







以淘宝APP数据为原始数据集,通过行业常见行业指标对淘宝用户行为进行分析,从而构建用户画像。
# 导入数据集,查看数据量
import pandas as pd
df = pd.read_csv('taobao.csv')
df.head()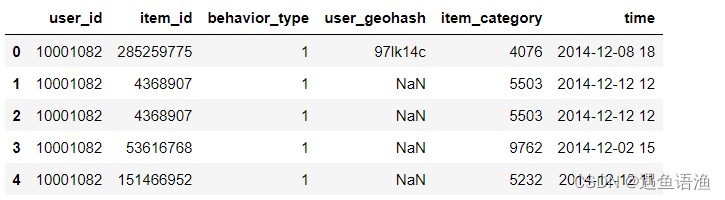
| user_id | 用户ID |
| item_id | 商品ID |
| behavior_type | 用户行为类型(1:点击,2:收藏,3:加购物车,4:支付) |
| user_geohash | 地理位置信息 |
| item_category | 商品类别 |
| time | 用户行为发生时间 |
#导入所需库
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
from datetime import datetime
%matplotlib inline
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False# 数据抽样,并预览数据结构
df = df.sample(frac=0.3,random_state=None).reset_index()
df.head()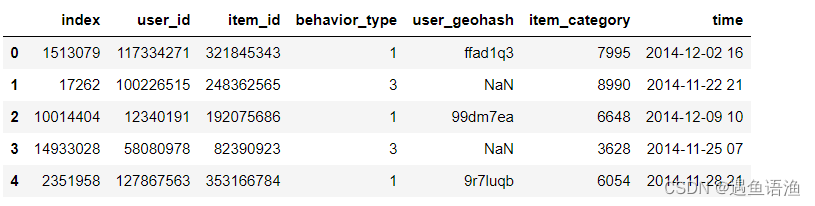
df.info()
# 查看是否存在缺失值
df.isnull().sum() 
# 删除缺失字段
df.drop('user_geohash',axis=1,inplace=True)
df 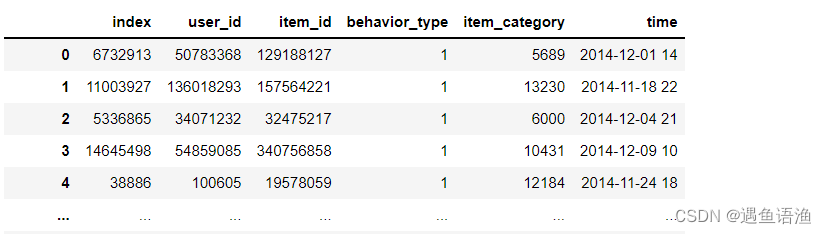
# 将time日期拆分为日期和时间
df['date'] = df['time'].str[0:10]
df['date'] = pd.to_datetime(df['date'],format='%Y-%m-%d')
df['time'] = df['time'].str[11:]
df['time'] = df['time'].astype(int)
df.head() 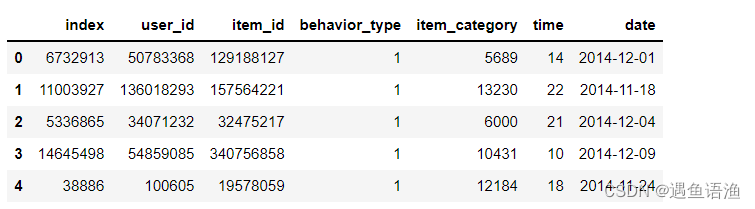
# 构造面板数据,将时段分为凌晨,上午,中午,下午,晚上
df['hour'] = pd.cut(df['time'],bins=[0,5,10,13,18,24],
labels=['凌晨','上午','中午','下午','晚上'])
df.head()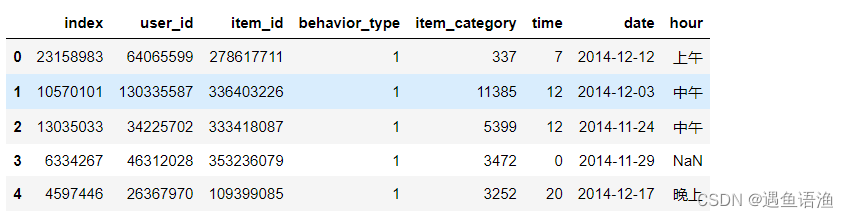
# 生成用户标签列表
users = df['user_id'].unique()
labels = pd.DataFrame(users,columns=['user_id'])
labels 
构建用户行为标签
# 对用户和时段进行分组,统计浏览次数
time_browse = df[df['behavior_type']==1].groupby(['user_id','hour']).item_id.count().reset_index()
time_browse.rename(columns={'item_id':'hour_counts'},inplace=True)
time_browse.head() 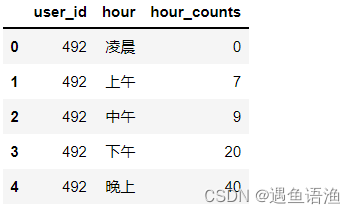
# 统计每个用户浏览次数最多的时间段
time_browse_max = time_browse.groupby('user_id').hour_counts.max().reset_index()
time_browse_max.rename(columns={'hour_counts':'read_counts_max'},inplace=True)
# 两个结果做连接
time_browse = pd.merge(time_browse,time_browse_max,how='left',on='user_id')
time_browse.head()
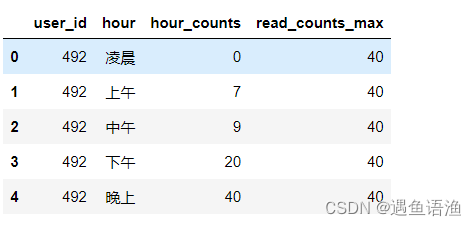
# 选取每个用户浏览次数最多的时间段
time_browse_hour = time_browse.loc[time_browse['hour_counts']==time_browse['read_counts_max'],'hour']
# 存在并列多个时用逗号连接,得到用户活跃时间段标签
time_browse_hour = time_browse_hour.groupby(time_browse['user_id']).aggregate(lambda x:','.join(x)).reset_index()
time_browse_hour.head() 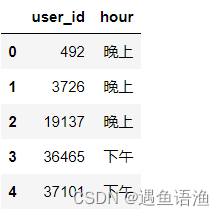
