







文章目录
大数据生态圈
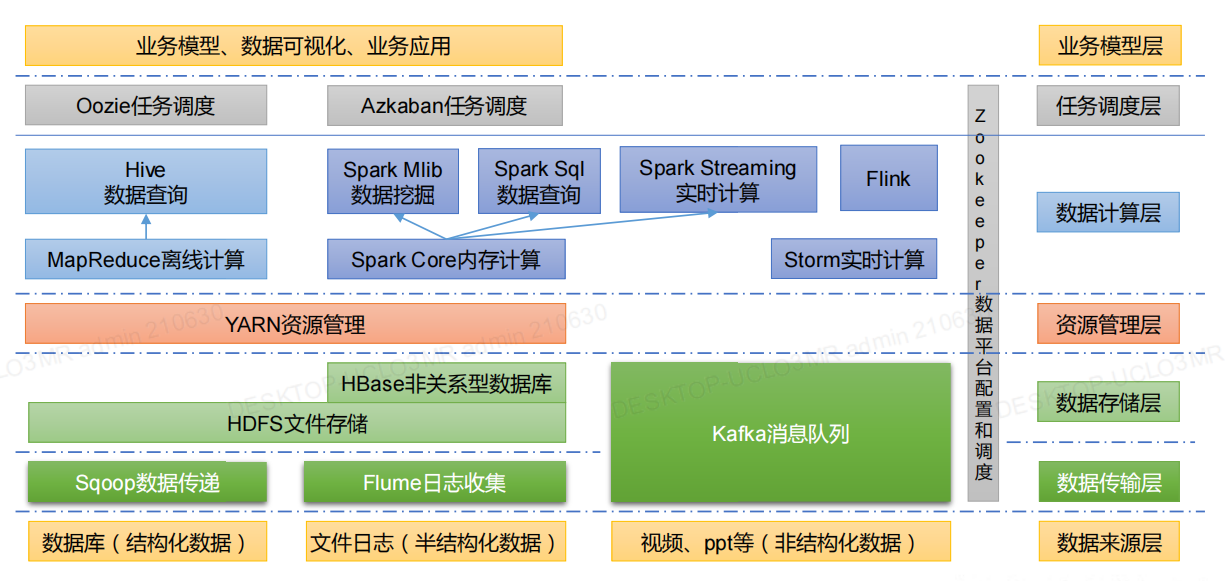
1.大数据基本概念
大数据解决的问题:采集、存储、计算
大数据应用:抖音或者其他推荐、物流仓储等
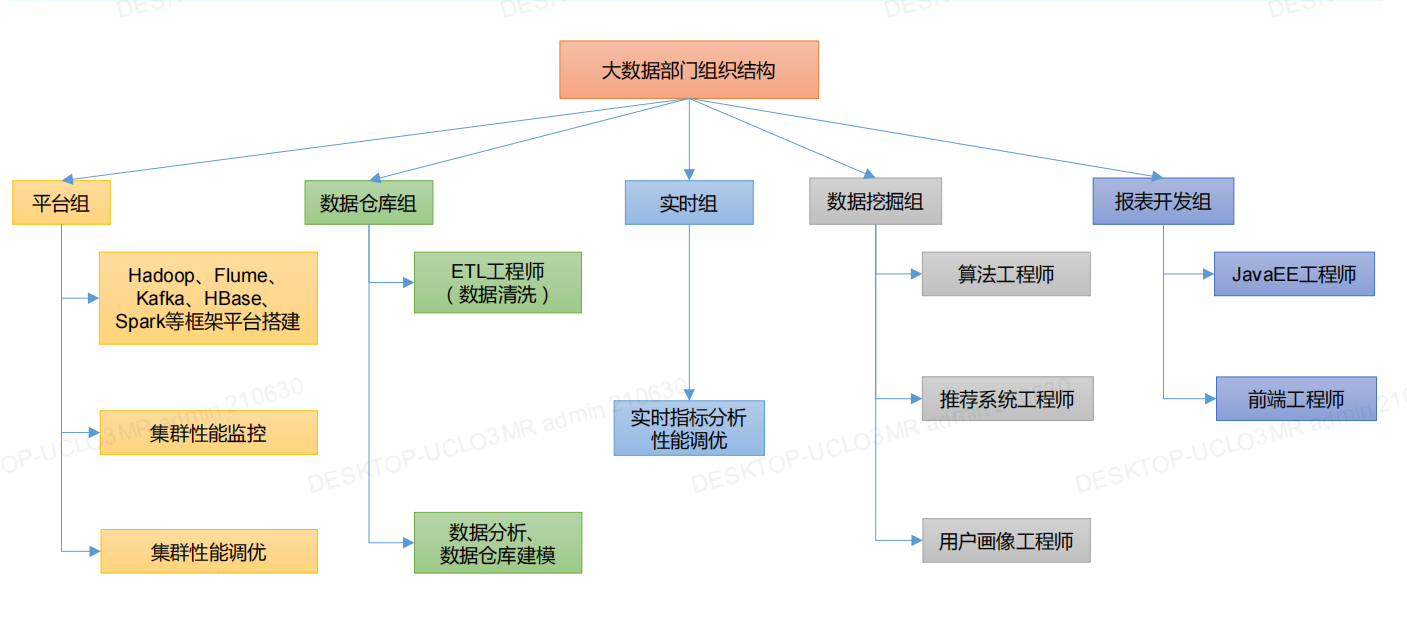
大数据部门组织图
2.大数据之Hadoop
需要安装Hadoop服务端
2.1 HDFS(Hadoop Distributed File System)分布式文件系统
使用场景:适用一次写入多次读出
作用:文件上传下载
public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 连接的集群nn地址
URI uri = new URI("hdfs://hadoop102:8020");
// 创建一个配置文件
Configuration configuration = new Configuration();
// 自定义参数
configuration.set("dfs.replication", "2");
// 用户
String user = "atguigu";
// 1 获取到了客户端对象
fs = FileSystem.get(uri, configuration, user);
}
@After
public void close() throws IOException {
// 3 关闭资源
fs.close();
}
// 创建目录
@Test
public void testmkdir() throws URISyntaxException, IOException, InterruptedException {
// 2 创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan1"));
}
// 文件上传
@Test
public void testPut() throws IOException {
// 参数解读:参数一:表示删除原数据; 参数二:是否允许覆盖;参数三:原数据路径; 参数四:目的地路径
fs.copyFromLocalFile(false, true, new Path("D:\\sunwukong.txt"), new Path("hdfs://hadoop102/xiyou/huaguoshan"));
}
// 文件下载
@Test
public void testGet() throws IOException {
fs.copyToLocalFile(false, new Path("hdfs://hadoop102/a.txt"), new Path("D:\\"), false);
}
}
2.2 MapReduce 分布式运算程序
-
mapper映射拿到数据
-
reducer计算拿到的映射数据
-
提交分布式任务
使用场景:适合PB级以上海量数据的离线处理(不擅长实时计算)
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象
注:如果不序列化那么对象只能在本地计算机的内存中,而不能持久化到硬盘或者传输给其他服务器。
Mapper映射拿到数据
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
// atguigu atguigu
String line = value.toString();
// 2 切割
// atguigu
// atguigu
String[] words = line.split(" ");
// 3 循环写出
for (String word : words) {
// 封装outk
outK.set(word);
// 写出
context.write(outK, outV);
}
}
}
Reducer计算拿到的映射数据
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// atguigu, (1,1)
// 累加
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
// 写出
context.write(key,outV);
}
}
提交分布式任务
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出的kV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\input\\inputword"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop\\output888"));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
2.3 Yarn资源调度器
作用:分布式的操作系统平台。用于给新建任务分配cpu进行处理。可类比线程池调度线程。
3.大数据之Hive
需要安装Hive服务端
Hive 默认使用的元数据库为 derby,需要将 Hive 的元数据地址改为MySQL
作用:Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
- Hive 处理的数据存储在 HDFS
- Hive 分析数据底层的实现是 MapReduce
- 执行程序运行在 Yarn 上
Hive和数据库的对比:
Hive可以简单理解为数据库。但是数据库可以增删改查,Hive不建议改写,只用来作为数仓,读多写少。
数据库通过索引支持数据规模小的,Hive通过MapReduce进行并行计算支持数据规模大的。
4.大数据之HA
HDFS分布式文件系统:适合一次写入,多次读出
注:HA主要是用于使HDFS 和 YARN 高可用。
Hadoop存在的单点故障问题,解决单点故障的方案:
- 搭建手动故障转移的HDFS-HA集群,
- 搭建基于Zookeeper的自动故障转移的HDFS-HA集群
- 搭建基于Zookeeper的自动故障转移的Yarn-HA集群
5.大数据之Flume
需要安装服务端
作用:实时读取服务器本地磁盘数据,将数据写入到HDFS

