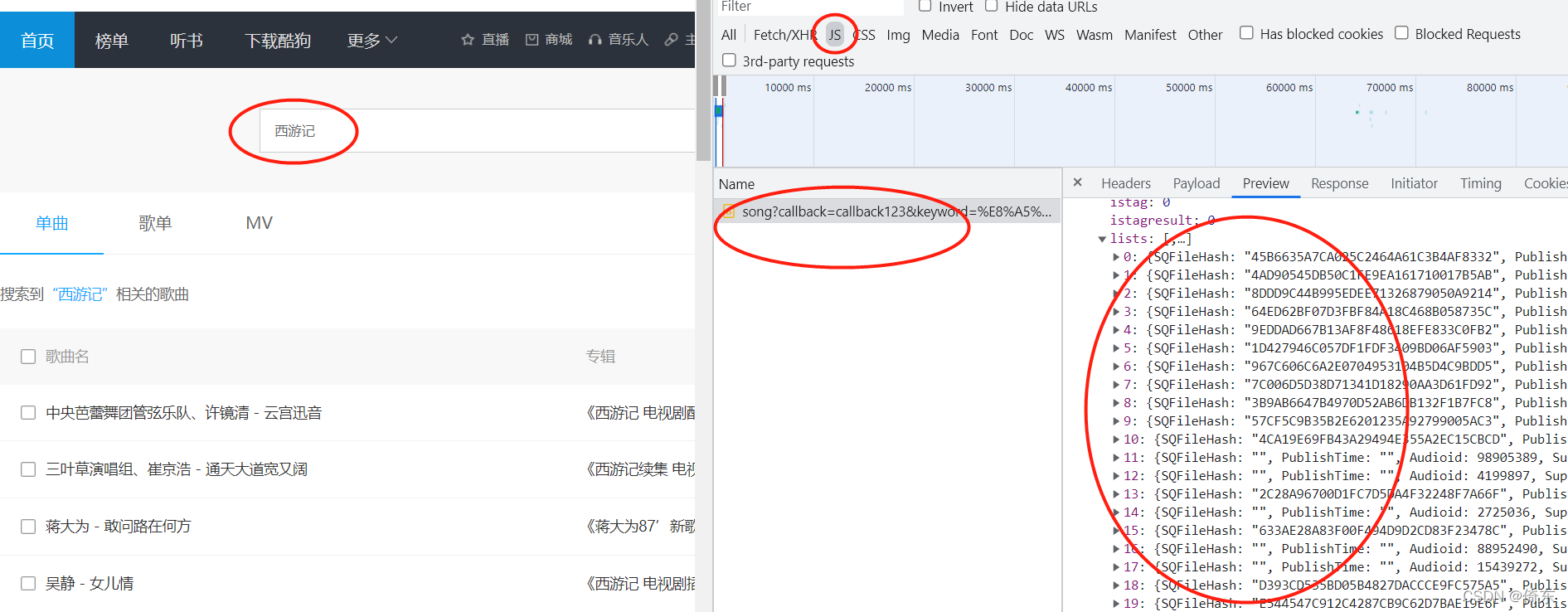
2、我们来看一下这个请求的具体信息:
Headers:

Playload:看得出来有很多参数,一个截图都放不下。

3、找到加密参数。通过搜索不同的歌曲名字,比较请求信息,可以看出每次请求中有变化的参数是keyword和signature,还有clienttime,mid,uuid共5个参数。其中后三个很显然是时间戳,keyword是搜索的歌曲名字。所以最关键的参数就是signature。接下去要做的就是找到该参数的生成原理。
4、在开发者状态下,点击search,输入signature.
,结果只有一个,双击打开,再点击美化打印。
就能看到如下界面:
5、来看这行的代码:
h.signature = faultylabs.MD5(o.join("")),
原来signature参数就是一个函数(faultylabs.MD5)带一个参数(o.join(""))生成的。
从函数名称就知道,该函数是把字符串做md5加密,并返回大写的字母。
如果看不出来,也可以这抠代码。
打上断点,刷新,鼠标移至MD5,系统提示这个函数就是anonymous(a)。
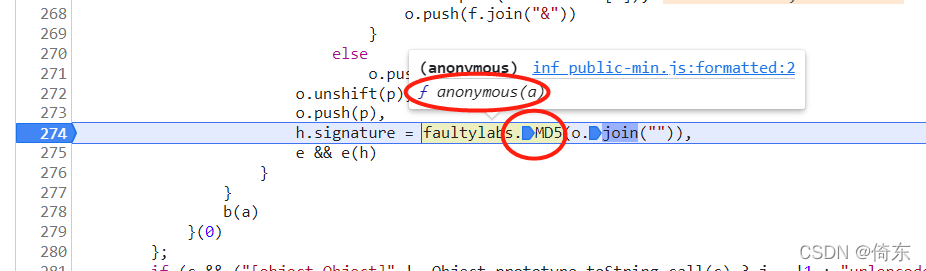
点击该函数,显示如下界面:
函数很长,末尾是这样的,

