







一、平台
win7 ,编译器pycharm or sublime
二、导包
导入两个包
1、Pillow
2、pytessract
导包方式有两种:
1、直接在windows的cmd里面输入命令
pip install Pillow
pip insatll pytessract
2、 通过pycharm安装包
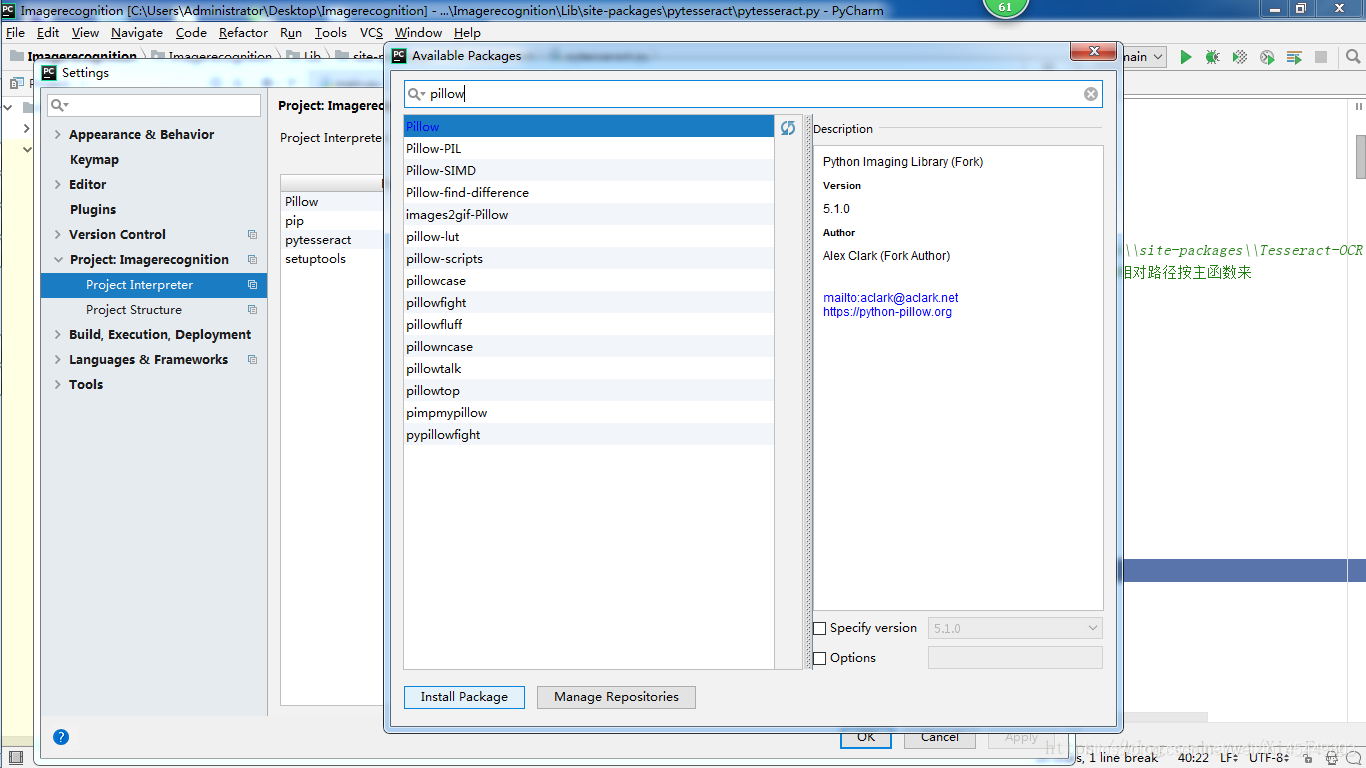
三、安装tesseract-OCR
软件链接:[点击打开链接]
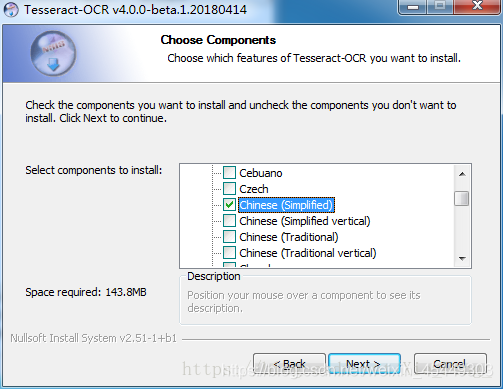
安装遇到如下选择additional language data
选择需要用到的语言包。如中文识别选(chinese(simple))
记下安装目录后面会用到。

