






Abstract
我们提出了CrossSum,一个大规模的跨语言摘要数据集,包括1.68百万篇文章和摘要样本,涵盖了1500多种语言对。我们通过从多语言抽象摘要数据集中进行跨语言检索,将不同语言撰写的平行文章进行对齐,创建了CrossSum,并进行了受控的人工评估以验证其质量。我们提出了一个多阶段数据抽样算法,用于有效训练能够总结任何目标语言文章的跨语言摘要模型。我们还引入了LaSE,一种基于嵌入的度量标准,用于自动评估模型生成的摘要。与ROUGE不同,LaSE与之强相关,并且可以在目标语言缺乏参考文献的情况下可靠地测量。ROUGE和LaSE的性能表明,我们提出的模型在一致性上优于基线模型。据我们所知,CrossSum是最大的跨语言摘要数据集,也是第一个不以英语为中心的跨语言摘要数据集。我们将发布该数据集、训练和评估脚本以及模型,以推动未来跨语言摘要研究的发展。相关资源可以在以下网址找到:https://github.com/csebuetnlp/CrossSum。
1.Introduction
跨语言摘要(以下简称XLS)是将另一种语言的源文本转化为目标语言摘要的任务。这个任务具有挑战性,因为它将摘要和翻译结合到一个任务中,这两个任务本身都是具有挑战性的。早期的XLS方法采用了管道方法,如先翻译后摘要(Leuski等,2003)和先摘要后翻译(Wan等,2010)。这些方法不仅在计算上昂贵,需要使用多个模型,而且还容易出现错误传播问题(Zhu等,2019),从一个模型传播到另一个模型,降低了整体性能。
为了使XLS在高资源语言之外变得更加普及,本文引入了CrossSum,一个大规模的XLS数据集,包括1,500多种语言对的1.68百万篇文章和摘要样本。我们通过从多语言XL-Sum(Hasan等,2021)数据集中进行跨语言检索,将不同语言中撰写的平行文章进行对齐。我们引入并严格研究了"诱导对"和"隐式泄漏"的概念,以增加数据集的覆盖范围,同时确保最大的质量。我们还进行了对跨Sum的受控人工评估,涵盖了从高资源到低资源的九种语言,并展示了对齐结果的高度准确性。
我们设计了MLS,一种多阶段语言抽样算法,成功训练能够为任何源语言的输入文章生成任何目标语言摘要的模型,这些语言都出现在训练数据集中。首次,我们使用CrossSum在广泛和多样的语言集上进行XLS,而无需依赖英语作为独立的中间语言,一贯优于多对一和一对多模型,以及先摘要后翻译的基线模型。
我们提出了LaSE,一种基于嵌入的度量标准,用于在目标语言可能没有参考摘要但可能在其他语言中可用时评估摘要,这可能为评估低资源语言打开新的可能性。此外,我们通过LaSE与ROUGE(Lin,2004),评估文本摘要系统的事实度量标准之间的高相关性,展示了LaSE的可靠性。
据我们所知,CrossSum是目前公开可用的最大的摘要XLS数据集,无论是在样本数量还是语言对数量方面。我们发布了数据集、训练和评估脚本以及模型,希望这些资源能够鼓励社区将XLS的界限推广到英语和其他高资源语言之外。
2.CrossSum数据集
策划高质量的XLS数据集最直接的方法是通过众包(crowd-sourcing)(Nguyen和Daumé III,2019)。然而,可能很难找到具有对低资源语言或不常见语言对的专业掌握的众包工作者。此外,由于众包的时间和预算限制,可伸缩性问题可能会出现。因此,合成方法(Zhu等,2019)和自动方法(Ladhak等,2020;Perez-Beltrachini和Lapata,2021)在众包之外逐渐流行。
XLS数据集的自动策划方法简单地将源语言中的文章A与以不同目标语言撰写的平行文章B的摘要配对(图1),假设存在一个多语言数据集,其中不同语言具有相同的内容。两个当代作品已经编制了大规模的多语言摘要数据集,分别是XL-Sum(Hasan等,2021)(包含45种语言的1.35百万样本)和MassiveSumm(Varab和Schluter,2021)(包含92种语言的28.8百万样本)。尽管MassiveSumm比其他数据集大得多,但它不是公开可用的。由于公开可用性对于促进开放研究至关重要,我们选择了分布在非商业许可下的XL-Sum。此外,XL-Sum的所有文章都来自单一来源,BBC新闻。我们观察到BBC在不同语言中发布类似的新闻内容并采用相似的摘要策略。因此,采用XL-Sum将提高文章摘要对的质量和数量。

图1:来自CrossSum的一组示例文章-摘要对,文章用日语撰写,摘要用孟加拉语撰写。我们在括号内将文本翻译成英语,以便更好地理解。与摘要相关的文章中的单词和短语以不同颜色标出。
与以前的自动方法不同,XL-Sum中没有平行文章之间的明确链接。幸运的是,与语言无关的句子表示方法(Artetxe和Schwenk,2019a;Feng等,2022)在跨语言文本挖掘方面取得了最新技术成果(Artetxe和Schwenk,2019b),因此,我们使用它们来搜索跨语言相同的内容。为了简化,我们只对摘要进行搜索。为确保最大质量,我们设置了两个条件,要求语言A中的摘要
S
A
S_A
SA与语言B中的另一个摘要
S
B
S_B
SB对齐:
1.
