






day5-课程内容
一、元组【带上了枷锁的列表】
含义:由于元组和列表是近亲关系,所以原组和列表在实际应用上是非常相似的。所以主要对比列表讲解双方的不同
1、创建和访问一个元组
#创建一个元组大部分情况下使用小括号()
>>> tuple1 = (1,2,3,4,5)
>>> tuple1
(1, 2, 3, 4, 5)
>>> tuple1[1] #和列表一样,可以通过元素的索引值(下标)找到对应的元素并返回
2
>>> tuple1[:3] #和列表一样,可以做切片操作
(1, 2, 3)
>>> tuple1[1] = 3 #和列表不同,无法对元组中元素的值进行重新赋值更改
Traceback (most recent call last):
File "<pyshell#20>", line 1, in <module>
tuple1[1] = 3
TypeError: 'tuple' object does not support item assignment
注意点
如果想创建只有一个元素的元组,则不论是否加小括号,务必在第一个元素后加上逗号’,'才可以创建为元组,不然只能是赋值
>>> temp = (1)
>>> type(temp)
<class 'int'>
>>> temp1 =1,2,3,4
>>> type(temp1)
<class 'tuple'>
>>> temp2 = 1,
>>> type(temp2)
<class 'tuple'>
2、更新和删除一个元组
#更新可类似于列表,对现有的元组进行切片,在添加新的元素后与原来的切片进行拼接,从而形成新的元组
>>> temp = ('张三','李四','王五')
>>> temp = temp[:2] + ('赵六',) + temp[2:]
>>> temp
('张三', '李四', '赵六', '王五')
#删除元组
与列表操作类似,可使用del语句进行删除操作
>>> del temp
>>> temp
Traceback (most recent call last):
File "<pyshell#32>", line 1, in <module>
temp
NameError: name 'temp' is not defined
3、元组相关的操作符
#拼接操作符
‘+’
#重复操作符
‘*’
#关系操作符
‘> <’
#成员操作符
‘in’ ‘not in’
#逻辑操作符
‘and’'or’etc…
二、字符串
#和列表和元组一样,字符串也可以进行切片
>>> str1 = 'i love you'
>>> str1[:5]
'i lov'
#也可以进行索引
>>> str1[6]
' '
#也可以进行新的字符串的拼接
>>> str1[:5] + '插入的字符串' +str1[5:]
'i lov插入的字符串e you'
#字符串的比较操作符、成员操作符、逻辑操作符、关系操作符、拼接操作符,和元组以及列表都一样
#字符串的各类操作方法
capitalize():把字符串的第一个字符改为大写
str1 = 'i love you'
>>> str1.capitalize()
'I love you'
casefold():把整个字符串的所有字符改为小写
str1 = 'i love you'
>>> str1.casefold()
'i love you'
center(width):将字符串居中,并使用空格填充至长度 width 的新字符串
str1 = 'i love you'
>>> str1.center(10)
'i love you'
>>> str1.center(50)
' i love you '
count(sub[, start[, end]]):返回 sub 在字符串里边出现的次数,start 和 end 参数表示范围,可选。
str1 = 'i love you'
>>> str1.count('o',8)
1
>>> str1.count('o')
2
encode(encoding=‘utf-8’, errors=‘strict’):以 encoding 指定的编码格式对字符串进行编码。
暂时未讲解
str1 = 'i love you'
>>> str1.encode()
b'i love you'
endswith(sub[, start[, end]]):检查字符串是否以 sub 子字符串结束,如果是返回 True,否则返回 False。
start 和 end 参数表示范围,可选。
str1 = 'i love you'
>>> str1.endswith('u')
True
>>> str1.endswith('u',3,5)
False
expandtabs([tabsize=8]):把字符串中的*** tab 符号(\t)***转换为空格,如不指定参数,默认的空格数是 tabsize=8。
>>> str1 = 'i\tlove\tyou\t'
>>> str1
'i\tlove\tyou\t'
>>> str1.expandtabs()
'i love you '
find(sub[, start[, end]]):检测 sub 是否包含在字符串中,如果有则返回索引值,否则返回 -1,start 和 end 参数表示范围,可选。
>>> str1
'i\tlove\tyou\t'
