







丢失信息的雇员
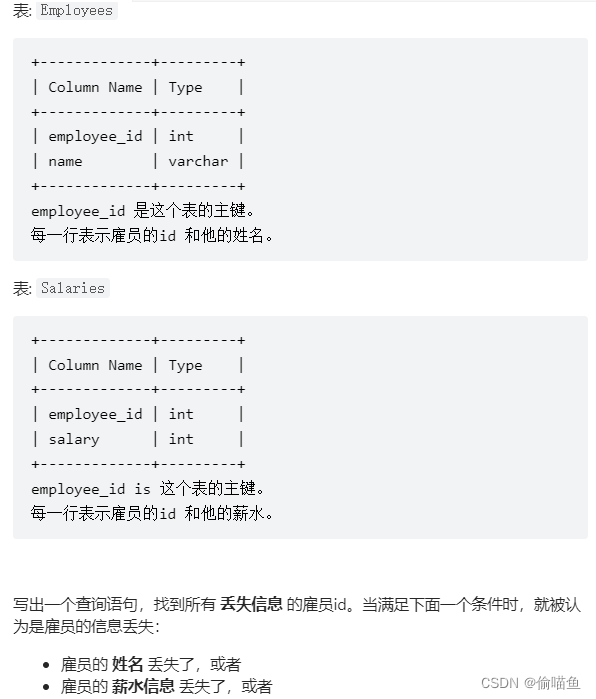
返回这些雇员的id employee_id , 从小到大排序 。
讨论 1
聚合搜索加Group BY 分组统计
select employee_id FROM
(
SELECT employee_id FROM Employees
UNION ALL
SELECT employee_id FROM Salaries
) AS t
GROUP BY employee_id
HAVING COUNT(*) = 1
ORDER BY employee_id ASC;
满外链接
select
t.employee_id
from
(
select
e.employee_id
from
Employees e left join Salaries s
on e.employee_id = s.employee_id
where
s.salary is null
union all
select
s.employee_id
from
Salaries s left join Employees e
on s.employee_id = e.employee_id
where
e.name is null
) t
order by
t.employee_id asc;
------------------------------------------------------
select employee_id from (
select e.employee_id employee_id from Employees e left join Salaries s on e.employee_id=s.employee_id where salary is null
union all
select s.employee_id employee_id from Employees e right join Salaries s on e.employee_id=s.employee_id where name is null
) x order by employee_id;
看对方主键是否存在
select
e.employee_id employee_id
from
Employees e left join Salaries s
on e.employee_id=s.employee_id
where s.employee_id is null ##返回左表中无右表的id
union all
select
s.employee_id employee_id
from
Employees e right join Salaries s on e.employee_id=s.employee_id
where
e.employee_id is null ##返回右表中无左表的id
order by employee_id;
not exists
select e.employee_id employee_id
from Employees e
where not exists (select 1 from Salaries s where s.employee_id = e.employee_id)
union all
select s.employee_id employee_id
from Salaries s
where not exists (select 1 from Employees e where s.employee_id = e.employee_id)
order by employee_id;
---------------------------------------
select employee_id
from Employees
where employee_id
not in
(select employee_id from Salaries)
union all
select employee_id
from Salaries
where employee_id not in
(select employee_id from Employees)
order by employee_id;
直接求差集
select employee_id from
(
select employee_id, count(1) cnt
from
(
select employee_id from Employees
union all
select employee_id from Salaries
) x
group by employee_id having cnt=1
) y order by employee_id;
讨论 2
union all 联合多表
group by 按照id分组
having 条件筛选
order by 升序排序
select employee_id from (
select employee_id from Employees
union all
select employee_id from Salaries
) as ans
group by employee_id
having count(employee_id) = 1
order by employee_id;
每个产品在不同商店的价格
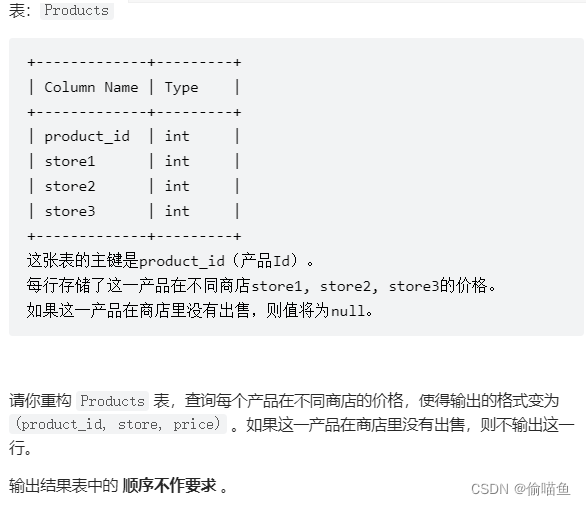
讨论 1
行转列(横表转竖表)
一列一列处理:把“列名”做为新列的value(如本题的store),把原来的value也作为新列(如本题的price),这是一个查询,其他列不要
用union all拼接每一列的结果
注意本题如果这一产品在商店里没有出售,则不输出这一行,所以要原列 is not null的筛选条件
代码
select product_id, 'store1' as store, store1 as price
from Products where store1 is not null
union all
select product_id, 'store2' as store, store2 as price
from Products where store2 is not null
union all
select product_id, 'store3' as store, store3 as price
from Products where store3 is not null;
讨论 2
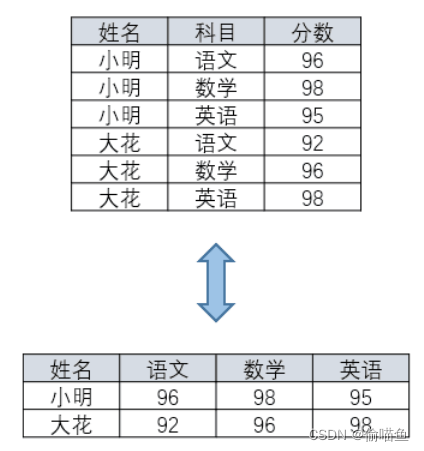
行转列——MAX/SUM+CASE WHEN+GROUP BY
SELECT name,
MAX(CASE WHEN subject='语文' THEN score ELSE 0 END) AS "语文",
MAX(CASE WHEN subject='数学' THEN score ELSE 0 END) AS "数学",
MAX(CASE WHEN subject='英语' THEN score ELSE 0 END) AS "英语"
FROM student1
GROUP BY name
列转行——MAX+UNION+GROUP BY
SELECT NAME,'语文' AS subject,MAX("语文") AS score
FROM student2 GROUP BY NAME
UNION
SELECT NAME,'数学' AS subject,MAX("数学") AS score
FROM student2 GROUP BY NAME
UNION
SELECT NAME,'英语' AS subject,MAX("英语") AS score
FROM student2 GROUP BY NAME
本题解答
# SELECT 字符串 作为新列,WHERE 筛选,UNION ALL 拼接各筛选项
select product_id,'store1' store,store1 price
from Products where store1 is not null
group by 1
union all
select product_id,'store2' store,store2 price
from Products where store2 is not null
group by 1
union all
select product_id,'store3' store,store3 price
from Products where store3 is not null
group by 1
树节点

