







 本文介绍了飞桨框架的架构演进与核心技术,包括高扩展中间表示PIR、动静统一自动并行技术。飞桨通过动静转换技术实现了动态图与静态图的融合,支持千亿参数模型的混合并行训练。PIR提供了灵活性和可扩展性,自动并行技术简化了分布式训练的复杂性,提升了开发效率。
本文介绍了飞桨框架的架构演进与核心技术,包括高扩展中间表示PIR、动静统一自动并行技术。飞桨通过动静转换技术实现了动态图与静态图的融合,支持千亿参数模型的混合并行训练。PIR提供了灵活性和可扩展性,自动并行技术简化了分布式训练的复杂性,提升了开发效率。

本系列根据Create 2024 百度AI开发者大会「大模型与深度学习技术论坛」嘉宾分享整理。本文整理自百度杰出架构师胡晓光的主题分享——「飞桨框架架构演进与核心技术」。

深度学习框架发展历程
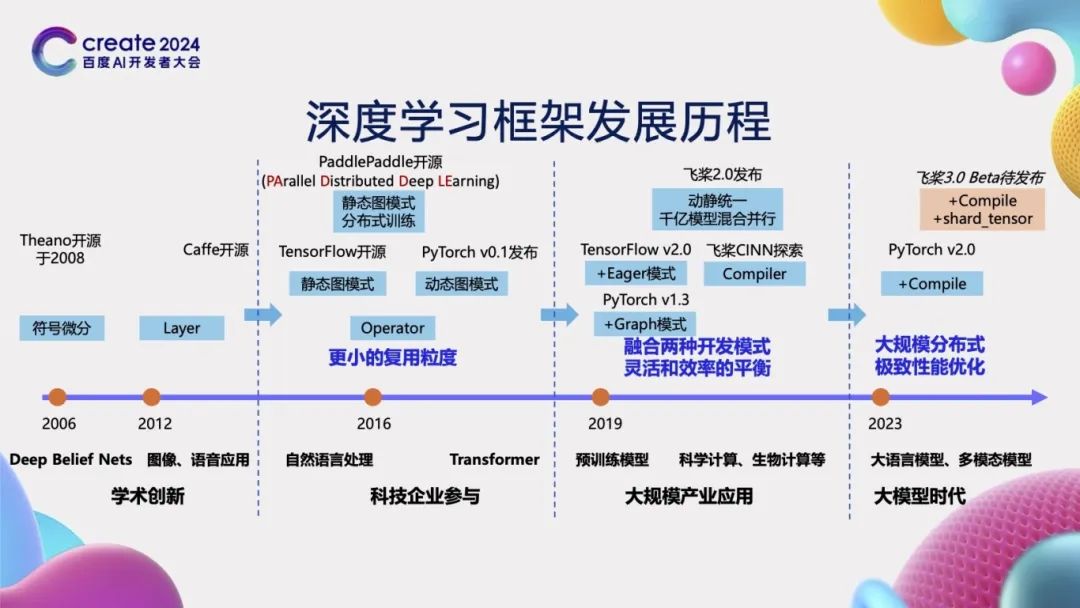
在人工智能发展的初级阶段,模型结构相对简单,无需深度学习框架,可直接通过手写编码实现。然而,随着模型复杂性的逐步提升,深度学习框架变得至关重要。例如,2008年开源的Theano和2013年推出的Caffe等框架,为复杂模型的构建提供了有力支持。在框架开发的初级阶段,它们使用的基本单元粒度较大,如Caffe采用的Layer为基本单元,要求开发者手动编写Layer的前向及反向逻辑,操作难度较大。
自2015年起,越来越多的科技企业投身于深度学习框架的研发,并推出了新的框架。如2015年Google的TensorFlow、2016年百度的飞桨(PaddlePaddle)以及2017年Facebook的PyTorch等相继开源。这些框架凭借其先进的设计理念,引入了Operator以及更细粒度的可复用单元——算子,通过灵活组合这些算子,能够构建出更为复杂的神经网络结构,从而显著提高开发效率。飞桨自开源之初就致力于服务产业实践,支持大规模的分布式训练,其名称“PaddlePaddle”正是“PArallel Distributed Deep LEarning”的缩写,体现了其设计理念。
到了2019年,TensorFlow 2.0引入了Eager模式,而PyTorch 1.3则增加了Graph模式,标志着深度学习框架开始融合动态图与静态图两种不同的开发模式。到了2021年初,飞桨发布了2.0版本,进一步融合了动态图的灵活性与静态图的高效性,同时支持了千亿参数模型的混合并行训练。与此同时,飞桨还开启了神经网络编译器技术CINN(Compiler Infrastructure for Neural Networks)的探索之旅。
随着大模型时代的到来,模型参数规模不断扩大,训练成本也随之攀升,这对深度学习框架在大规模分布式训练和性能优化方面提出了更高的要求。为此,在2023年,PyTorch发布了2.0版本,其核心在于通过引入Compile机制来提升模型运行速度。飞桨也即将在6月推出3.0 Beta版本,其关键特性是增加了编译器性能优化技术和基于张量分割的分布式自动并行技术,以应对当前深度学习领域的新挑战。

