







kafka性能指南
1.绪论
首先是epoll模型,epoll使其在框架上得以使用mmp和回写高性能。
epoll模型具体可以看linuxIO那一个笔记,这里简单讲一下
首先是epoll模型,模型要求有一组fd由单独线程监控,然后app去干别的事,当fd有变动时,守护线程通知app来处理。这样可以使app持续工作,提高资源使用率。
mmp就是那个单独维护fd链表地址。是在内存中的一块区域,可以在此进行数据修改,到达条件后回写到硬盘。因为是cpu直接操纵内存,所以效率快很多。
同时在kafka产生的文件里,所有的logs等文件时stage类型。该类型文件在磁盘上是顺序读写的,读写速度接近内存。
2.读写部分
2.1顺序读写
因为随机存储需要很长的寻址时间,顺序读写则省去了寻址的时间。
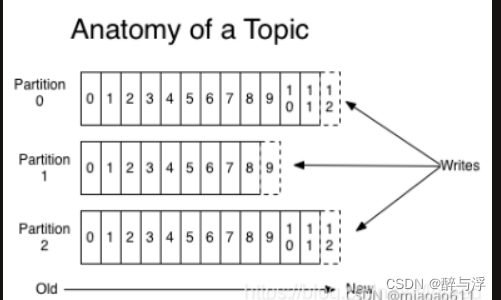
每次新文件都是直接追加到原始文件后端。每个partition都是文件。
这样的弊端是没法删除文件,所以kafka没法删除文件,所有的信息都会保存下来。
每个消费者对每个topic都会有一个offset表示读到了第几条数据。

一般情况offset的信息会存储到zookeeper里
2.2 MemoryMappedFiles
这就是回写,一种设计模式,比如把硬盘的文件映射到内存。cpu直接操作内存,最后回写回硬盘。
mmap就是这个思想的具体实现之一。
mmap是一个特殊的内存空间,在内核层和用户层之间。用户层可以直接操作该空间,所有不涉及到普通切换空间涉及到的四次传递文件,以及大量的contexet转换。因为kafka可以直接操作该地址。
缺点是不可靠,因为在数据flush到硬盘之前,数据都是记载在内存上的。
kafka提供了producer.type来控制flush的时机。
sync是同步,数据写道mmap时立即flush然后通知producer
async时异步,数据写道mmap后不flush直接通知producer
2.3 partition
partition的定义及划分
一个topic会分为多个partition放在多个节点上。
通过源码可知,partition默认是随机把该消息发给一个partition
当然你也可以自定义发送给那个partition。
partiton在文件系统上是一个物理文件夹的形式。同时partition里有多个segment文件。
删除是就是删除segment文件。这样可以避免随机删除数据。
partition的优化
因为存在于多个节点,可以充分发挥集群优势。
如果就一个节点,多个分区也可以配置在一个磁盘上。实现磁盘间的并行。
一般精确到节点即可
3.零拷贝
sendfile技术。该参数在nginx 等web服务器中也有可以大幅提升文件传输性能。
一般传输文件是以下过程
调用read函数,文件数据被硬件层copy到内核缓冲区
read函数返回,文件数据从内核缓冲区copy到用户缓冲区
write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
数据从socket缓冲区copy到相关协议引擎。
以上细节是传统read/write方式进行网络文件传输的方式,我们可以看到,在这个过程当中,文件数据实际上是经过了四次copy操作:
硬盘—>内核buf—>用户buf—>socket相关缓冲区—>协议引擎
而sendfile系统调用则提供了一种减少以上多次copy,提升文件传输性能的方法。
在内核版本2.1中,引入了sendfile系统调用,以简化网络上和两个本地文件之间的数据传输。 sendfile的引入不仅减少了数据复制,还减少了上下文切换。
sendfile(socket, file, len);
运行流程如下:
sendfile系统调用,文件数据被copy至内核缓冲区
再从内核缓冲区copy至内核中socket相关的缓冲区
最后再socket相关的缓冲区copy到协议引擎
硬盘->内核->内核中scoket区->协议引擎
相较传统read/write方式,2.1版本内核引进的sendfile已经减少了内核缓冲区到user缓冲区,再由user缓冲区到socket相关缓冲区的文件copy,而在内核版本2.4之后,文件描述符结果被改变,sendfile实现了更简单的方式,再次减少了一次copy操作。
在apache,nginx,lighttpd等web服务器当中,都有一项sendfile相关的配置,使用sendfile可以大幅提升文件传输性能。
Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把文件发送给消费者,配合mmap作为文件读写方式,直接把它传给sendfile。
4.删除策略
因为kafka的特殊构造,导致其并不好删除数据。所以kafka提供了两种策略。
可以基于时间删除文件,也可以基于partition大小删除文件。
5.批量压缩
对于大量数据流来说,网络IO很重要,所以kafka提供了压缩策略。
但是一个一个压缩效率会很低,所以是批量压缩。kafka支持gzip和snappy等格式。
6.总结
可以理解为epol为程序设计框架,而零拷贝是具体的关于 fd队列读写中的设计,而mmap则是具体的执行,就是零拷贝是怎么实现的。零拷贝相对于普通的I/O中忽略的关于把数据从内核层拷贝至用户缓冲区的部分就是mmap实现。















 1166
1166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