# 将用户浏览活跃时间加入用户标签中
labels = pd.merge(labels,time_browse_hour,how='left',on='user_id')
labels.rename(columns={'hour':'time_browse'},inplace=True)
labels.head() 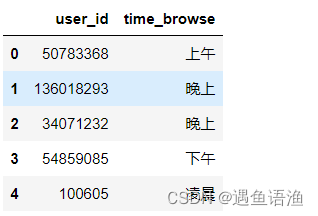
#用户购买活跃时间段标签
time_buy = df[df['behavior_type']==4].groupby(['user_id','hour']).item_id.count().reset_index().rename(columns={'item_id':'hour_counts'})
time_buy_max = time_buy.groupby('user_id').hour_counts.max().reset_index().rename(columns={'hour_counts':'buy_counts_max'})
time_buy = pd.merge(time_buy,time_buy_max,how='left',on='user_id')
time_buy_hour = time_buy.loc[time_buy['hour_counts']==time_buy['buy_counts_max'],'hour']
time_buy_hour = time_buy_hour.groupby(time_buy['user_id']).aggregate(lambda x:','.join(x)).reset_index()
time_buy_hour.head() 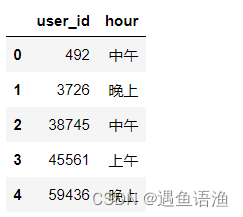
# 将用户购买活跃时间段加入到用户标签表中
labels = pd.merge(labels,time_buy_hour,how='left',on='user_id').rename(columns={'hour':'time_buy'})
labels.head() 
用户浏览最多的商品类别
# 对用户与类别进行分组,统计浏览次数
df_browse = df.loc[df['behavior_type']==1,['user_id','item_id','item_category']]
df_cate_most_browse = df_browse.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_browse.rename(columns={'item_id':'item_category_counts'},inplace=True)
# 每个用户浏览最多的商品类别
df_cate_most_browse_max = df_cate_most_browse.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_browse_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_browse = pd.merge(df_cate_most_browse,df_cate_most_browse_max,how='left',on='user_id')
df_cate_most_browse['item_category'] = df_cate_most_browse['item_category'].astype(str)
# 选取每个用户浏览次数最多的类别,存在并列时,用逗号连接
df_cate_browse = df_cate_most_browse.loc[df_cate_most_browse['item_category_counts']==
df_cate_most_browse['item_category_counts_max'],
'item_category'].groupby(df_cate_most_browse['user_id']).aggregate(lambda x:','.join(x)).reset_index()
# 将用户浏览量最多的类目加入到用户标签中
labels = pd.merge(labels,df_cate_browse,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_browse'},inplace=True)
labels.head() 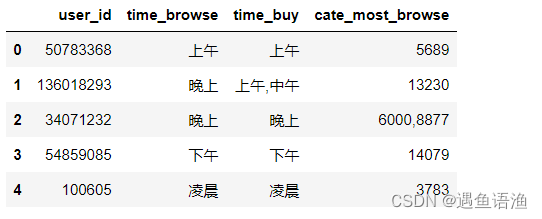















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