S
B
S_B
SB必须是
S
A
S_A
SA在B语言中的所有摘要中最近的邻居,反之亦然。
2.
S
A
S_A
SA和
S
B
S_B
SB之间的相似度必须超过阈值τ。
摘要对的相似度由它们的“无语言BERT句子嵌入”(LaBSE)(Feng等,2022)的内积来衡量(对于输入文本序列的单位向量)。我们经验性地将相似度阈值设置为在BUCC挖掘任务(Zweigenbaum等,2017)中使它们各自的F1分数最大化的所有语言的平均值(τ = 0.7437)。
诱导对
诱导对:我们观察到,许多摘要对,尽管在它们的语言对中是最近的邻居,却因为阈值τ而被过滤掉。有趣的是,它们两者与不同语言中的同一摘要对齐。此外,如果它们的语言是远程或低资源的,这些对是普遍存在的。LaBSE使用对比学习(Guo等,2018;Yang等,2019)来对平行句子进行排名,而非平行句子。由于平行对主要出现在高资源和语言接近的语言中,我们假设LaBSE无法为来自非平行语言的句子分配高相似度。
为了将这些对纳入CrossSum,我们引入了"诱导对"的概念。形式上,如果两个语言A和B中的摘要
S
A
S_A
SA、
S
B
S_B
SB是彼此的最近邻居,它们的相似性分数低于τ,且它们都与语言C中的摘要
S
C
S_C
SC对齐,或者通过对齐对(
S
A
S_A
SA,
S
C
S_C
SC),(
S
C
S_C
SC,
S
D
S_D
SD),…,(
S
Y
S_Y
SY,
S
Z
S_Z
SZ),(
S
Z
S_Z
SZ,
S
B
S_B
SB)在语言{C,D,…,Y,Z}中的链对齐,则
S
A
S_A
SA和
S
B
S_B
SB是"诱导对"。
因此,我们通过一个简单的基于图的算法将"诱导对"纳入CrossSum。首先,**我们将所有摘要表示为图中的顶点,并在两个摘要对齐时在两个顶点之间绘制一条边。然后,我们找到图中的连通分量,并在一个连通分量中的所有顶点之间绘制边(即"诱导对")。**为了确保质量,在计算"诱导对"之前,我们使用最大流最小割定理(Dantzig和Fulkerson,1955),将相似性分数作为边权重,限制每个连通分量的大小不超过50个顶点(理想情况下,一个连通分量应该最多有45个顶点,每种语言中各一个摘要),并将它们的最小接受阈值设置为
τ
′
←
τ
−
0.10
τ' ← τ - 0.10
τ′←τ−0.10。
最后,我们汇总了最初对齐的对和诱导对,创建了CrossSum数据集。附录中的图6显示了CrossSum中所有语言对的文章摘要统计数据。从图中可以明显看出,CrossSum并不仅围绕英语语言展开,而是分布在多种语言之间。
隐式泄漏:最初,我们尊重了原始XL-Sum的分割,并通过训练一个多对一模型(任何源语言中的文章都被摘要成一个目标语言)来进行了CrossSum的初步评估。在评估过程中,我们发现许多语言对的ROUGE-2分数非常高(约40分),甚至有些语言对的ROUGE-2分数高达60分(图2)。相比之下,Hasan等人(2021)报告了多语言摘要任务中10-20分的ROUGE-2分数。
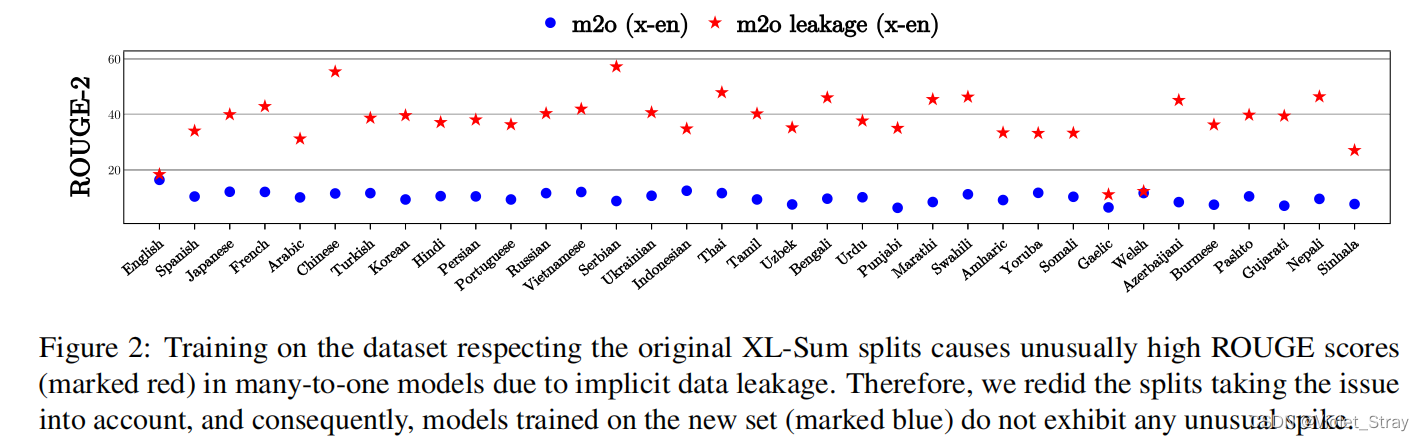
图2:尊重原始XL-Sum的分割进行数据集训练导致多对一模型的ROUGE分数异常高(标为红色),这是由于隐式数据泄漏引起的。因此,我们重新进行了数据集分割,考虑了这个问题,因此在新数据集上训练的模型(标为蓝色)不会出现任何异常的波动。