6.大数据之HBase
HBase的定义:分布式、可扩展的海量数据存储的NoSQL数据库。
7.大数据之Sqoop
用途:Mysql与HDFS(Hive、HBase)等框架之间的数据互导
8.大数据之Azkaban
Azkaban是Linkedin公司推出的一个任务调度系统
注:Ooize 相比 Azkaban 是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。
注:Azkaban中可以配置邮件报警、电话报警…
为什么需要任务调度系统?

## 任务调度。任务A和任务B完成后才能执行任务C
nodes:
- name: jobC
type: command
# jobC 依赖 JobA 和 JobB
dependsOn:
- jobA
- jobB
config:
command: echo "I’m JobC"
- name: jobA
type: command
config:
command: echo "I’m JobA"
- name: jobB
type: command
config:
command: echo "I’m JobB"
9.大数据之Spark
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Hadoop 的 MapReduce 是大家广为熟知的计算框架;但是实时数据还是得用Spark或者Flink
9.1 Scala语言开发
Spark是Scala开发的,所以需要学习Scala;Scala是源于Java,也是需要JAVA虚拟机
9.2 Spark Core
作用:核心编程
9.3 Spark SQL
作用:操作数据库
9.4 Spark Streaming
作用:用于流式数据的处理
10.大数据之Flink
Flink本身框架有Java和Scala,所以可以用Java或者Scala开发
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









