






创建express项目,使用express写一个爬虫程序
创建express项目
npm install -g express-generator 全局安装express脚手架
express ProjectName(项目名) 创建express项目文件夹
创建成功后,根据提示进行操作
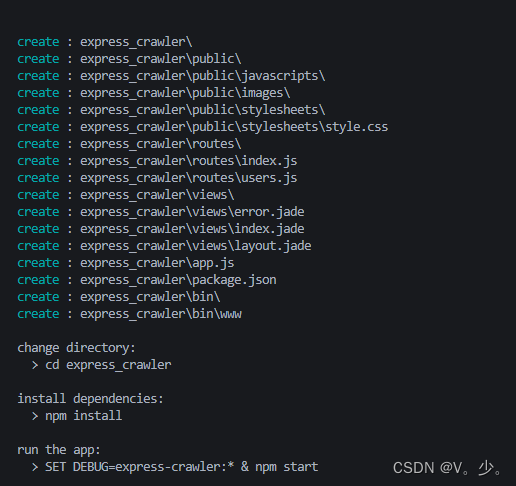
cd ProjectName(项目名) 进入项目
npm install 安装依赖
npm start 运行项目
npm install body-parser -S 安装插件
npm i -S nodemon 可以热更新
修改项目文件
app.js中将
module.exports = app;
替换成
app.listen(3000, () => {
console.log('Web服务已经启动,端口3000监听中...');
})
控制台输入
nodemon app.js 启动服务(app.js为入口文件,可换做自己的入口文件)
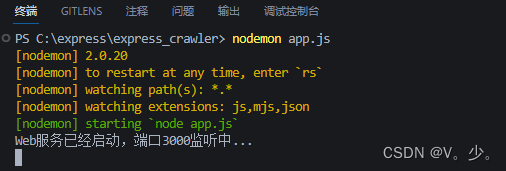
运行成功,打开浏览器,输入地址localhost:3000
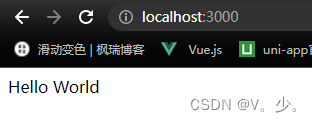
index.js文件中将
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'jade');
替换
app.get('/', function (req, res, next) {
res.send("Hello World");
});
连接数据库
npm install -S mysql 安装mysql
根目录下创建utils/dbConfig.js连接数据库
const mysql = require('mysql')
module.exports = {
// 数据库配置
config:{
host:'localhost',//数据库地址
port:'3306',//端口号
user:'',//用户名
password:'',//密码
database:''//数据库名称
},
// 连接数据库,使用mysql得连接池连接方式
// 连接池对象
sql:function(sql,sqlArr,callback){
var pool = mysql.createPool(this.config)
pool.getConnection((err,conn)=>{
if(err){
console.log('连接失败',err)
return;
}
console.log('连接成功')
// 事件驱动回调
conn.query(sql,sqlArr,callback);
// 释放连接
conn.release();
})
},
// promise回调
sqlSync:function(syncSql,syncSqlArr){
return new Promise((res,rej)=>{
var pool = mysql.createPool(this.config)
pool.getConnection((err,conn)=>{
if(err){
rej(err)
}else{
// 事件驱动回调
conn.query(syncSql,syncSqlArr,(err,data)=>{
if(err){
rej(err)
}else{
res(data)
}
})
// 释放连接
conn.release()
}
})
}).catch((err)=>{
console.log('promise err:',err)
})
}
}
安装爬虫插件,写爬虫逻辑
npm install x-crawl 安装爬虫插件
根目录下创建controller文件夹,用来当做控制层,写业务代码
const db = require('../utils/dbConfig') //引入数据库,不存数据库可以注释掉
// const db = require('../utils/dbConfig') //引入数据库,不存数据库可以注释掉
// 创建爬虫实例
getList = (req,res) => {
const xCrawl = require('x-crawl')
const myXCrawl = xCrawl({ maxRetry: 3, intervalTime: { max: 3000, min: 2000 } })
myXCrawl.startPolling({ d: 1 }, async (count, stopPolling) => {
// 调用 crawlPage API 来爬取页面
const resCrawler = await myXCrawl.crawlPage({
//目标地址
targets: [
'https://www.airbnb.cn/s/experiences',
'https://www.airbnb.cn/s/plus_homes'
],
viewport: { width: 1920, height: 1080 }
})
// 存放图片 URL 到 targets
const targets = []
const elSelectorMap = ['._fig15y', '._aov0j6']
for (const item of resCrawler) {
const { id } = item
const { page } = item.data
// 等待页面加载完成
await new Promise((r) => setTimeout(r, 300))
// 获取页面图片的 URL
const urls = await page.$$eval(`${elSelectorMap[id - 1]} img`, (imgEls) => {
return imgEls.map((item) => item.src)
})
targets.push(...urls)
// 关闭页面
page.close()
}
res.json({
data:targets
})
// 调用 crawlFile API 爬取图片
await myXCrawl.crawlFile({ targets, storeDirs: './upload' })
})
}
//导出方法
module.exports = {
getList,
}
跟目录下创建router文件夹,用来当做页面路由,可根据地址调用方法
文件夹下创建crawler.js
const express = require('express')
const router = express.Router()
const list = require('../controller/crawler')
router.get('/getList',list.getList)
module.exports = router;
app.js中引入路由并使用
const listRouter= require('./router/crawler')
app.use('/list', listRouter)
检测爬虫是否成功
输入地址 http://localhost:3000/list/getList
会显示
{"data":["https://z1.muscache.cn/4ea/air/v2/pictures/d6fc5b05-29cf-497d-980a-98678c6560d6.jpg?t=r:w654-h400-sfit,e:fjpg-c90","https://z1.muscache.cn/4ea/air/v2/pictures/b3f52881-e642-4868-b873-e4cc0f23234b.jpg?t=r:w654-h400-sfit,e:fjpg-c90","https://z1.muscache.cn/4ea/air/v2/pictures/940525f0-2a7a-4286-8491-d99368081173.jpg?t=r:w654-h400-sfit,e:fjpg-c90","https://z1.muscache.cn/im/pictures/e066bb94-65aa-4840-ba02-7d2c72be2edf.jpg?im_w=720","https://z1.muscache.cn/im/pictures/monet/Select-13961761/original/1f4aec6c-e76f-4a3e-b29c-6805e4f3dbfb?im_w=720","https://z1.muscache.cn/im/pictures/b7c9264d-73c9-45c3-882e-6e9577d63d68.jpg?im_w=720","https://z1.muscache.cn/im/pictures/8af539b3-5bea-44a3-a687-2fc1010d2df7.jpg?im_w=720"]}
即为爬虫数据获取成功














 1471
1471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









