







liblinear分类minist数据集
老师要求用liblinear跑一下minist,所以做了个尝试。实际上,liblinear对一些小数据集的分类效果还是非常好的。
minist(hello world)
liblinear工具准备
liblinear官方主页:https://www.csie.ntu.edu.tw/~cjlin/liblinear/
从这里可以下载完整版的liblinear
说起liblinear,可谓是二分类界的头号玩家了。它是 ICML 2008学习挑战赛 冠军,同时开发者也为它提供了不同程序的接口,基本上,只有有台机子,就能用libnear跑跑分类。
如果不想访问主页可以从这里下载:
https://pan.baidu.com/s/1BKbldYUHIKk1z8fajJIhOg
提取码:dgmw
下载后如下:

官方最推荐接口是C++,但实际上,liblinear很多函数都是用python写出来的,下文我们也用python进行试验
minist提取特征值
minist里的手写图片不能直接分类,我们可以用NN输出图片集的特征值,对特征值进行分类。
但这里有个问题,就是特征值的保存格式问题。
minist正确提取特征值格式
提取好的特征如下:
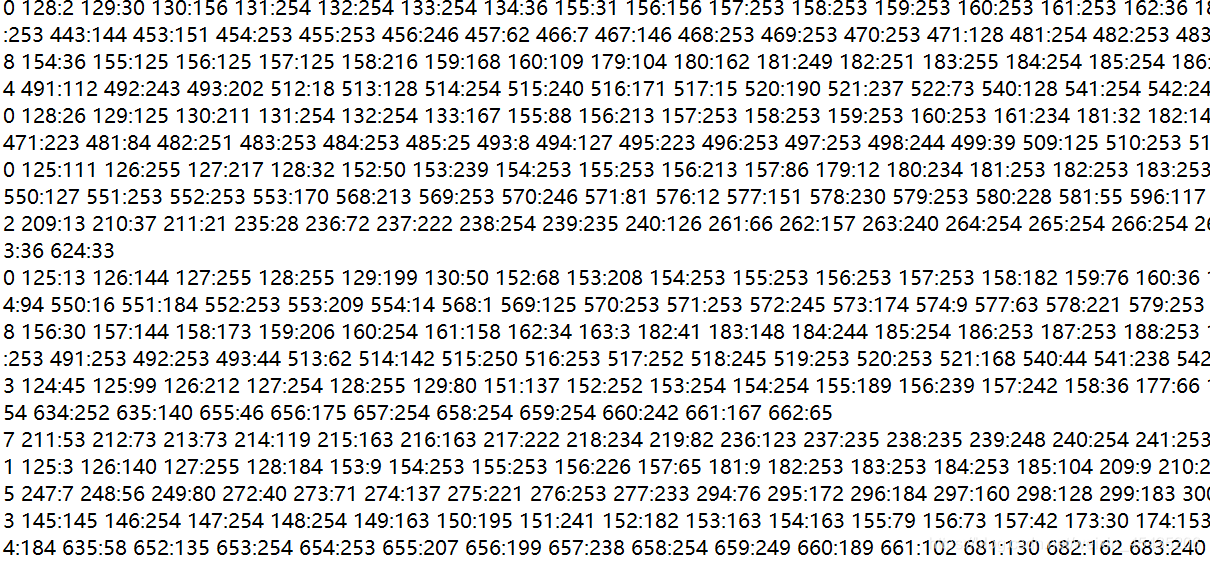
这是正确的特征值保存模式,我们应该用UTF编码(事实证明编码不影响),同时每一张图片要明确它的标签。这里是1-10十个数字,所以是十个标签。
minist也可谓是AI行业的hello world了,前任大佬们对其做过很多尝试。目前提取特征值较好的是NYU的一份数据,可以到NYU minist官网上下载。
如果不想访问主页可以从这里下载:
https://pan.baidu.com/s/1PHdQSc6RJtMgGkNe_S4HHw
提取码:hme0
liblinear特征值格式解释
liblinear读取的特征值有规定的格式,这个格式就像上面的图片所示,下面我来详细讲解一下特征值格式的规则。
liblinear数据集分为两个部分:标签&特征值
在读取时,liblinear的标签为最首要信息,也就是说,数据集的标签必须先被liblinear识别,才能读取之后的数值。所以对应地,每一个数据集里的数据元素的第一个数值都应该是标签,之后是不同的特征值。拿minist举例,minist有10个标签,像素为28*28=784,所以它的数据格式应该是1个标签784个特征值。那为什么上图中大多数数据没有784个特征值呢?因为默认0不显示。这也是linlinear数据格式的优点之一,减少无用数据的处理。
值得一提的是,liblinear的开发者贴心地在源文件中附带了一份正规格式的数据集 heart_scale
我们在读取任何数据时,都可以将其格式与 heart_scale 比对。
下面根据官方的例子来将 heart_scale的读取做一个演示(这里不解释代码,下文还会给出相同部分):
from liblinearutil import *
y, x = svm_read_problem('../heart_scale')
m = train(y[:200], x[:200], '-c 4')
p_label, p_acc, p_val = predict(y[200:], x[200:], m)
输出结果:

可以看到正确读取数据后,会自动给出测试准确率
为加深对格式理解,再给出一些不同的正确格式的数据集样例


实现代码&解释
做完所有准备工作,拿到liblinear神器,处理好minist生肉→熟肉,就可以烹饪分类了。
先给出实现代码
from liblinearutil import *
import time
time_start=time.time()
y, x = svm_read_problem('libmnist')
m = train(y[:30000], x[:30000],)
p_label, p_acc, p_val = predict(y[50000:], x[50000:], m)
time_end=time.time()
print('totally cost',time_end-time_start,'s')
代码非常简单对吧?这是因为liblinear的高度集成化,自动设置标签自动分类自动测试准确率。
代码的详细解释:
svm_read_problem() : 自带读取数据集的函数,返回两个参数,标签和特征值
svm_train() : 训练线性分类模型,本身可以作为模型参数被调用。至于它自己的那两个参数,就是随便取的两个切片(用前30000个数据训练)做个试验,当然也可以用minist全部数据,但可能会很慢hhh
svm_predict() : 预测,返回三个值,标签,准确率,概率误差度。一般我们只关心第二个。
实现结果:
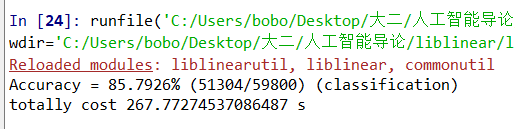
可以看到运行时间emmm…因为是十分类应该可以理解的吧(心虚)
准确度相对CNN直接拟合结果较低,从CNN半途提取特征效果不太好
但考虑到方便性,从liblinear白嫖还是非常划算的















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