我们检查了模型的输出,发现许多摘要与参考摘要相同。经过更仔细的检查,我们发现它们对应的文章在训练集中有一个与之对应的平行文本,尽管是用另一种语言编写的。在训练过程中,模型能够对齐平行文章的表示(尽管是用不同语言编写的),并通过从训练样本中记忆来生成相同的输出。虽然无疑应该赞扬模型能够进行这些跨语言映射,但这对于基准测试来说并不理想,因为这会创建异常高的ROUGE分数。我们将这种现象称为"隐式泄漏",并进行了新的数据集分割以避免这种情况。在继续之前,我们使用语义相似性对XL-Sum数据集进行了去重,如果语言A中的两个摘要 S A S_A SA和 S ′ A S′_A S′A的LaBSE表示的相似度超过0.95,我们认为它们是彼此的重复。我们利用先前提到的组件图来处理泄漏,并将源自CrossSum训练集的单一组件中的所有文章摘要对分配为所有语言对的80%-10%-10%分割。由于平行文章不再出现在一个训练集和另一个dev/test集中,因此不再观察到泄漏现象(图2)。我们通过检查模型的输出进一步验证了这一点,并没有发现完全相同的副本。
3 CrossSum的人工评估
为了验证我们的自动对齐流程的有效性,我们进行了人工评估,研究了跨语言对齐的质量。
我们从包括高资源到低资源的九种语言中选择了所有可能的语言对组合,以不同的对配置(例如高-高,低-高,低-低)来评估对齐质量,这些对配置是根据Joshi等人(2020)的语言多样性分类而来。我们选择了三种高资源语言,英语、阿拉伯语和(简化的)中文(类别4和5);三种中资源语言,印尼语、孟加拉语和乌尔都语(类别3);和三种低资源语言,旁遮普语、斯瓦希里语和普什图语(类别1和2),作为代表性语言,并从每种语言对中随机抽取了五十个跨语言摘要对齐样本进行标注。对于这些对,要进行直接评估需要两种语言都具备双语能力的注释员,这对于远亲语言来说实际上是难以实现的(例如孟加拉语-斯瓦希里语),因此我们在注释中采用了一种中继方法,以应对不包括英语的语言对。对于一个语言对
(
l
1
−
l
2
)
(l_1 - l_2)
(l1−l2),其中
l
1
=
e
n
,
l
2
=
e
n
l_1 = en,l_2 = en
l1=en,l2=en,我们采样对齐(x, y),使得
∃
(
x
,
e
)
∈
(
l
1
−
e
n
)
∃(x, e)∈(l1 - en)
∃(x,e)∈(l1−en)和
∃
(
y
,
e
)
∈
(
l
2
−
e
n
)
∃(y, e)∈(l_2 - en)
∃(y,e)∈(l2−en),其中e是英语文章。换句话说,我们确保采样的跨语言对的两篇文章都有一个与英语文章相对应的跨语言对。如果(x, e)和(y, e)都是正确的,那么对齐(x, y)将被视为正确。这个表述将原始问题简化为注释来自不包括英语的先前选择的语言的语言对
(
l
1
−
e
n
)
(l_1 - en)
(l1−en)和
(
l
2
−
e
n
)
(l_2 - en)
(l2−en)的样本。
我们聘请了精通感兴趣语言和英语的双语能力专家注释员。对于其中一种语言是英语的每个语言对,我们安排了两名注释员进行标注。我们向他们呈现了跨语言对的相应摘要(以及可选的文章本身),并提出以下问题以获取是/否的答案:
“所提供的序列是否可以被视为相同文章的摘要?”