把整个函数抠出来做成一个新的js文件,然后任一字符串参数测试下这个函数的作用,结果是一长
串数字和大写字母。![]()
和直接用python的md5加密hashlib.md5(string.encode(encoding='utf-8')).hexdigest()结果是一样的。
6、现在就剩下参数,就是o.join("")的生成原理了。很显然,就是将列表o的字符串进行拼接。
那么列表o哪里来的? 我们在join前面的小框勾选上,再执行 :

到这里的时候,我们在Console面板看下o的结果,输入o,得到:

这个o的值是否很熟悉?没错就是,把请求参数字典的键值对用“=”拼接,作为列表的元素。然后再列表前后加入固定字符串'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt'
注意这里是部分参数,并且按照一定的顺序!这里是个坑。
到此,所有的加密原理已经搞定。
那么,是否完成载?还没有!别高兴得太早!我们只是搞定了请求,能获得如下结果:

7、 那么如何根据这些结果能够获得音乐的下载链接呢?
回到最初的搜过结果,点击任一结果,弹出的窗口地址如下,形如https://www.kugou.com/song/#hash={filehash}&album_id={album_id}

只要拿到filehash和albumid两个参数就可以构造音乐请求的地址,而这两个参数都已经获取了。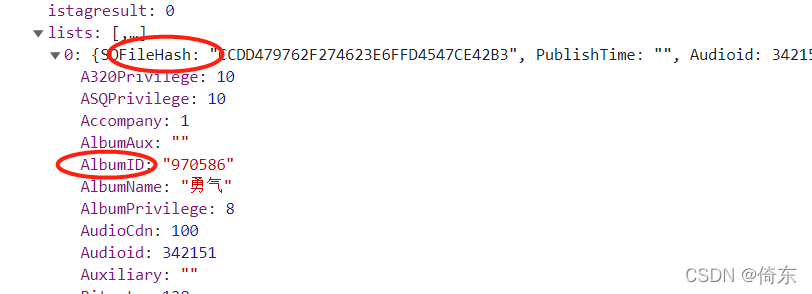
8、下一步是获取歌曲链接地址。进入音乐播放窗口,点右键,点检查,查看网页源码。
搜索mp3,结果如下: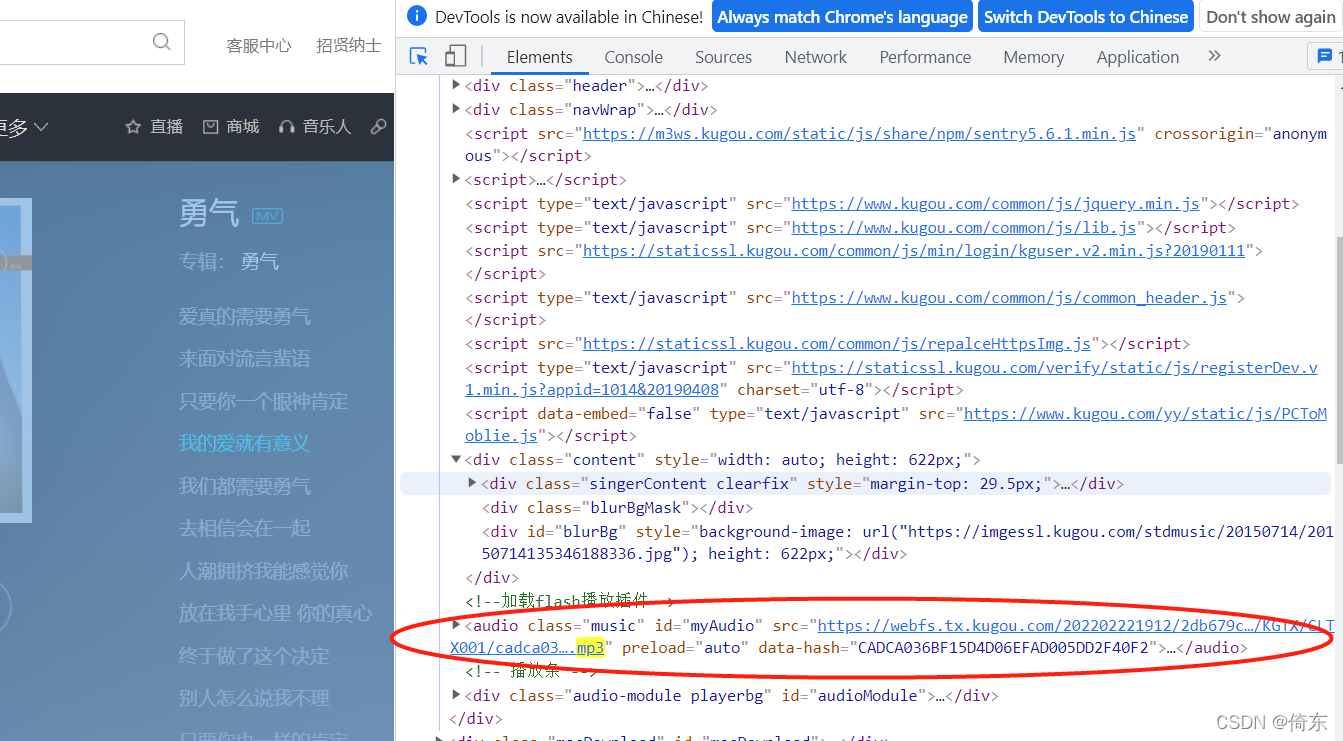
可是 根据上述的歌曲播放地址构造请求,发现结果里面没有mp3文件。判断是用了动态渲染技术,所以想到selenium请求获取歌曲地址,然后就可以通过requests请求下载了。
至此,整个音乐下载的过程都完成了。上完整代码如下:
'''
construct rquests address, then get '.mp3' address in the response. then download by requests it.
'''
import requests,pprint,re,json,time,hashlib
from selenium import webdriver
# from selenium.webdriver.chrome.options import Options
headers = {
'authority': 'complexsearch.kugou.com',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"',
'sec-ch-ua-mobile': '?0',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
'accept': '*/*',
'sec-fetch-site': 'same-site',
'sec-fetch-mode': 'no-cors',
'sec-fetch-dest': 'script',
'referer': 'https://www.kugou.com/',
'accept-language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'cookie': 'kg_mid=1a8bf97ec26db1b38258848ec815e0a4',
}
def get_sign(params):
'''
return 'signature' parameter to be used in requests.
Param: a dict of requests paramter
'''
string=''
for i in params:
temp=i+'='+params[i]
string+=temp
# print(string)
string='NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt'+string+'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt' #add a string before and after the string
return hashlib.md5(string.encode(encoding='utf-8')).hexdigest().upper() #md5 encrpted,then capitilized.
def search_music(song_name):
'''
return a list of all searching results.
'''
search_results=[]
params = {'bitrate':'0',
'callback': 'callback123',
'clienttime':str(int(time.time()*1000)),
'clientver':'2000',
'dfid':'-',
'inputtype':'0',
'iscorrection':'1',
'isfuzzy':'0',
'keyword': song_name,
'mid':str(int(time.time()*1000)),
'page': '1',
'pagesize': '30',
'platform':'WebFilter',
'privilege_filter':'0',
'srcappid':'2919',