>>> str1.find('o')
3
>>> str1.find('o',1,7)
3
>>> str1.find('o',5,7)
-1
index(sub[, start[, end]]):跟 find 方法一样,不过如果 sub 不在 string 中会产生一个异常。
>>> str1
'i\tlove\tyou\t'
>>> str1.index('o',5,7)
Traceback (most recent call last):
File "<pyshell#57>", line 1, in <module>
str1.index('o',5,7)
ValueError: substring not found
>>> str1.index('o',1,7)
3
isalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False。
>>> str1
'i\tlove\tyou\t'
>>> str1.isalnum()
False
>>> str2 = '1'
>>> str2.isalnum()
True
>>> str3 = '213123dgf'
>>> str3.isalnum()
True
isalpha():如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。
>>> str3.isalpha()
False
isdecimal():如果字符串只包含十进制数字则返回 True,否则返回 False。
>>> str1 = '1'
>>> str1.isdecimal()
True
isdigit():如果字符串只包含数字则返回 True,否则返回 False。
islower():如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回 True,否则返回 False。
isnumeric():如果字符串中只包含数字字符,则返回 True,否则返回 False。
isspace():如果字符串中只包含空格,则返回 True,否则返回 False。
istitle():如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回 True,否则返回 False。
isupper():如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回 True,否则返回 False。
以上均为判断,不过多尝试
join(sub):以字符串作为分隔符,插入到 sub 中所有的字符之间。
>>> str2 = 'i love fishc.com'
>>> str2.join('插入的字符')
'插i love fishc.com入i love fishc.com的i love fishc.com字i love fishc.com符'
ljust(width):返回一个左对齐的字符串,并使用空格填充至长度为 width 的新字符串。
>>> str2.ljust(50)
'i love fishc.com '
lower():转换字符串中所有大写字符为小写。
>>> str2 = 'I LOVE FISHC.COM'
>>> str2.lower()
'i love fishc.com'
lstrip():去掉字符串左边的所有空格
>>> str1 = ' ewr'
>>> str1.lstrip()
'ewr'
partition(sub):找到子字符串 sub,把字符串分成一个 3 元组 (pre_sub, sub, fol_sub),如果字符串中不包含 sub 则返回 (‘原字符串’, ‘’, ‘’)
>>> str2 = 'I LOVE FISHC.COM'
>>> str2.partition('O')
('I L', 'O', 'VE FISHC.COM')
replace(old, new[, count]):把字符串中的 old 子字符串替换成 new 子字符串,如果 count 指定,则替换不超过 count 次。
>>> str2.replace('O','X',1) #指定修改次数
'I LXVE FISHC.COM'
>>> str2.replace('O','X') #未指定修改次数
'I LXVE FISHC.CXM'
rfind(sub[, start[, end]]):类似于 find() 方法,不过是从右边开始查找。
rindex(sub[, start[, end]]):类似于 index() 方法,不过是从右边开始。
rjust(width):返回一个右对齐的字符串,并使用空格填充至长度为 width 的新字符串。
rpartition(sub):类似于 partition() 方法,不过是从右边开始查找。
rstrip():删除字符串末尾的空格。
与上述的几种方法类似,只不过换了开始的方向,不过多讲解
split(sep=None, maxsplit=-1):不带参数默认是以空格为分隔符切片字符串,如果 maxsplit 参数有设置,则仅分隔 maxsplit 个子字符串,返回切片后的子字符串拼接的列表。
>>> str2.split()
['I', 'LOVE', 'FISHC.COM']
>>> str2.split('.')