如果两名注释员都判断一个序列对是有效的,我们将其视为准确。我们在图3中展示了语言对的对齐准确性。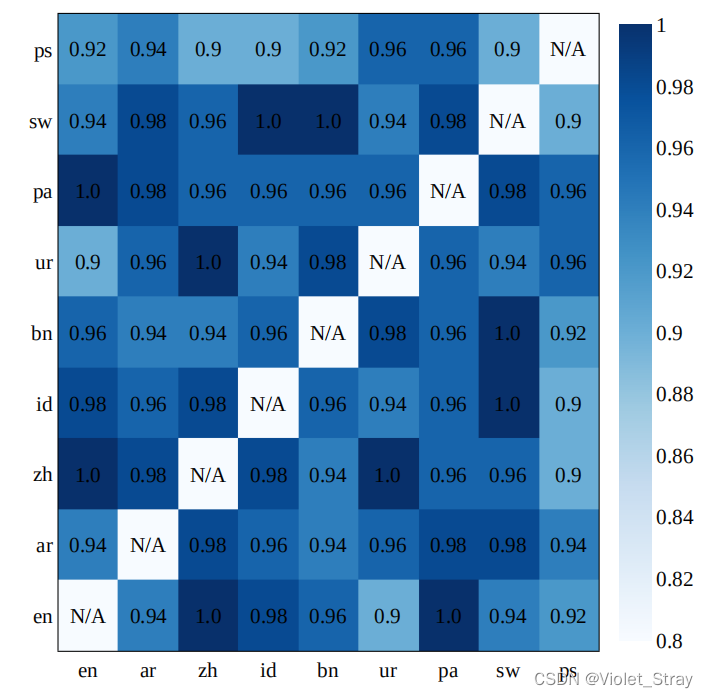
图3:显示了通过人工评估获得的不同语言对的对齐准确性的热图。
从图中可以看出,注释员认为对齐的摘要非常准确,平均准确性为95.67%。我们使用Cohen’s Kappa(Cohen,1960)来建立注释员之间的一致性,并在附录的表3中显示了相应的统计数据。
4.训练和评估方法论
在本节中,我们将讨论用于训练跨语言文本生成模型的多阶段采样策略,以及我们提出的用于评估模型生成摘要的度量标准。
4.1多阶段语言采样(MLS)
从图6可以看出,CrossSum的分布极不均衡。因此,如果不对低资源语言进行上采样,直接训练可能会导致它们的性能下降。Conneau等人(2020)在多语言预训练中使用了概率平滑来进行上采样,并从一个语言中抽取了一个批次的所有示例。然而,将这种技术扩展到CrossSum中的语言对会导致许多批次包含重复的示例,因为与实际使用的批次大小相比,许多语言对的训练示例总数不足(例如,Conneau等人(2020)使用的批次大小为256,超过了CrossSum中将近1,000个语言对的训练集大小)。同时,由于计算资源的限制,许多语言对在训练过程中可能不会被抽样。为了解决这个问题,我们改进了他们的方法,引入了一种多阶段语言采样算法(MLS),以确保批次的目标摘要来自相同的语言。
设
L
1
L_1
L1、
L
2
L_2
L2、…、
L
n
L_n
Ln是跨语言源-目标数据集的语言,
c
(
i
j
)
c_(ij)
c(ij)是目标来自
L
i
L_i
Li,源来自
L
j
L_j
Lj的训练样本数量。我们通过以下方式计算每个目标语言
L
i
L_i
Li的概率
p
i
p_i
pi:
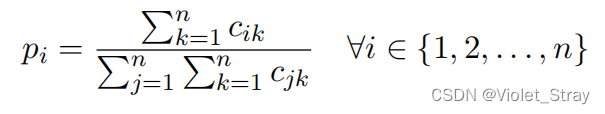
然后,我们使用一个指数平滑因子α,对这些概率进行归一化。
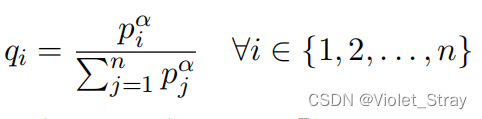
给定目标语言
L
i
L_i
Li,我们现在计算源语言
L
j
L_j
Lj的概率,表示为
p
(
j
∣
i
)
p_(j|i)
p(j∣i)。
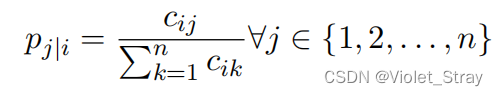
我们再次使用平滑因子β对
p
(
j
∣
i
)
p_(j|i)
p(j∣i)进行平滑处理,得到归一化的概率。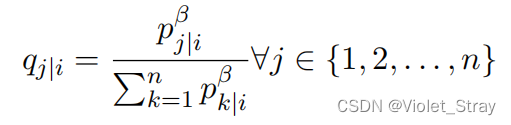
使用这些概率,我们在算法1中描述了MLS算法中的训练过程。请注意,提出的算法可以应用于任何源语言和目标语言都不均衡的跨语言seq2seq任务。
4.2 跨语言评估摘要
可靠评估模型生成摘要需要足够数量的参考样本。然而,对于许多CrossSum语言对来说,即使是训练集也很小,更不用说测试集了(中位数大小仅为33)。例如,日本-孟加拉语言对只有34个测试样本,这对于可靠评估来说太少了。但是,日语和孟加拉语的同语测试集大小都接近于1,000。因此,能够针对源语言编写的参考摘要进行评估将通过利用源语言的同语测试集来缓解这一不足问题。