'tag':'em',
'token':'',
'userid':'0',
'uuid':str(int(time.time()*1000)),
}
params['signature']=get_sign(params)
# print(params['signature'])
# print(params)
response = requests.get('https://complexsearch.kugou.com/v2/search/song', headers=headers, params=params)
# print(response.status_code)
text=response.text[12:-2]
search_data=json.loads(text)['data']['lists']
# pprint.pprint(search_results)
# print(len(search_results))
for i in search_data:
# print(i)
music_list={}
music_list['FileName']=i['FileName'].replace('<em>','').replace('</em>','')
music_list['FileHash']=i['FileHash']
music_list['AlbumID']=i['AlbumID']
print(music_list['FileName'])
# print(i['FileName'].replace('<em>','').replace('</em>',''),i['FileHash'],i['AlbumID'])
search_results.append(music_list)
# print(search_results)
return search_results
def get_song_address(search_results):
filehash=search_results[0]['FileHash']
album_id=search_results[0]['AlbumID']
url=f'https://www.kugou.com/song/#hash={filehash}&album_id={album_id}'
# print(url)
options=webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"')
options.add_argument('--headless')
options.add_experimental_option('excludeSwitches', ['enable-logging']) #remove all annoying reminder like DevTools listening on ws://127.0.0.1:51589/devtools/browse
driver=webdriver.Chrome(options=options)
# driver=webdriver.PhantomJS() #no working
driver.get(url)
time.sleep(1)
# html=driver.page_source
# print(type(html))
music_address=driver.find_element_by_id('myAudio').get_attribute('src')
driver.close()
print(music_address)
return music_address
def get_song(music_address):
with open('D:\\kugoumusic\\'+song_name+'.mp3','wb') as file: #downloading songs
res=requests.get(music_address,headers=headers)
file.write(res.content)
if __name__=='__main__':
song_name=input('请输入要下载的歌名:')
print(f'开始搜索: {song_name} 请耐心等待!')
search_results=search_music(song_name)
print(f'正在抓取歌曲地址:')
music_address=get_song_address(search_results)
get_song(music_address)
print(song_name,"下载完成!")
总结:
1、要有足够的耐心阅读JS代码,找到参与的生成原理。
2、实际破解过程并非上述过程。
其实是这样的:
a.先搜索歌名,点击其中一个搜索结果,打开窗口播放歌曲,找到歌曲下载地址。
b.找到后,发现地址很请求地址完全没有联系,至少我没看出来。并且请求结果是没有歌曲地址的。于是想到selenium请求。
c.那问题是请求地址如何构造?从如下歌曲播放的窗口地址可以看出来,只需要filehash和albumid。https://www.kugou.com/song/#hash=CADCA036BF15D4D06EFAD005DD2F40F2&album_id=970586
这两个参数都可以从歌曲搜索的结果里找到。
d.所以问题转化为如何完成搜索?也就是如何通过生成加参数,然后构造请求获得搜索结果。这就是本文开始一大半篇幅的内容所在。














 5449
5449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









