







K-Means中K值的选择
K-Means是一个很简单的聚类方法,说它简单,主要原因是使用它时只需设置一个K值(设置需要将数据聚成几类)。但问题是,有时候我们拿到的数据根本不知道要分为几类,对于二维的数据,我们还能通过肉眼观察法进行确定,超过二维的数据怎么办?今天就一起来学习下。
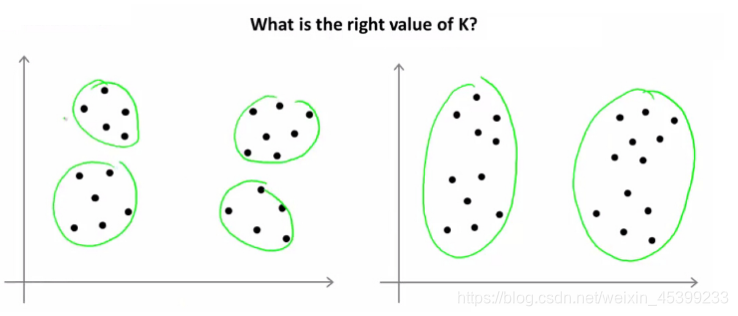
(1)拍脑袋法
一个非常快速的,拍脑袋的方法是将样本量除以2再开方出来的值作为K值,具体公式为:

(2)肘部法则(Elbow Method)
Elbow Method :Elbow意思是手肘,如下图左所示,此种方法适用于 K 值相对较小的情况,当选择的k值小于真正的时,k每增加1,cost值就会大幅的减小;当选择的k值大于真正的K时, k每增加1,cost值的变化就不会那么明显。这样,正确的k值就会在这个转折点,类似elbow的地方。 如下图:
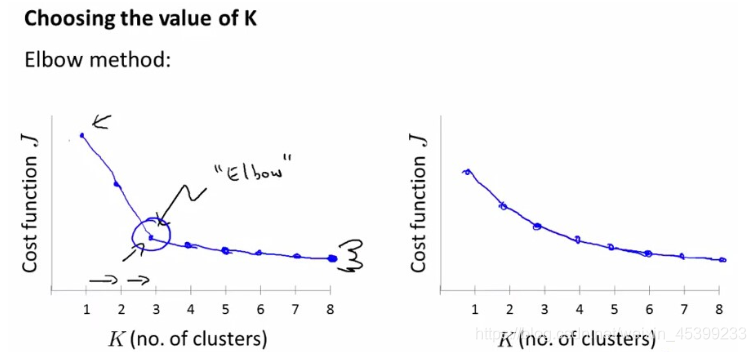
通过画K与cost function的关系曲线图,如左图所示,肘部的值(cost function开始时下降很快,在肘部开始平缓了)做为K值,K=3。并不是所有的问题都可以通过画肘部图来解决,有的问题如右边的那个图,肘点位置不明显(肘点可以是3,4,5),这时就无法确定K值了。故肘部图是可以尝试的一种方法,但是并不是对所有的问题都能画出如左边那么好的图来确定K值。
Elbow Method公式:
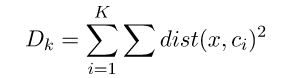
Python实现:
# clustering dataset
# determine k using elbow method
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
import numpy as np
import matplotlib.pyplot as plt
x1 = np.array([3, 1, 1, 2, 1, 6, 6, 6, 5, 6, 7, 8, 9, 8, 9, 9, 8])
x2 = np.array([5, 4, 5, 6, 5, 8, 6, 7, 6, 7, 1, 2, 1, 2, 3, 2, 3])
plt.plot()
plt.xlim([0, 10])
plt.ylim([0, 10])
plt.title('Dataset')
plt.scatter(x1, x2)
plt.show()
# create new plot and data
plt.plot()
X = np.array(list(zip(x1, x2))).reshape(len(x1), 2)
colors = ['b', 'g', 'r']
markers = ['o', 'v', 's']
# k means determine k
distortions = []