['ilovefishc', 'com']
splitlines(([keepends])):按照’\n’分隔,返回一个包含各行作为元素的列表,如果keepends参数指定,则返回前keepends行
存疑
startswith(prefix[, start[, end]]):检查字符串是否以 prefix 开头,是则返回 True,否则返回 False。start 和 end 参数可以指定范围检查,可选。
>>> str2 = 'i\nlove\nyou'
>>> str2.startswith('i')
True
strip([chars]):删除字符串前边和后边所有的空格,chars 参数可以定制删除的字符,可选。
存疑
>>> str2.strip('l')
'i\nlove\nyou'
swapcase():翻转字符串中的大小写。
>>> str2 = 'ILOVEfisc'
>>> str2.swapcase()
'iloveFISC'
title():返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。
>>> str2 = 'ILOVEfisc'
>>> str2.title()
'Ilovefisc'
translate(table):根据 table 的规则(可以由 str.maketrans(‘a’, ‘b’) 定制)转换字符串中的字符。
>>> str2 = 'ILOVEfisc'
>>> str2.translate(str.maketrans('O', 'x'))
'ILxVEfisc'
upper():转换字符串中的所有小写字符为大写。
>>> str2 = 'ILOVEfisc'
>>> str2.upper()
'ILOVEFISC'
zfill(width):返回长度为 width 的字符串,原字符串右对齐,前边用 0 填充。
三、字符串格式化【解决格式不统一的问题】
1、format()方法
#位置参数和关键字参数
>>> '{0} love {1}.{2}'.format('i','fishc','com') #{0}{1}{2}是字段,1,2,3是位置参数,或关键字,'i''fischc''com'是关键字参数
'i love fishc.com'
>>> '{a} love {b}.{c}'.format(a='i',b='fishc',c='com') #也可以使用关键字参数定义
'i love fishc.com'
>>> '{a} love {b}.{c}'.format('i','fishc','com') #如果不使用的话,那么将无法识别对应的字符串
Traceback (most recent call last):
File "<pyshell#120>", line 1, in <module>
'{a} love {b}.{c}'.format('i','fishc','com')
KeyError: 'a'
>>> '{0} love {b}.{c}'.format('i',b='fishc',c='com') #若位置参数和关键字参数混用的话,那么位置参数必须在关键字参数之前
'i love fishc.com'
>>> '{a} love {b}.{0}'.format(a='i',b='fishc','com') #不然如果放到后面的话,系统识别不到
SyntaxError: positional argument follows keyword argument
2、字符串格式化符号含义【%是字符串专用操作符】
语法:‘格式化字符’ % 要格式化的字符
%c:格式化字符及其 ASCII 码
>>> '%c' % 97
'a'
>>> '%c %c %c' % (97,98,99) #若放入多个需要格式化的字符,需用小括号以元组的形式输入
'a b c'
%s:格式化字符串
%d:格式化整数
%o:格式化无符号八进制数
%x:格式化无符号十六进制数
%X:格式化无符号十六进制数(大写)
%f:格式化浮点数字,可指定小数点后的精度
%e:用科学计数法格式化浮点数
%E:作用同 %e,用科学计数法格式化浮点数
%g:根据值的大小决定使用 %f 或 %e
%G:作用同 %g,根据值的大小决定使用 %f 或者 %E
3、格式化操作符辅助命令
m.n:m 是显示的最小总宽度,n 是小数点后的位数
-:用于左对齐
+:在正数前面显示加号(+)
#:在八进制数前面显示 ‘0o’,在十六进制数前面显示 ‘0x’ 或 ‘0X’
0:显示的数字前面填充 ‘0’ 取代空格
4、Python的转义字符及其含义
':单引号
":双引号
\a:发出系统响铃声
\b:退格符
\n:换行符
\t:横向制表符(TAB)
\v:纵向制表符
\r:回车符
\f:换页符
\o:八进制数代表的字符
\x:十六进制数代表的字符
\0:表示一个空字符
\:反斜杠
四、序列!
