






一、机器学习概览
1. 机器学习分类简述
1.1 是否在人类监督下进行训练
- 监督
- 用来训练算法的训练数据包含了答案,称为标签.
- 一个典型的监督学习任务是分类,另一个典型任务是预测目标数值(回归)
- 注意,一些回归算法也可以用来进行分类,反之亦然。例如,逻辑回归通常用来进行分类, 它可以生成一个归属某一类的可能性的值
- 包括:
- K近邻算法
- 线性回归
- 逻辑回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
- 非监督
- 训练数据是没有加标签的,系统在没有老师的条 件下进行学习。
- 包括:
- 聚类K
- 均值
- 层次聚类分析(Hierarchical Cluster Analysis,HCA)
- 期望最大值
- 可视化和降维
- 主成分分析(Principal Component Analysis,PCA)
- 核主成分分析
- 局部线性嵌入(Locally-Linear Embedding,LLE)
- t-分布邻域嵌入算法(t-distributed Stochastic Neighbor Embedding,t-SNE)
- 关联性规则学习
- Apriori 算法
- Eclat 算法
- 聚类K
- 半监督
- 一些算法可以处理部分带标签的训练数据,通常是大量不带标签数据加上小部分带标签数,多数半监督学习算法是非监督和监督算法的结合。
- 强化学习
- 强化学习非常不同。学习系统在这里被称为智能体(agent),可以对环境进行观察,选择和 执行动作,获得奖励(负奖励是惩罚,见图 1-12)。然后它必须自己学习哪个是最佳方法 (称为策略,policy),以得到长久的最大奖励。策略决定了智能体在给定情况下应该采取的 行动。
- 是否可以动态渐进学习
1.2 是否能从导入的数据流进行持续学习
- 在线学习
- 在在线学习中,是用数据实例持续地进行训练,可以一次一个或一次几个实例(称为小批 量)。每个学习步骤都很快且廉价,所以系统可以动态地学习到达的新数据
- 在线学习系统的一个重要参数是,它们可以多快地适应数据的改变:这被称为学习速率。如 果你设定一个高学习速率,系统就可以快速适应新数据,但是也会快速忘记老数据(你可不 想让垃圾邮件过滤器只标记最新的垃圾邮件种类)。相反的,如果你设定的学习速率低,系 统的惰性就会强:即,它学的更慢,但对新数据中的噪声或没有代表性的数据点结果不那么 敏感。
- 批量学习
- 在批量学习中,系统不能进行持续学习:必须用所有可用数据进行训练。这通常会占用大量 时间和计算资源,所以一般是线下做的
