







欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术感兴趣的同学加入。我的博客写一些自己用得到东西,并分享给大家,如果有问题欢迎留言与我讨论:)
Kmeans聚类方法是(我认为)最广泛使用以及稳定、有效的聚类方法。聚类是无监督学习方法,不需要对数据本身的标签有任何了解。如果你不是很理解kmeans算法本身,建议随便找一本数据挖掘/机器学习的书来看一看,或者看下baidu[1]的内容基本就能理解。
Kmeans算法基本描述
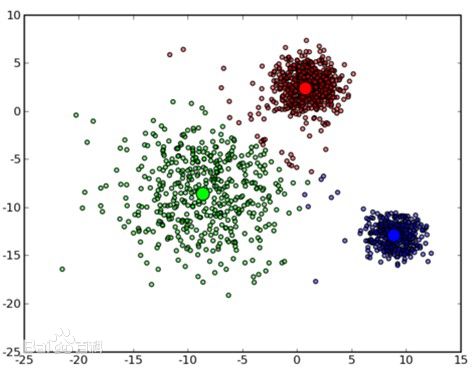
基本算法这里只做最为简单的描述,供读者理解,下图是一个聚类后的示意图。
(1) 从 n个数据对象任意选择 k 个对象作为初始聚类中心点;
(2) 根据每个聚类对象的均值(中心点),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心点)
(4) 循环(2)到(3)直到每个聚类不再发生变化为止
用Parametric Bootstrap方法确定K的取值
我们知道,在实际应用中,我们并不知道数据应该被聚类成几类(K=?),因为数据往往是高维的且交杂在一起。如何确定一个好的K,本身是一个值得研究的课题,也有不少人提出过不少方法,在本文中,我具体描述一下用Parametric Bootstrap方法来确定K值,主要参考的是[2],看下来感觉方法简单实用,在这里用自己的话描述一遍,并做适当衍生。
假设下图是我们的数据样本集合(每一个点表示一个样本),打印在二维平面上:
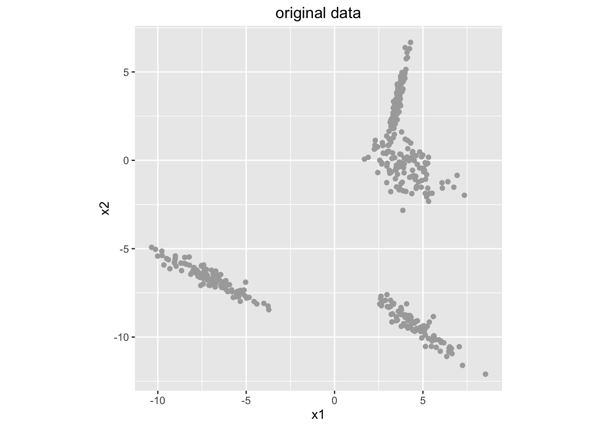
首先,我们并不知道数据应该聚成几类(实际中我们是不太可能看得到高维数据有很明显的分割的。在这个例子中乍一看好像是3类,但是实际上,我们的数据是通过4个混合高斯分布生成的。),所以假设数据应该分成k=2类,结果是:
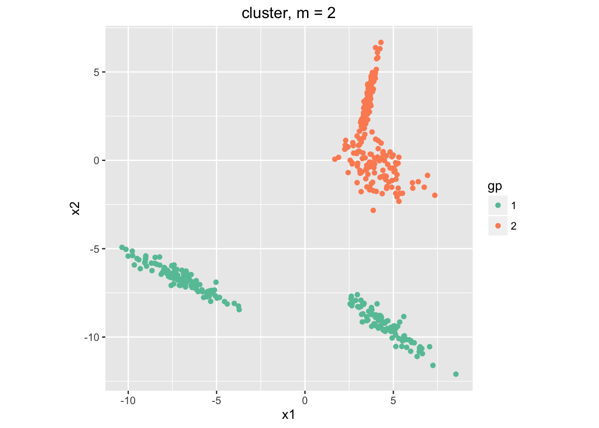
这样,我们通过kmeans(k=2)把数据分为两类——橘
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3133
3133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