1、列表、元组和字符串的共同点【统称为:序列】
#都可以通过索引得到每一个元素
#默认的索引值总是从0开始
#可以通过分片的方法得到一个范围内的元素的集合
#有很多共同的操作符(重复、拼接、成员)
2、关于序列的常见BIF
list(不带参数)
#含义:生成一个空的列表
list(带参数[interable])
#含义:把一个可迭代的对象转换为列表 interable表示迭代器
迭代:就是重复反馈过程的活动,其目的就是为了接近或达到所需的目标或结果。每一次对过程重复就是一次迭代,每一次迭代的结果又会成为下一次迭代的初始值
#将字符串迭代转换为列表
>>> b = 'i love fishc.com'
>>> b = list(b)
>>> b
['i', ' ', 'l', 'o', 'v', 'e', ' ', 'f', 'i', 's', 'h', 'c', '.', 'c', 'o', 'm']
#将元组迭代转换为列表
>>> c = (1,1,2,3,5,8,13,21,34)
>>> c = list(c)
>>> c
[1, 1, 2, 3, 5, 8, 13, 21, 34]
tuple([interable])
#含义:把一个可迭代的对象转换为元组
str(obj)
#含义:把obj对象转换为字符串
len(sub)
#含义:返回sub的长度
>>> c = (1,1,2,3,5,8,13,21,34)
>>> len(c)
9
max()
#含义:返回序列或集合中的最大值
>>> max(c)
34
>>> number = [1,18,13,0,-98]
>>> max(number)
18
min()
#含义:返回序列或集合中的最小值
>>> number = [1,18,13,0,-98]
>>> min(number)
-98
>>> chars = '1234567890'
>>> min(chars)
'0'
注意:使用max()和min()方法必须保证参数的数据类型是统一的,可以全部是整数、元组等等
实现原理
for each in tuple1:
if each > max:
max = each
return max
sum(interable[,start=0])
#返回序列interable和可选参数start的总和
>>> tuple2 = (3.1,2.3,3.4)
>>> sum(tuple2)
8.8
>>> sum(number)
-66
>>> sum(number,8)
-58
>>> sum(chats) #非整数、浮点数的数据类型,进行sum操作的时候会报错
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
sum(chats)
NameError: name 'chats' is not defined
sorted()
#进行从小到大默认排序
>>> sorted(number)
[-98, 0, 1, 13, 18]
reversed()
#原地逆转
>>>number = [1,18,13,0,-98]
>>> reversed(number) #reversed()返回的是一个迭代器对象,可用list转换成一个列表
<list_reverseiterator object at 0x03AB7D48>
>>> list(reversed(number))
[-98, 0, 13, 18, 1]
enumerate()
#生成由每个元素的index值和item值生成的元组
>>> enumerate(number)
<enumerate object at 0x03AC3868>
>>> list(enumerate(number))
[(0, 1), (1, 18), (2, 13), (3, 0), (4, -98)]
zip
#返回由各个序列的参数组成的元组
>>> a = [1,2,3,4,5,6]
>>> b = [1,2,3,4]
>>> zip(a,b)
<zip object at 0x03A903A8>
>>> list(zip(a,b))
[(1, 1), (2, 2), (3, 3), (4, 4)]
day4-课后作业
0 请用一句话描述什么是列表?再用一句话描述什么是元组?
自答:被打了激素的数组,带上了枷锁的列表
参考答案:
列表:一个大仓库,你可以随时往里边添加和删除任何东西。
元组:封闭的列表,一旦定义,就不可改变(不能添加、删除或修改)
1 什么情况下你需要使用元组而不是列表?
自答:数据不需或不让轻易进行更改的时候
参考答案:当我们希望内容不被轻易改写的时候,我们使用元组(把权力关进牢笼)
当我们需要频繁修改数据,我们使用列表
2 当元组和列表掉下水,你会救谁?
自答:元组,丢了就没啦
参考答案:如果是我,我会救列表,因为列表提供了比元组更丰富的内置方法,这相当大的提高了编程的灵活性。
回头来看下元组,元组固然安全,但元组一定创建就无法修改(除非通过新建一个元组来间接修改,但这就带来了消耗),而我们人是经常摇摆不定的,所以元组只有在特殊的情况才用到,平时还是列表用的多。
3 请将下图左边列表的内置方法与右边的注释连线,并圈出元组可以使用的方法。

自答:
appeng()在最后增加一个元素
extend()扩展列表(用另一个列表)
count()计算并返回指定元素的数量
remove()删除一个元素
pop()删除并返回最后一个元素
sort()按特定的顺序排序(从小到大)
insert()在指定位置插入一个元素
copy()拷贝一个副本
clear()清空所有元素
reverse()原地翻转所有的数据
index()寻找并返回参数的索引值
元组可使用的方法:count()和index()
4创建一个元组,什么情况下逗号和小括号必须同时存在,缺一不可?