为了实现这一目的,需要不依赖词汇重叠(不同于ROUGE)的跨语言相似性度量标准。最近,基于嵌入的相似性度量标准(Zhang等,2020;Zhao等,2019)越来越受欢迎。我们从中汲取灵感,并设计了一种可以以独立于语言的方式有效度量跨语言相似性的相似性度量标准。我们考虑了三个关键因素:
- 含义相似性:生成的摘要和参考摘要应该传达相同的含义,不考虑它们的语言。就像我们在第2节中的对齐过程一样,我们使用LaBSE来计算生成摘要(
s
(
g
e
n
)
s_(gen)
s(gen))和参考摘要(
s
(
r
e
f
)
s_(ref)
s(ref))之间的含义相似性:
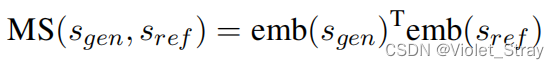
其中,emb(s)表示LaBSE对输入文本s的嵌入向量输出。 - 语言置信度:该度量标准应该能够以高置信度识别生成的摘要确实是在目标语言中生成的。因此,我们使用fastText语言识别分类器(Joulin等,2017)来获取生成摘要的语言概率分布,并定义语言置信度(LC)如下:
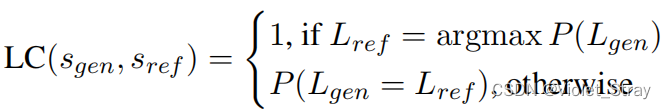
- 长度惩罚:生成的摘要不应该过长,而且度量标准应该对过长的摘要进行惩罚。虽然基于模型的度量标准可以指示生成的摘要与其参考摘要和语言的相似程度,但不清楚它们如何用来确定摘要的简洁性。因此,我们改进了BLEU(Papineni等,2002)的简洁性惩罚来测量长度惩罚:
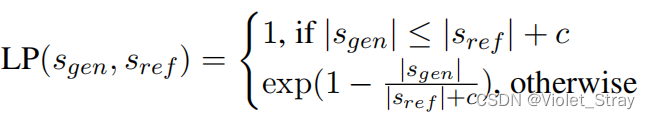
s g e n s_gen sgen和 s r e f s_ref sref可能不是相同的语言,不同语言的平行文本可能在长度上有所变化。因此,我们使用长度偏移c来避免对略长于参考摘要的生成摘要进行轻微的惩罚。通过检查不同语言的平均摘要长度的标准偏差,我们设置c = 6。
最后,我们定义了我们的度量标准,即"无语言偏见的摘要评估"(LaSE)分数,如下所示。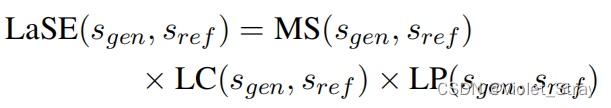
5. 实验与讨论
本节的目标是为了建立能够为来自任何源语言的输入文章生成任何目标语言摘要的模型,这种“多对多”模型(简称m2m)具有非常高的需求。然而,可能并不是这样的“多对多”模型会优于许多使用广泛的XLS(交叉语言总结)实践中的“多对一”(m2o)或“一对多”(o2m)模型。在本节中,我们通过使用第4节中的MLS算法培训的所有可能的语言对的样本来确定,相对于相同训练步骤的m2o、o2m和总结-翻译(s.+t.)基线,提出的m2m模型能够始终表现出色。
除了提出的m2m模型之外,我们还使用五种不同的m2o和o2m模型,这些模型使用了五种使用广泛的和在语言类型上具有多样性的中间语言(即m2o和o2m中的“one”):英语、中文(简体)、印地语、阿拉伯语和俄语。作为另一个基准,我们使用了一个总结-翻译的流程。由于微调预训练语言模型(Devlin等,2019;Xue等,2021a)在单语和多语文本摘要方面表现出了最新的结果(Rothe等,2020;Hasan等,2021),因此,我们通过为每个模型提供明确的跨语言监督来微调每个模型,使用了预训练的mT5(Xue等,2021a)。我们在图4和图5中显示了ROUGE-2 F1和LaSE的结果。