- 如果你想让一个批量学习系统明白新数据(例如垃圾邮件的新类型),就需要从头训练一个 系统的新版本,使用全部数据集(不仅有新数据也有老数据),然后停掉老系统,换上新系 统。
2. 机器学习过程的主要挑战
因为你的主要任务是选择一个学习算法并用一些数据进行训练,会导致错误的两 件事就是“错误的算法”和“错误的数据”。
2.1 训练数据量不足(样本较少)
机器学习需要大量数据,。即便对于 非常简单的问题,一般也需要数千的样本,对于复杂的问题,比如图像或语音识别,你可能 需要数百万的样本。
2.1.1 没有代表性的训练数据
为了更好地进行归纳推广,让训练数据对新数据具有代表性是非常重要的。
比如下图:
- 各个国家人均GDP与幸福指数的关系(缺失部分国家数据)
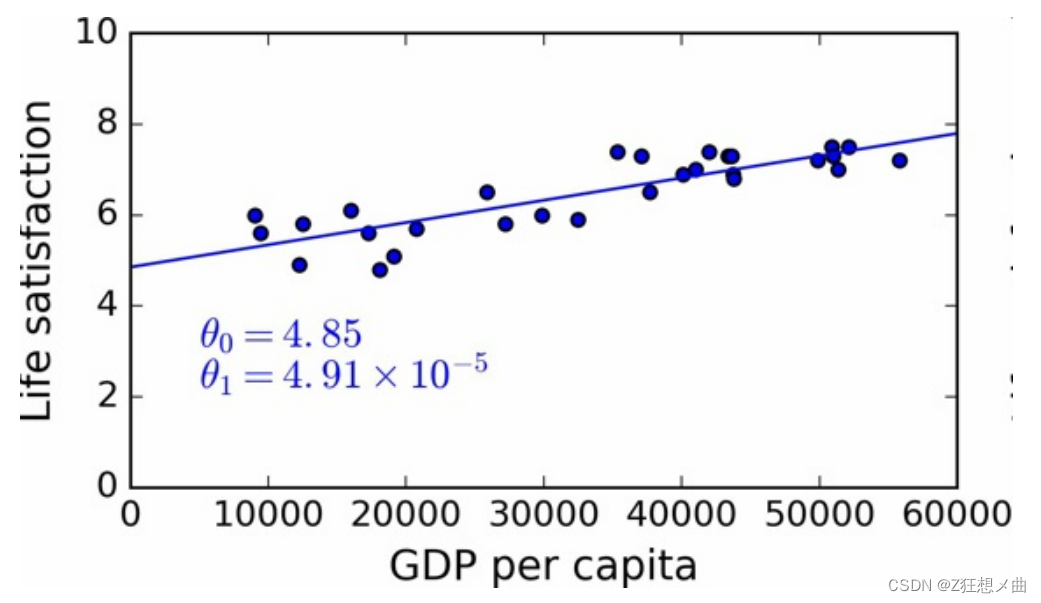
- 各个国家人均GDP与幸福指数的关系(增加缺失部分国家数据)
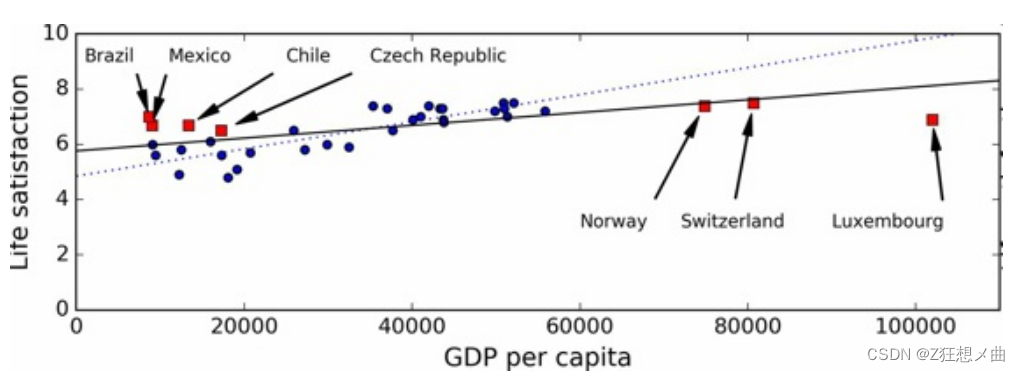 使用了没有代表性的数据集,我们训练了一个不可能得到准确预测的模型,
使用了没有代表性的数据集,我们训练了一个不可能得到准确预测的模型,
使用具有代表性的训练集对于推广到新案例是非常重要的。但是做起来比说起来要难:如果 样本太小,就会有样本噪声(即,会有一定概率包含没有代表性的数据),但是即使是非常 大的样本也可能没有代表性,如果取样方法错误的话。这叫做样本偏差。
2.1.2 低质量数据
很明显,如果训练集中的错误、异常值和噪声(错误测量引入的)太多,系统检测出潜在规 律的难度就会变大,性能就会降低。花费时间对训练数据进行清理是十分重要的。
- 如果一些实例是明显的异常值,最好删掉它们或尝试手工修改错误; 如果一些实例缺少特征(比如,你的 5% 的顾客没有说明年龄),你必须决定是否忽略 这个属性、忽略这些实例、填入缺失值(比如,年龄中位数),或者训练一个含有这个 特征的模型和一个不含有这个特征的模型,等等。
2.1.3 不相关的特征
俗语说:进来的是垃圾,出去的也是垃圾。你的系统只有在训练数据包含足够相关特征、非 相关特征不多的情况下,才能进行学习。机器学习项目成功的关键之一是用好的特征进行训 练。这个过程称作特征工程,包括:
- 特征选择:在所有存在的特征中选取最有用的特征进行训练。
- 特征提取:组合存在的特征,生成一个更有用的特征(如前面看到的,可以使用降维算 法)。
- 收集新数据创建新特征。
2.1.4 过拟合训练数据

图中展示了一个高阶多项式生活满意度模型,它大大过拟合了训练数据。即使它比简单线 性模型在训练数据上表现更好,你会相信它的预测吗?