自答:当这个元组只有一个元素的时候
参考答案:在拼接只有一个元素的元组的时候,例如我们课上举的例题:
>>> temp = (‘小甲鱼’, ‘黑夜’, ‘迷途’, ‘小布丁’)
#如果我想在“黑夜”和“迷途”之间插入“怡静”,我们应该:
>>> temp = temp[:2] + (‘怡静’,) + temp[2:]
5 x, y, z = 1, 2, 3 请问x, y, z是元组吗?
自答:不是。
参考答案:所有的【多对象】的、逗号分隔的、没有明确用符号定义的这些集合默认的类型都是元组
6 请写出以下情景中应该使用列表还是元组来保存数据:
a游戏中角色的属性
b你的身份证信息
c论坛的会员
d团队合作开发程序,传递给一个你并不了解具体实现的函数的参数
e航天火箭各个组件的具体配置参数
fNASA系统中记录已经发现的行星数据
自答:
列表:a、c、d
元组:b、e、f
参考答案:
列表:a、b、f
元组:b、d、e
7.上节课我们通过课后作业的形式学习到了“列表推导式”,那请问如果我把中括号改为小括号,会不会得到“元组推导式”呢?
自答:会的。因为列表和元组同属于序列
参考答案:
Python3 木有“元组推导式”,为嘛?没必要丫,有了“列表推导式”已经足够了
那为什么“>>> tuple1 = (x**2 for x in range(10))”不会报错?
因为你误打误撞得到了一个生成器:
>>> type(tuple1)
<class 'generator'>
关于生成器的概念小甲鱼今后会细讲,你可以尝试这么去访问我们刚刚的生成器:
#注意,Python3 开始 next() 方法改为 next() 哦~
0
>>> tuple1.__next__()
1
>>> tuple1.__next__()
4
>>> tuple1.__next__()
9
>>> tuple1.__next__()
16
>>> tuple1.__next__()
25
>>> tuple1.__next__()
36
8.还记得如何定义一个跨越多行的字符串吗(请至少写出两种实现的方法)?
自答:
方法一:使用\n作为换行符
方法二:在文本文件中打印好,再复制上去
9.三引号字符串通常我们用于做什么使用?
自答:希望得到一个跨越多行的字符串
10.file1 = open(‘C:\windows\temp\readme.txt’, ‘r’) 表示以只读方式打开“C:\windows\temp\readme.txt”这个文本文件,但事实上这个语句会报错,知道为什么吗?你会如何修改?
自答:因为没有用原始字符串’r’或放斜杠自身对反斜杠进行转义。比较方便的就是在’C前加上’r’
11.有字符串:str1 = ‘鱼C资源打包’,请问如何提取出子字符串:‘www.fishc.com’
自答:
方法一:POP:str1.pop(‘www.fishc.com’)
方法二:通过索引值和切片str2 = str1[str1.index(‘www.fishc.com’):]+str1[:str1.index(‘www.fishc.com’)]
12.如果使用负数作为索引值进行分片操作,按照第三题的要求你能够正确目测出结果吗?
自答:st2 = str1[-45:-32]
13.还是第三题那个字符串,请问下边语句会显示什么内容?
>>> str1[20:-36]
自答:fischc
附加题:据说只有智商高于150的鱼油才能解开这个字符串(还原为有意义的字符串):
str1 = ‘i2sl54ovvvb4e3bferi32s56h;$c43.sfc67o0cm99’
14.根据说明填写相应的字符串格式化符号

自答:
%c 格式化字符串及其ASCII码
%s 格式化字符串
%d 格式化整数
%o 格式化无符号八进制数
%x 格式化无符号十六进制数
%X 格式化无符号十六进制数(大写)
%f 格式化浮点数字,可指定小数点后的精度
%e 用科学计数法格式化浮点数
%E 作用同%e,用科学计数法格式化浮点数
%g 根据值的大小决定使用%f或%e
%G 作用同%g,根据值的大小决定使用%f或%E
15.请问以下这行代码会打印什么内容?