结果表明,m2m模型在所有测试的语言上一直优于m2o、o2m和s.+t.,在所有语言测试中,平均ROUGE-2(LaSE)分数为8.15(57.15),高出s.+t. 3.12(9.02)。此外,与以目标为中心的o2m模型相比,m2m模型在以目标为中心的语言对中的得分为1.80(5.84),在以源为中心的语言对中的得分为6.52(51.80)。在检查模型输出时,我们发现m2o模型能够生成非平凡的摘要。相比之下,o2m模型未能生成跨语言摘要,对于所有目标,执行的是语言内摘要(摘要的语言与其输入文章的语言相同)。我们假设在批处理中变化的目标语言会妨碍解码器从特定语言生成的能力,可能是因为批处理中的目标语言的多样性过大(在附录E中进一步讨论了这一点)。s.+t. 在高资源语言上表现良好,但在低资源语言上表现不佳。这被证明是流水线中使用的翻译模型的限制。
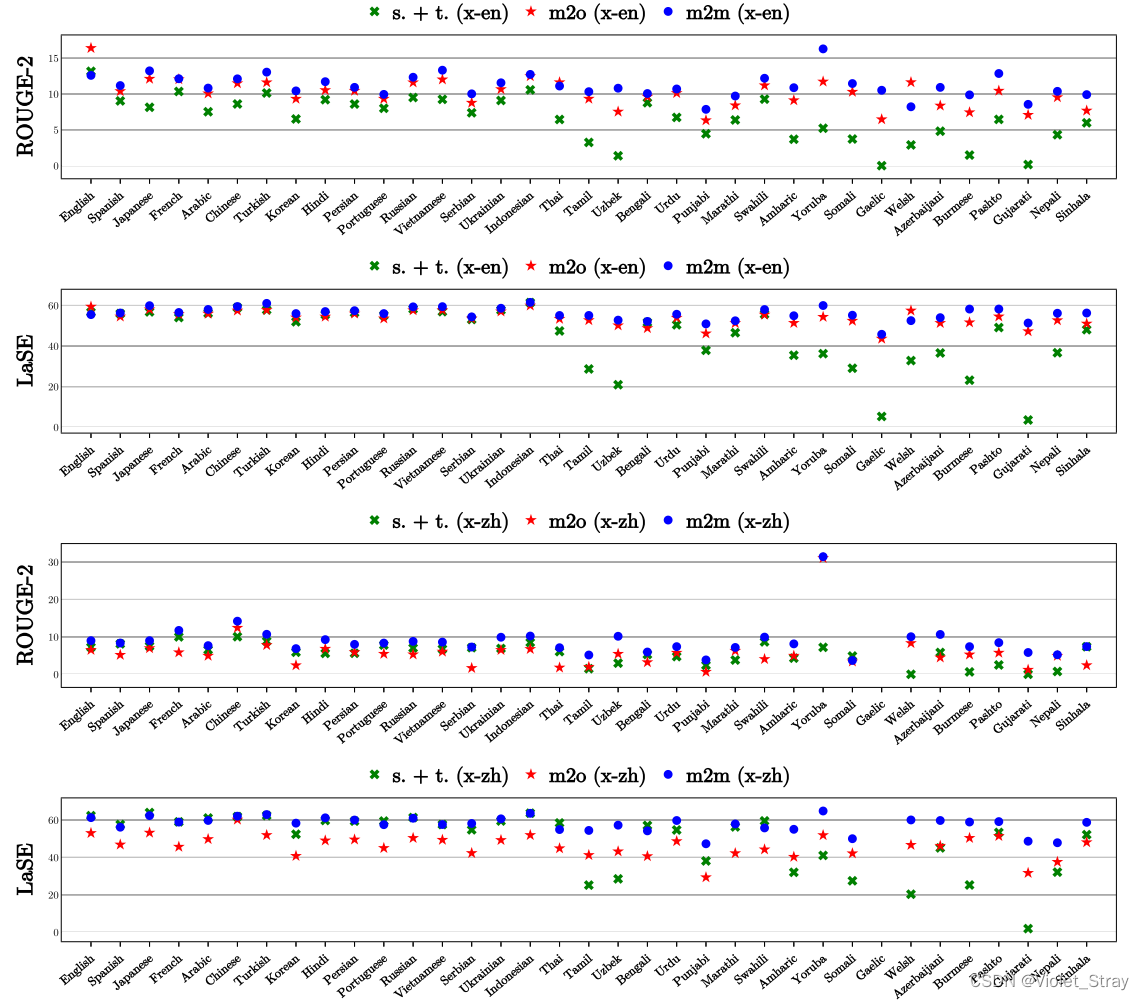
图4:随着源语言的变化,以英语和中文为目标语言的ROUGE-2和LaSE分数。在大多数语言中,m2m模型明显优于m2o模型和摘要后翻译基准模型。与其他目标语言的比较详见附录(图8),因为空间有限。
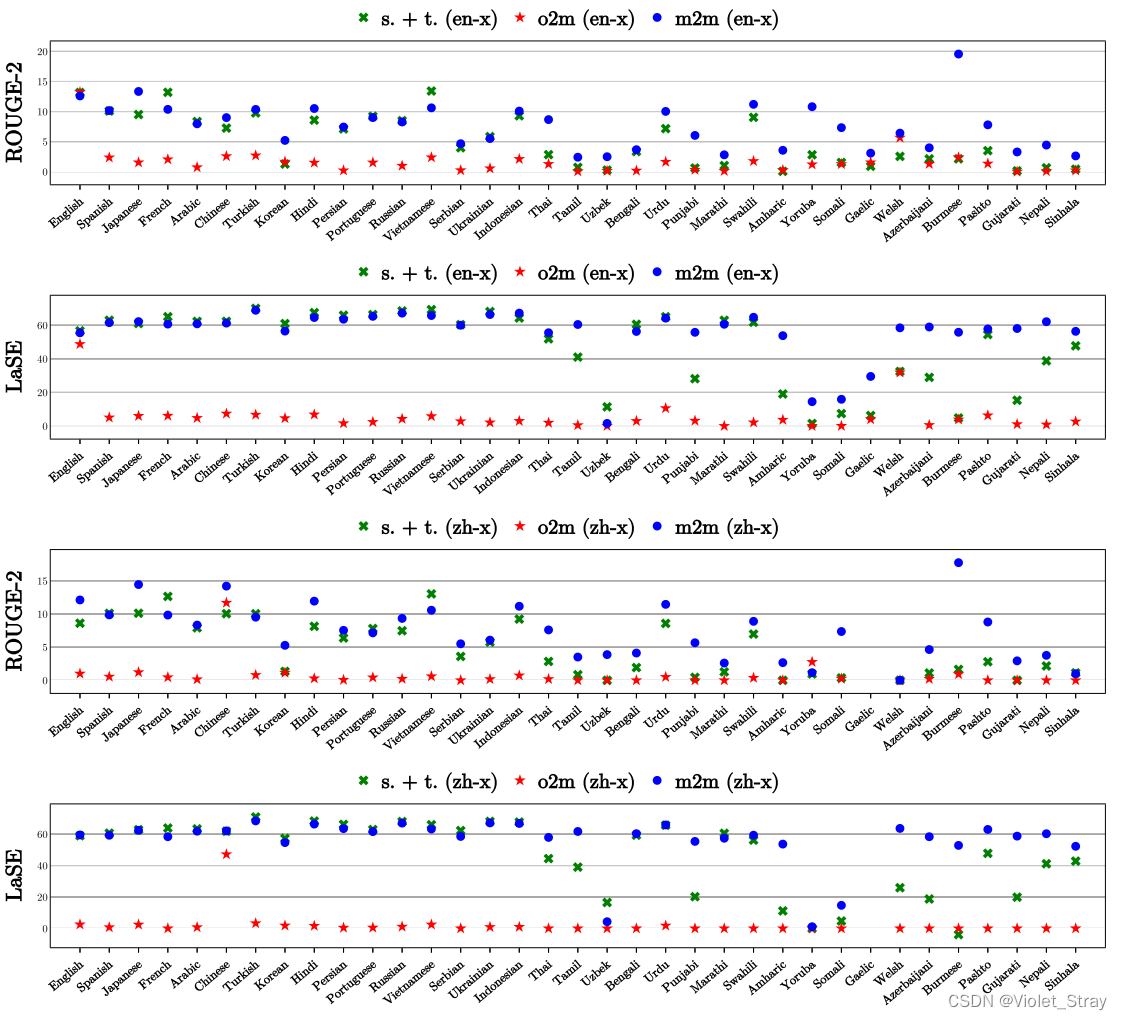
图5:随着目标语言的变化,以英语和中文为源语言的ROUGE-2和LaSE分数。在大多数语言中,m2m模型明显优于o2m模型和摘要后翻译基准模型。与其他源语言的比较详见附录(图9),因为空间有限。
5.1 零迁移跨语言通信
之前的实验是在完全监督的方式下进行的。然而,对于许多低资源语言对来说,样本并不丰富。因此,能够在不依赖任何标记示例的情况下执行零迁移跨语言生成是具有吸引力的。为此,我们只在语言相同的情况下对 mT5 进行了多语言方式的微调(即,源语言和目标语言都相同),在推断时变换了目标语言。不幸的是,该模型在生成跨语言摘要方面表现非常差,而是执行了同语言摘要。
我们还在零迁移设置下对其他语言的样本进行输入,并用 m2o 模型(只使用目标语言的同语言样本)进行单语方式微调。在这种情况下,模型能够为一些语言对生成非平凡的摘要,但仍然远远落后于完全监督模型。我们在附录中包含了图表 10 和 11 来说明这一点。
此外,我们还对在训练中缺乏的远程低资源语言对上运行了 m2m 模型的推断。它们的 LaSE 得分明显低于监督对,这意味着监督多语言模型中的零迁移表现较差。
我们没有进行少样本实验,将其作为未来可能的研究方向。
6 结果分析
统计显著性:虽然第5节的实验结果显示,提出的m2m模型表现优于其他模型,但在许多语言对中,差异非常接近。因此,仍然需要进行统计显著性检验来进一步支持我们的论断。因此,对于每个实验的语言对,我们执行了Bootstrap重采样测试(Koehn, 2004),将m2m模型与其他模型中表现最佳的模型进行一对多的比较:如果m2m具有最佳的(ROUGE-2 / LaSE)得分,我们将其与得分第二的模型进行比较;如果m2m不是最佳的,则将其与最佳模型进行比较。结果(p < 0.05)如表1所示,超过42%的语言对中,m2m显著更好,在不到10%的语言对中,它明显更差。这提供了额外的证据,支持我们的论点,即m2m模型表现更好。
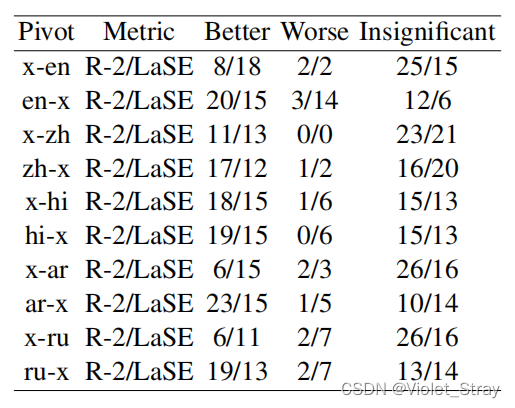
表格1:不同中介语言的显著性测试。
