







什么是UNet
U-Net由收缩路径和扩张路径组成。收缩路径是一系列卷积层和汇集层,其中要素地图的分辨率逐渐降低。扩展路径是一系列上采样层和卷积层,其中特征地图的分辨率逐渐增加。
在扩展路径中的每一步,来自收缩路径的对应特征地图与当前特征地图级联。
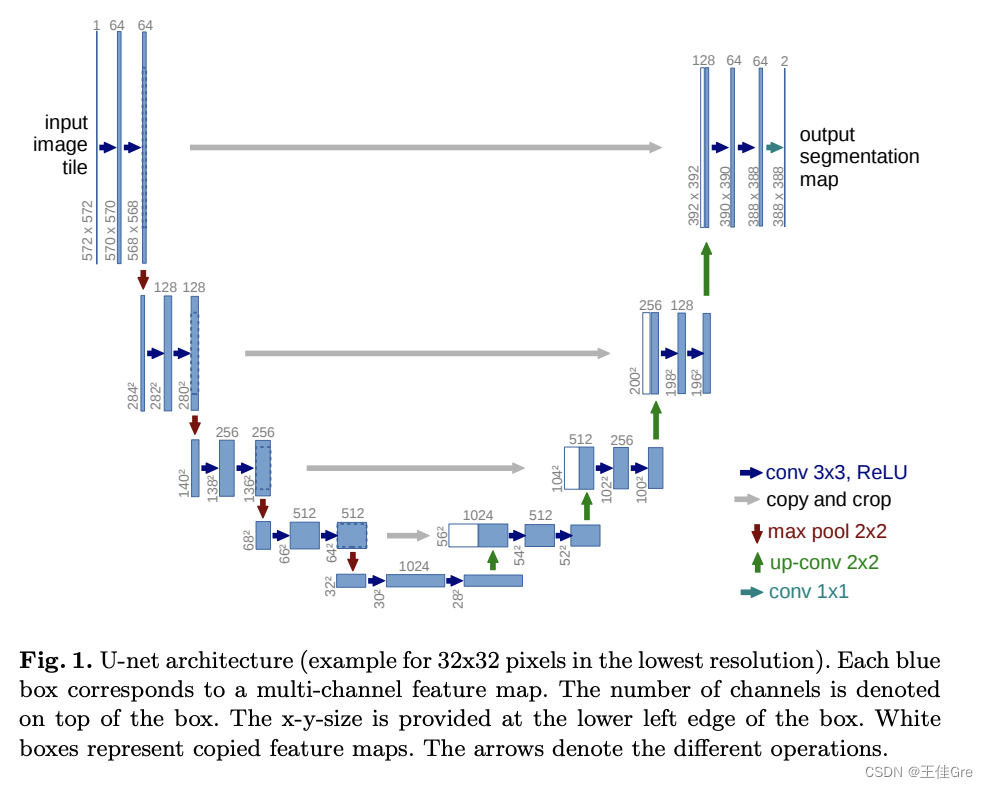
主干结构解析
左边为特征提取网络(编码器),右边为特征融合网络(解码器)
高分辨率—编码—低分辨率—解码—高分辨率
特征提取网络
高分辨率—编码—低分辨率
前半部分是编码, 它的作用是特征提取(获取局部特征,并做图片级分类),得到抽象语义特征
由两个3x3的卷积层(RELU)再加上一个2x2的maxpooling层组成一个下采样的模块,一共经过4次这样的操作
特征融合网络
低分辨率—解码—高分辨率
利用前面编码的抽象特征来恢复到原图尺寸的过程, 最终得到分割结果(掩码图片)
代码:
import torch.nn as nn
import torch
# 编码器(论文中称之为收缩路径)的基本单元
def contracting_block(in_channels, out_channels):
block = torch.nn.Sequential(
# 这里的卷积操作没有使用padding,所以每次卷积后图像的尺寸都会减少2个像素大小
nn.Conv2d(kernel_size=(3, 3), in_channels=in_channels, out_channels=out_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(kernel_size=(3, 3), in_channels=out_channels, out_channels=out_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
return block
# 解码器(论文中称之为扩张路径)的基本单元
class expansive_block(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels):
super(expansive_block, self).__init__()
# 每进行一次反卷积,通道数减半,尺寸扩大2倍
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=(3, 3), stride=2, padding=1,
output_padding=1)
self.block = nn.Sequential(
# 这里的卷积操作没有使用padding,所以每次卷积后图像的尺寸都会减少2个像素大小
nn.Conv2d(kernel_size=(3, 3), in_channels=in_channels, out_channels=mid_channels),
nn.BatchNorm2d(mid_channels),
nn.ReLU(),
nn.Conv2d(kernel_size=(3, 3), in_channels=mid_channels, out_channels=out_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, e, d):
d = self.up(d)
# concat
# e是来自编码器部分的特征图,d是来自解码器部分的特征图,它们的形状都是[B,C,H,W]
diffY = e.size()[2] - d.size()[2]
diffX = e.size()[3] - d.size()[3]
# 裁剪时,先计算e与d在高和宽方向的差距diffY和diffX,然后对e高方向进行裁剪,具体方法是两边分别裁剪diffY的一半,
# 最后对e宽方向进行裁剪,具体方法是两边分别裁剪diffX的一半,
# 具体的裁剪过程见下图一
e = e[:, :, diffY // 2:e.size()[2] - diffY // 2, diffX // 2:e.size()[3] - diffX // 2]
cat = torch.cat([e, d], dim=1) # 在特征通道上进行拼接
out = self.block(cat)
return out
# 最后的输出卷积层
def final_block(in_channels, out_channels):
block = nn.Conv2d(kernel_size=(1, 1), in_channels=in_channels, out_channels=out_channels)
return block
class UNet(nn.Module):
def __init__(self, in_channel, out_channel):
super(UNet, self).__init__()