>>> "{{1}}".format("不打印", "打印")
自答:打印
参考答案:{1}
16.以下代码中,a, b, c是什么参数?
>>> "{a} love {b}.{c}".format(a="I", b="FishC", c="com")
'I love FishC.com'
自答:关键字参数
17.以下代码中,{0}, {1}, {2}是什么参数?
>>> "{0} love {1}.{2}".format("I", "FishC", "com")
'I love FishC.com'
自答:位置参数
18.如果想要显示Pi = 3.14,format前边的字符串应该怎么填写呢?
''.format('Pi = ', 3.1415)
自答:{2.%f.2}
参考答案:{0}{1:.2f}
19.我们根据列表、元组和字符串的共同特点,把它们三统称为什么?
自答:序列
参考答案:
序列,因为他们有以下共同点
1)都可以通过索引得到每一个元素
2)默认索引值总是从0开始(当然灵活的Python还支持负数索引)
3)可以通过分片的方法得到一个范围内的元素的集合
4)有很多共同的操作符(重复操作符、拼接操作符、成员关系操作符)
20.请问分别使用什么BIF,可以把一个可迭代对象转换为列表、元组和字符串?
自答:list([interable])
参考答案:list([iterable]) 把可迭代对象转换为列表
tuple([iterable]) 把可迭代对象转换为元组
str(obj) 把对象转换为字符串
21.你还能复述出“迭代”的概念吗?
自答:迭代就是重复反馈过程的活动,其目的通常是为了接近并到达所需的目标或结果
参考答案:所谓迭代,是重复反馈过程的活动,其目的通常是为了接近并到达所需的目标或结果。每一次对过程的重复被称为一次“迭代”,而每一次迭代得到的结果会被用来作为下一次迭代的初始值。
22.你认为调用 max(‘I love FishC.com’) 会返回什么值?为什么?
自答:‘v’,因为’v’的ASCII编码是最大的,'v’对应的是188
参考答案:
会返回:‘v’,因为字符串在计算机中是以ASCII码的形式存储(ASCII对照表:https://www.cnblogs.com/hcxy2007107708/articles/10010167.html),参数中ASCII码值最大的是’v’对应的118。
23.哎呀呀,现在的小屁孩太调皮了,邻居家的孩子淘气,把小甲鱼刚写好的代码画了个图案,麻烦各位鱼油恢复下啊,另外这家伙画的是神马吗?怎么那么眼熟啊!??
动动手:

自答:
name = input('请输入待查找的用户名:')
score = [['迷途',85],['黑夜',80],['小布丁',65],['福禄娃娃',95],['怡静',90]]
for each in score:
if name in each:
print(name + '的得分是',each[1])
break
if name not in each:
print('查找的数据不存在!')
参考答案:
name = input('请输入待查找的用户名:')
score = [['迷途', 85], ['黑夜', 80], ['小布丁', 65], ['福禄娃娃', 95], ['怡静', 90]]
IsFind = False
for each in score:
if name in each:
print(name + '的得分是:', each[1])
IsFind = True
break
if IsFind == False:
print('查找的数据不存在!')