LaSE的可靠性:首先,我们通过显示LaSE与ROUGE-2的相关性来验证LaSE的可靠性。我们采用了s.+t.中的同语言摘要模型的不同检查点,并为第3节中的九种语言计算每个检查点的ROUGE-2和LaSE。计算得分的相关系数如表2的第二列所示。对于所有语言(从高资源到低资源),LaSE与ROUGE-2具有接近完美的相关性。然而,LaSE的目的是表明它是与语言无关的,甚至可以在目标语言没有参考文本的情况下进行计算。因此,我们使用m2m模型评估具有与输入文本的语言不同的参考文本的摘要。对于每个目标语言,我们首先计算不同源语言的标准LaSE(称为LaSE-in-lang)。然后,我们将参考文本与输入文本的语言的参考文本交换,再次计算LaSE(称为LaSE-out-lang)。然后,在表2的第三列中,我们展示了两个LaSE变体之间的相关性,针对每个目标语言。结果显示,两个LaSE变体在所有语言中都存在显著的相关性。通过这两个实验,我们可以得出结论,LaSE是用于摘要系统评估的理想度量标准,可以以与语言无关的方式进行计算。
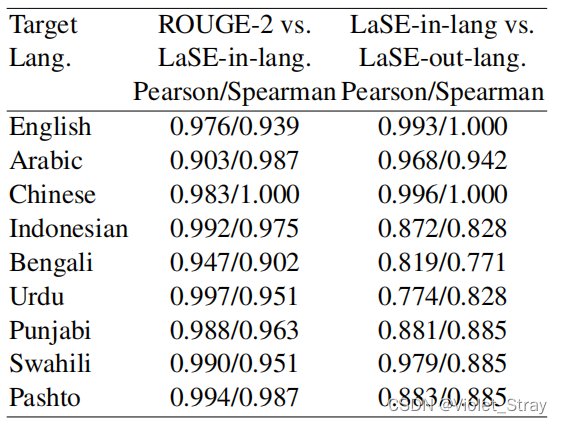
表格2:ROUGE-2和LaSE的相关性分析。我们计算了皮尔逊和斯皮尔曼系数。
7 相关工作:
在XLS研究的初期阶段,基于流水线的方法很受欢迎(Leuski et al., 2003; Orasan and Chiorean, 2008; Wan et al., 2010),将任务分解为摘要和翻译任务的一系列步骤。随着神经模型的出现,执行XLS任务的端到端方法逐渐流行起来。Ayana等人(2018)使用知识蒸馏(Hinton等人,2015)从两个摘要和翻译教师模型中训练了一个学生XLS模型。使用合成数据集,Zhu等人(2019);Cao等人(2020a)在多任务框架中使用双Transformer(Vaswani等人,2017)架构执行XLS,而Bai等人(2021)提出了一个单一的编码器-解码器,以实现更好的任务之间的迁移。Chi等人(2021)引入了专门针对跨语言任务的多个预训练目标,这些目标在XLS上取得了改进的结果。我们建议我们的读者参考Wang等人(2022)以获取更全面的文献综述。
直到最近,XLS主要局限于英中语言对,原因是缺乏基准数据集。为了推动任务超越这一语言对,Ladhak等人(2020)引入了Wikilingua,这是一个以英语为枢轴语言的大规模一对多数据集,而Perez-Beltrachini和Lapata(2021)引入了XWikis,其中包含12个方向的4种语言。
最近,Wang等人(2023)通过使用大型语言模型如ChatGPT13、GPT-4(OpenAI,2023)和BLOOMZ(Muennighoff等人,2022)来进行零次跨语言摘要的研究。
8 总结&未来工作
在这项工作中,我们提出了CrossSum,一个包含1,500多种语言对中的1.68百万个样本的大规模、非英语中心的XLS数据集。CrossSum为其中许多语言对提供了首个公开可用的XLS数据集。通过对CrossSum进行有限规模的人工评估,我们引入了MLS,这是一个用于通用跨语言生成的多阶段采样算法,以及LaSE,这是一个用于在目标语言中可能没有参考摘要的情况下评估摘要的语言无关度量。我们展示了训练一个多语言模型可以有助于比基线更好地执行XLS。我们还探讨了使用CrossSum进行零次和少次XLS的潜力。我们分享我们的发现和资源,希望能够使XLS研究社区更具包容性和多样性。