- 过拟合发生在相对于训练数据的量和噪声,模型过于复杂的情况。可能的解决方案有:
- 简化模型,可以通过选择一个参数更少的模型(比如使用线性模型,而不是高阶多 项式模型)、减少训练数据的属性数、或限制一下模型
- 收集更多的训练数据
- 减小训练数据的噪声(比如,修改数据错误和去除异常值)
限定一个模型以让它更简单,降低过拟合的风险被称作正则化
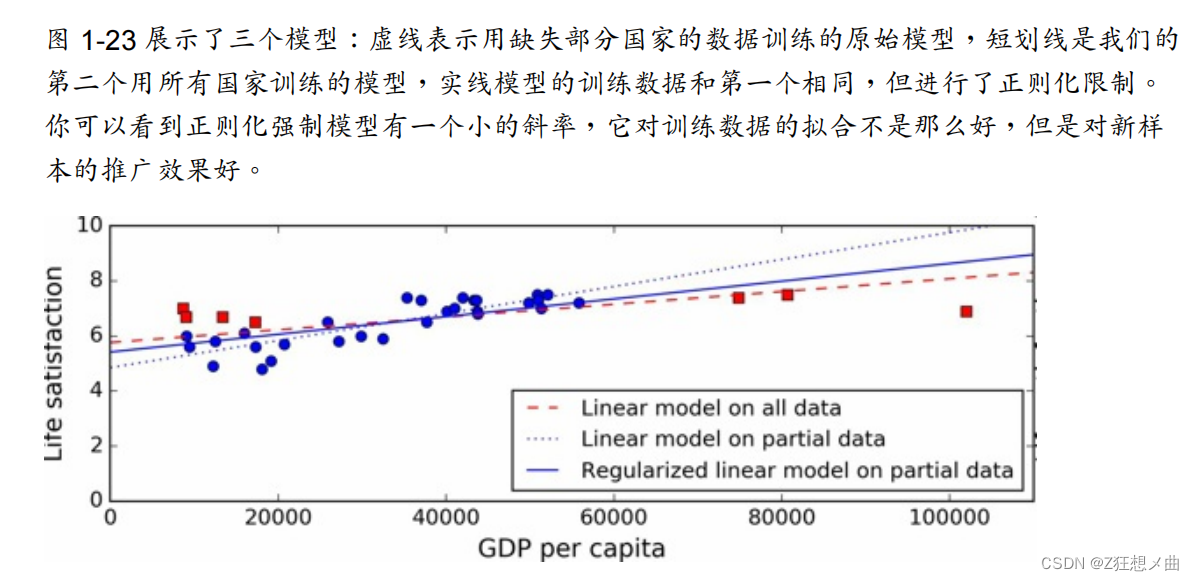
2.1.5 欠拟合训练数据
当你的模型过于简单时就会发生
- 解决这个问题的选项包括:
- 选择一个更强大的模型,带有更多参数
- 用更好的特征训练学习算法(特征工程)
- 减小对模型的限制(比如,减小正则化超参数)
3 总结
- 机器学习是让机器通过学习数据对某些任务做得更好,而不使用确定的代码规则。
- 有许多不同类型的机器学习系统:监督或非监督,批量或在线,基于实例或基于模型, 等等。
- 在机器学习项目中,我们从训练集中收集数据,然后对学习算法进行训练。如果算法是 基于模型的,就调节一些参数,让模型拟合到训练集(即,对训练集本身作出好的预 测),然后希望它对新样本也能有好预测。如果算法是基于实例的,就是用记忆学习样 本,然后用相似度推广到新实例。
- 如果训练集太小、数据没有代表性、含有噪声、或掺有不相关的特征(垃圾进,垃圾 出),系统的性能不会好。最后,模型不能太简单(会发生欠拟合)或太复杂(会发生 过拟合)
4 测试和确认
- 一个模型推广到新样本的效果,唯一的办法就是真正的进行试验。
- 一种方法是将模型 部署到生产环境,观察它的性能(不加测试直接上线)
- 更好的选项是将你的数据分成两个集合:训练集和测试集。即80%数据用于训练模型,20%由于测试模型运行效果。
- 通过模型对测试集的评估,你可以预估这个错误。这个值可以告诉你,你的模型对新样本的性能。
评估一个模型很简单:只要使用测试集。现在假设你在两个模型之间犹豫不决(比如 一个线性模型和一个多项式模型):如何做决定呢?一种方法是两个都训练,然后比较在 测试集上的效果。
现在假设线性模型的效果更好,但是你想做一些正则化以避免过拟合。问题是:如何选择正 则化超参数的值?一种选项是用 100 个不同的超参数训练100个不同的模型。假设你发现最佳 的超参数的推广错误率最低,比如只有 5%。然后就选用这个模型作为生产环境,但是实际中 性能不佳,误差率达到了 15%。发生了什么呢?
答案在于,你在测试集上多次测量了推广误差率,调整了模型和超参数,以使模型最适合这 个集合。这意味着模型对新数据的性能不会高。
通常的办法是使用交叉验证,训练集分成互补的子 集,每个模型用不同的子集训练,再用剩下的子集验证。一旦确定模型类型和超参数,最终 的模型使用这些超参数和全部的训练集进行训练,用测试集得到推广误差率。
5 没有免费午餐公理
模型是观察的简化版本。简化意味着舍弃无法进行推广的表面细节。但是,要确定舍弃 什么数据、保留什么数据,必须要做假设。例如,线性模型的假设是数据基本上是线性 的,实例和模型直线间的距离只是噪音,可以放心忽略。 在一篇 1996 年的著名论文中,David Wolpert 证明,如果完全不对数据做假设,就没有 理由选择一个模型而不选另一个。这称作没有免费午餐(NFL)公理。对于一些数据 集,最佳模型是线性模型,而对其它数据集是神经网络。没有一个模型可以保证效果更 好(如这个公理的名字所示)。确信的唯一方法就是测试所有的模型。因为这是不可能 的,实际中就必须要做一些对数据合理的假设,只评估几个合理的模型。例如,对于简 单任务,你可能是用不同程度的正则化评估线性模型,对于复杂问题,你可能要评估几 个神经网络模型。














 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