24.请写一个密码安全性检查的代码:check.py


自答:
scret = input('请输入需要检查的密码组合:')
chang = len(scret)
teshu = ('~','!','@','#','$','%','^','&','*','(',')','_','=','-','/',',','.','?','<','>',';',':','[',']','{','}','\\')
if chang <= 8:
if scret.isalnum() == 1:
print('您的密码安全级别评定为:低')
print('请按以下方法提升您的密码安全级别:\n1.密码必须由数字、字母及特殊字符三种组合\n2.密码只能由字母开头\n3.密码长度不能低于16位')
elif 8<scret<16:
if (scret.isnumeric() == 1 and scret.isalpha() ==1 ) or (scret.isnumeric() == 1 and teshu in scret) or (scret.isalpha() == 1 and teshu in scret):
print('您的密码安全级别评定为:中')
print('请按以下方式提升您的密码安全级别:\n1.密码必须由数字、字母及特殊字符三种组合\n2.密码只能由字母开头\n3.密码长度不饿能低于16位')
else:
if (scret.isnumeric() == 1 and scret.isalpha() == 1 and teshu in scret):
print('您的密码安全级别评定为:高')
print('请继续保持')
print('输入有误')
捣鼓了半天只能判断安全级别评定为低的。。
参考答案:
# 密码安全性检查代码
#
# 低级密码要求:
# 1. 密码由单纯的数字或字母组成
# 2. 密码长度小于等于8位
#
# 中级密码要求:
# 1. 密码必须由数字、字母或特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)任意两种组合
# 2. 密码长度不能低于8位
#
# 高级密码要求:
# 1. 密码必须由数字、字母及特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)三种组合
# 2. 密码只能由字母开头
# 3. 密码长度不能低于16位
symbols = r'''`!@#$%^&*()_+-=/*{}[]\|'";:/?,.<>'''
chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
nums = '0123456789'
passwd = input('请输入需要检查的密码组合:')
# 判断长度
length = len(passwd)
while (passwd.isspace() or length == 0) :
passwd = input("您输入的密码为空(或空格),请重新输入:")
length = len(passwd)
if length <= 8:
flag_len = 1
elif 8 < length < 16:
flag_len = 2
else:
flag_len = 3
flag_con = 0
# 判断是否包含特殊字符
for each in passwd:
if each in symbols:
flag_con += 1
break
# 判断是否包含字母
for each in passwd:
if each in chars:
flag_con += 1
break
# 判断是否包含数字
for each in passwd:
if each in nums:
flag_con += 1
break
# 打印结果
while 1 :
print("您的密码安全级别评定为:", end='')
if flag_len == 1 or flag_con == 1 :
print("低")
elif flag_len == 3 and flag_con == 3 and (passwd[0] in chars):
print("高")
print("请继续保持")
break
else:
print("中")
print("请按以下方式提升您的密码安全级别:\n\
\t1. 密码必须由数字、字母及特殊字符三种组合\n\
\t2. 密码只能由字母开头\n\
\t3. 密码长度不能低于16位")
break
25.编写一个进制转换程序,程序演示如下(提示,十进制转换二进制可以用bin()这个BIF):
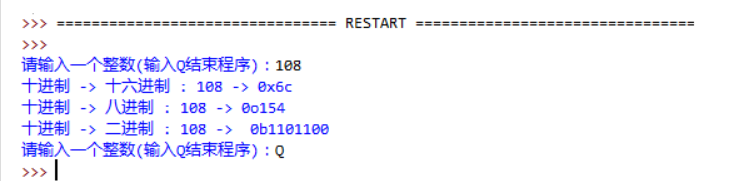
参考:
q = True
while q:
num = input('请输入一个整数(输入Q结束程序):')
if num != 'Q':
num = int(num)
print('十进制 -> 十六进制 : %d -> 0x%x' % (num, num))
print('十进制 -> 八进制 : %d -> 0o%o' % (num, num))
print('十进制 -> 二进制 : %d -> ' % num, bin(num))
else:
q = False
26.猜想一下 min() 这个BIF的实现过程
自答:
x = xx[0]
for each in XX:
if each < x:
x = each
return x
continue
print(x)
参考答案:
def min(x):
least = x[0]
for each in x:
if each < least:
least = each
return least
print(min('123456789'))
27.视频中我们说 sum() 这个BIF有个缺陷,就是如果参数里有字符串类型的话就会报错,请写出一个新的实现过程,自动“无视”参数里的字符串并返回正确的计算结果
参考答案:
def sum(x):
result = 0
for each in x:
if (type(each) == int) or (type(each) == float):
result += each
else:
continue
return result
print(sum([1, 2.1, 2.3, 'a', '1', True]))














 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