K = range(1, 10)
for k in K:
kmeanModel = KMeans(n_clusters=k).fit(X)
kmeanModel.fit(X)
distortions.append(sum(np.min(cdist(X, kmeanModel.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0])
# Plot the elbow
plt.plot(K, distortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Distortion')
plt.title('The Elbow Method showing the optimal k')
plt.show()
(3)间隔统计量(Gap Statistic)
根据肘部法则选择最合适的K值有时并不是那么清晰,因此斯坦福大学的Robert等教授提出了Gap Statistic方法。
Gap Statistic的定义为:
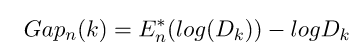
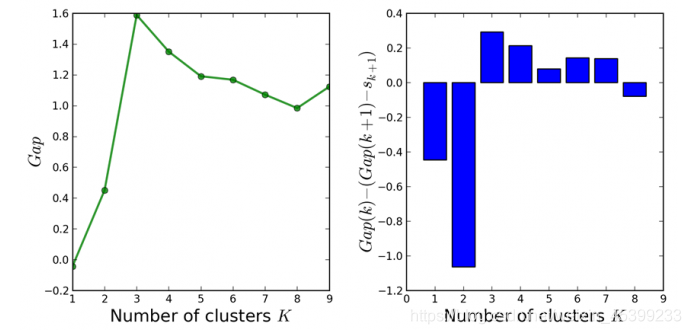
这里E(logDk)指的是logDk的期望。这个数值通常通过蒙特卡洛模拟产生,我们在样本里所在的矩形区域中(高维的话就是立方体区域)按照均匀分布随机地产生和原始样本数一样多的随机样本,并对这个随机样本做K-Means,从而得到一个Dk。如此往复多次,通常20次,我们可以得到20个log Dk。对这20个数值求平均值,就得到了E(logDk)的近似值。最终可以计算Gap Statisitc。而Gap statistic取得最大值所对应的K就是最佳的K。
Gap Statistic的基本思路是:引入参考的测值,这个参考值可以有Monte Carlo采样的方法获得。
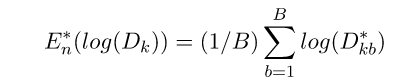
B是sampling的次数。为了修正MC带来的误差,我们计算sk也即标准差来矫正Gap Statistic。
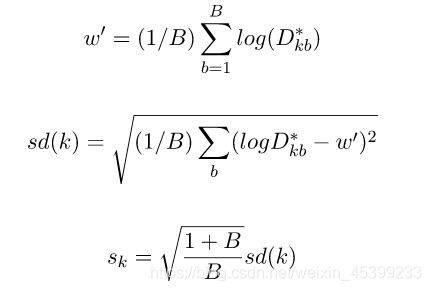
选择满足
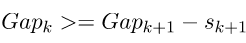
的最小的k作为最优的聚类个数。下图阐释了Gap Statistic的过程。
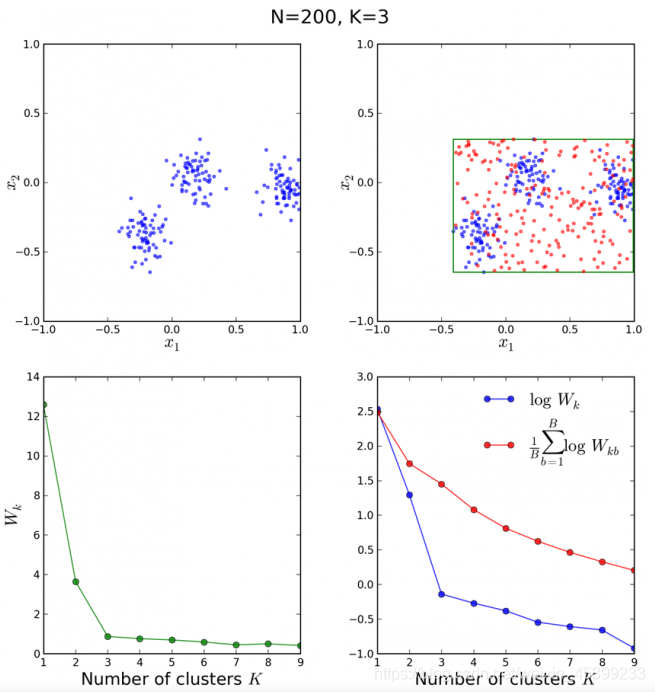
Python实现:
import scipy
from scipy 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6558
6558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