# 编码器 (Encode)
self.conv_encode1 = contracting_block(in_channels=in_channel, out_channels=64)
self.conv_pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv_encode2 = contracting_block(in_channels=64, out_channels=128)
self.conv_pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv_encode3 = contracting_block(in_channels=128, out_channels=256)
self.conv_pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv_encode4 = contracting_block(in_channels=256, out_channels=512)
self.conv_pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
# 编码器与解码器之间的过渡部分(Bottleneck)
self.bottleneck = nn.Sequential(
nn.Conv2d(kernel_size=(3, 3), in_channels=512, out_channels=1024),
nn.BatchNorm2d(1024),
nn.ReLU(),
nn.Conv2d(kernel_size=(3, 3), in_channels=1024, out_channels=1024),
nn.BatchNorm2d(1024),
nn.ReLU()
)
# 解码器(Decode)
self.conv_decode4 = expansive_block(1024, 512, 512)
self.conv_decode3 = expansive_block(512, 256, 256)
self.conv_decode2 = expansive_block(256, 128, 128)
self.conv_decode1 = expansive_block(128, 64, 64)
self.final_layer = final_block(64, out_channel)
def forward(self, x):
# Encode
encode_block1 = self.conv_encode1(x)
encode_pool1 = self.conv_pool1(encode_block1)
encode_block2 = self.conv_encode2(encode_pool1)
encode_pool2 = self.conv_pool2(encode_block2)
encode_block3 = self.conv_encode3(encode_pool2)
encode_pool3 = self.conv_pool3(encode_block3)
encode_block4 = self.conv_encode4(encode_pool3)
encode_pool4 = self.conv_pool4(encode_block4)
# Bottleneck
bottleneck = self.bottleneck(encode_pool4)
# Decode
decode_block4 = self.conv_decode4(encode_block4, bottleneck)
decode_block3 = self.conv_decode3(encode_block3, decode_block4)
decode_block2 = self.conv_decode2(encode_block2, decode_block3)
decode_block1 = self.conv_decode1(encode_block1, decode_block2)
final_layer = self.final_layer(decode_block1)
return final_layer
if __name__ == '__main__':
image = torch.rand((1, 3, 572, 572))
unet = UNet(in_channel=3, out_channel=2)
mask = unet(image)
print(mask.shape)
#输出结果:
torch.Size([1, 2, 388, 388])















 2028
2028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