讨论 1
我们可以按照下面的定义,求出每一条记录的节点类型。
Root: 没有父节点
Inner: 它是某些节点的父节点,且有非空的父节点
Leaf: 除了上述两种情况以外的节点
# 根节点是没有父节点的节点
SELECT
id, 'Root' AS Type
FROM
tree
WHERE
p_id IS NULL
# 叶子节点是没有孩子节点的节点,且它有父亲节点。
SELECT
id, 'Leaf' AS Type
FROM
tree
WHERE
id NOT IN (SELECT DISTINCT
p_id
FROM
tree
WHERE
p_id IS NOT NULL)
AND p_id IS NOT NULL
# 内部节点是有孩子节点和父节点的节点。
SELECT
id, 'Inner' AS Type
FROM
tree
WHERE
id IN (SELECT DISTINCT
p_id
FROM
tree
WHERE
p_id IS NOT NULL)
AND p_id IS NOT NULL
# 所以本题的一种解法是将这些情况用 UNION 合并起来。
SELECT
id, 'Root' AS Type
FROM
tree
WHERE
p_id IS NULL
UNION
SELECT
id, 'Leaf' AS Type
FROM
tree
WHERE
id NOT IN (SELECT DISTINCT
p_id
FROM
tree
WHERE
p_id IS NOT NULL)
AND p_id IS NOT NULL
UNION
SELECT
id, 'Inner' AS Type
FROM
tree
WHERE
id IN (SELECT DISTINCT
p_id
FROM
tree
WHERE
p_id IS NOT NULL)
AND p_id IS NOT NULL
ORDER BY id;
讨论 2
与上面解法类似,本解法使用流控制语句,流控制语句对基于不同输入产生不同输出非常有效。本方法中,我们使用 CASE语句。
SELECT
id AS `Id`,
CASE
WHEN tree.id = (SELECT atree.id FROM tree atree WHERE atree.p_id IS NULL)
THEN 'Root'
WHEN tree.id IN (SELECT atree.p_id FROM tree atree)
THEN 'Inner'
ELSE 'Leaf'
END AS Type
FROM
tree
ORDER BY `Id`;
讨论 3
# 使用 IF 函数来避免复杂的流控制语句。
SELECT
atree.id,
IF(ISNULL(atree.p_id),
'Root',
IF(atree.id IN (SELECT p_id FROM tree), 'Inner','Leaf')) Type
FROM
tree atree
ORDER BY atree.id
第二高的薪水

讨论 1
使用子查询和 LIMIT 子句
将不同的薪资按降序排序,然后使用 LIMIT 子句获得第二高的薪资。
SELECT DISTINCT
Salary AS SecondHighestSalary
FROM
Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1
# 然而,如果没有这样的第二最高工资,这个解决方案将被判断为 “错误答案”,因为本表可能只有一项记录。为了克服这个问题,我们可以将其作为临时表。
SELECT
(SELECT DISTINCT
Salary
FROM
Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1) AS SecondHighestSalary
;
讨论 2
使用 IFNULL 和 LIMIT 子句
解决 “NULL” 问题的另一种方法是使用 “IFNULL” 函数,如下所示。
SELECT
IFNULL(
(SELECT DISTINCT Salary
FROM Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1),
NULL) AS SecondHighestSalary
讨论 3
本题考查:ifnull()、distinct、DESC、limit n offset m
select ifnull(
(select distinct salary # 薪资重复的都只算一个
from Employee
order by salary DESC # 从大到小
limit 1 offset 1), null
) as SecondHighestSalary
# from Employee 千万不能加这句,否则会把结果重复表的长度次















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