大模型时代的深度学习框架
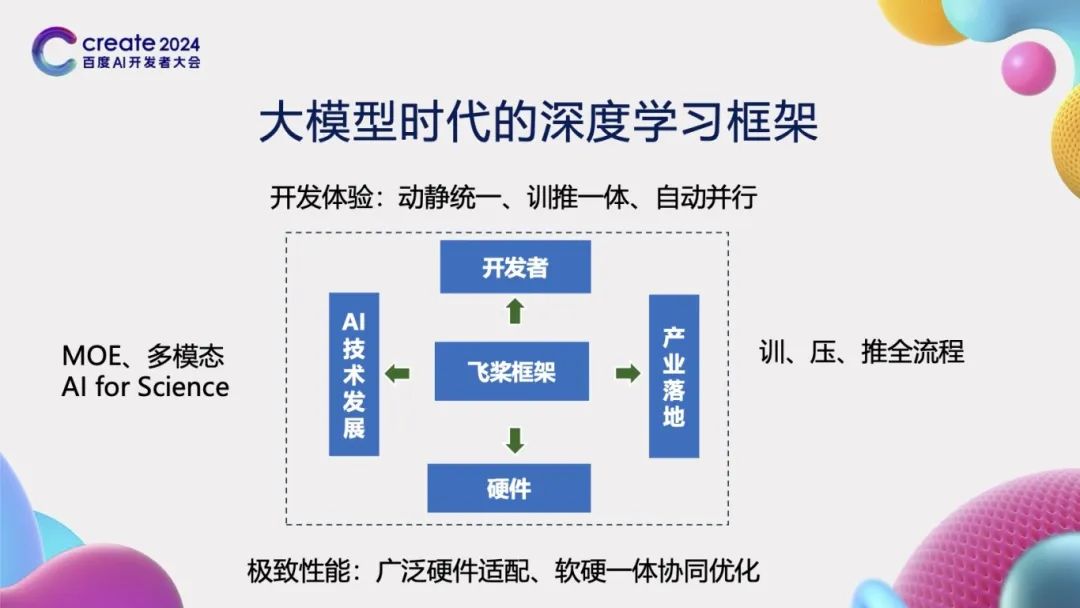
在大模型时代,深度学习框架的设计对于推动人工智能技术的发展至关重要,从以下四个方面进行考虑:
首先,框架向上对接开发者的需求。一个优秀的深度学习框架应当为开发者提供极致的开发体验。这不仅仅意味着提供一个用户友好的开发环境,更重要的是要能够大幅度减少开发者的学习成本和时间成本,同时显著提升开发的便利性。为此,飞桨框架创新性地提出了“动静统一、训推一体、自动并行”的先进概念,极大地提高了开发效率。
其次,框架向下对接硬件。现代深度学习应用往往需要在多样化的硬件平台上运行,因此,框架必须能够兼容并适配各种不同的硬件设备。这要求框架能够智能地隔离不同硬件接口之间的差异,实现广泛的硬件适配性。同时,为了充分发挥硬件的性能,框架还需要具备软硬件协同工作的能力,确保在利用硬件资源时能够达到最优的性能表现。
再者,框架需要考虑到AI技术发展的整体趋势。随着技术的不断进步,诸如MOE(Mixture of Experts)、多模态以及科学智能(AI for Science)等前沿技术逐渐成为新的研究热点。深度学习框架应当能够紧跟这些技术发展的步伐,为研究者提供必要的支持和工具,以推动相关技术的快速发展和应用。
最后,框架需要能够支持产业的实际落地应用。在产业化方面,框架需要具备支持训练、压缩、推理一体化的全流程能力。这意味着,从模型的训练到优化,再到实际部署和推理,框架应当提供一套完整、高效的解决方案,以满足产业界对于深度学习技术的实际
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2667
2667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