四、创建程序 xx.py
找到自己的python环境所在位置
我的在E:\environment\python\Lib\site-packages\pytesseract\
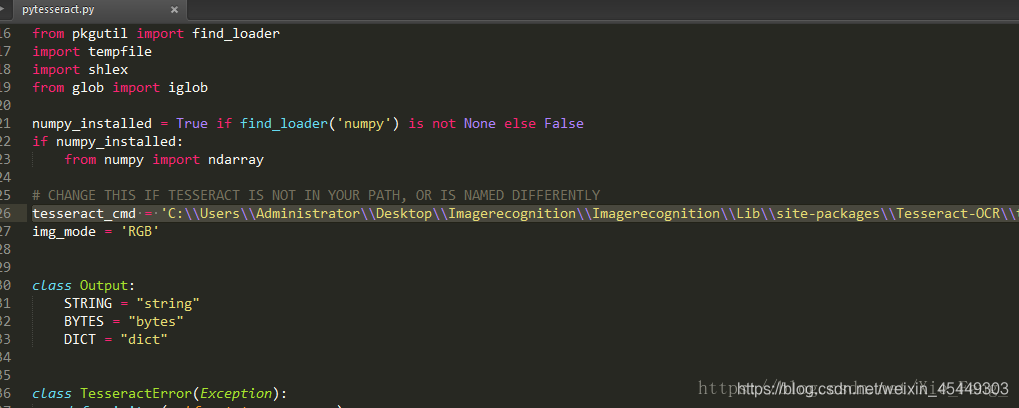
在该目录下找到pytesseract.py 打开更改为:
tesseract_cmd=‘C:\Users\Administrator\Desktop\Imagerecognition\Imagerecognition\Lib\site-packages\Tesseract-OCR\tesseract.exe’ #该路径为安装OCR对应的目录
五、创建一个新的程序,输入如下代码:
from PIL import Image
import pytesseract
image = Image.open(‘7.png’)#输入自己想识别图片的路径
#指定路径,路径为安装的OCR对应的目录
tessdata_dir_config = ‘–tessdata-dir “C:/Users/Administrator/Desktop/Imagerecognition/Imagerecognition/Lib/site-packages/Tesseract-OCR/tessdata”’
text = pytesseract.image_to_string(image,lang=‘chi_sim’,config=tessdata_dir_config)
print(text)
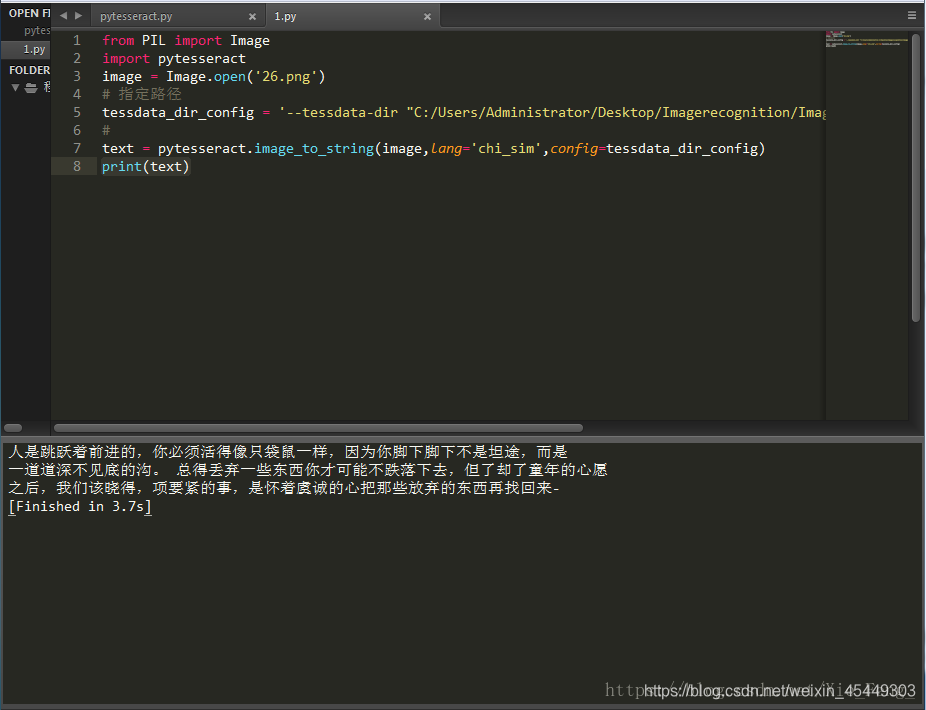
六、运行程序
识别的图片:

识别的结果:
六、PS
对于文字清晰的图片的识别度大概有90%以上。缺点是识别的速度不够快。

















 2071
2071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