在未来,我们将研究将CrossSum用于其他摘要任务,例如多文档摘要(Fabbri等人,2019)和多模态摘要(Zhu等人,2018)。我们还希望探索更好的技术,用于m2m、零次和少次跨语言摘要。
局限
尽管我们认为我们的工作有许多优点,但必须承认它的一些局限性。尽管通过详尽的人工注释是确保数据集最大质量的最可靠手段,但由于数据集的规模巨大,我们不得不采用CrossSum的自动整理。如在人工评估中所确定的那样,LaBSE进行的并不是所有正确的对齐。它们主要是描述相似(即具有相当程度的句法或语义相似性)但非相同事件的摘要。LaBSE也未能惩罚数字不匹配,特别是如果摘要描述相同事件。因此,LaBSE在整理阶段的任何错误可能会传播到使用CrossSum训练的模型中。由于LaBSE是所提出的LaSE度量的组成部分,这些偏见可能在评估阶段未被LaSE识别。然而,无论我们使用哪种自动方法,这些极端情况下都会存在这种脆弱性。由于本文的目标不是审查LaBSE的缺陷,而是将其用作整理和评估的手段,我们认为LaBSE是最佳选择,因为它在现有替代方案中具有广泛的语言覆盖和跨语言挖掘方面的经验表现。
伦理考虑
许可证CrossSum是XL-Sum数据集的衍生物。XL-Sum已根据知识共享署名-非商业-相同方式共享4.0国际许可协议(CC BY-NC-SA 4.0)发布,允许进行非商业研究目的的修改和分发。我们遵守许可协议的条款,将CrossSum发布在相同的许可协议下。
生成的文本我们的所有模型都使用mT5模型作为基础,该模型在大规模多语言文本语料库上进行了预训练。对于文本生成模型,即使在预训练阶段有大量冒犯或有害文本,也可能导致生成文本中的危险偏见(Luccioni和Viviano,2021)。因此,我们的模型可能会在预训练阶段学到冒犯或有偏见的内容,这是我们无法控制的。已经显示文本摘要系统生成的文本可能是不忠实和事实不准确的(尽管流利)(Maynez等人,2020)。因此,我们建议在考虑在任何真实部署中使用之前,仔细检查潜在的偏见。
人工评估我们从提供多种语言专业培训的机构的毕业生中聘请了注释员,包括第3节中评估的语言。每个注释员评估了大约200-250个序列对。每个注释平均需要一个半分钟,整个注释过程大约需要5-6小时。注释员按当地货币的双语专业人员的标准报酬按小时支付。
环境影响作为这项工作的一部分,总共训练了25个模型。每个模型在一个配备4个GPU的Tesla P100服务器上训练了约三天。假设每千瓦时排放0.08千克二氧化碳(Luccioni和Viviano,2021),这项工作释放不到175千克的碳排放到环境中,远远低于大多数计算需求高的模型。
致谢
这项工作得到了孟加拉国工程技术大学科学与工程研究与创新中心(RISE)的资助。澳大利亚斯威本科技大学的OzSTAR国家设施用于进行计算实验。OzSTAR计划的资金部分由澳大利亚政府的天文学国家协作研究基础设施战略(NCRIS)拨款提供。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









