







 本文介绍了一种利用开源毒蘑菇数据集,通过ResNet进行图像分类并结合IntelExtensionforPyTorch加速的模型,旨在快速准确地辨别有毒蘑菇,降低误食风险。文章详细描述了模型训练、增强方法和硬件配置,以及推理速度的对比分析。
本文介绍了一种利用开源毒蘑菇数据集,通过ResNet进行图像分类并结合IntelExtensionforPyTorch加速的模型,旨在快速准确地辨别有毒蘑菇,降低误食风险。文章详细描述了模型训练、增强方法和硬件配置,以及推理速度的对比分析。
一、方案背景
蘑菇可分为食用蘑菇和有毒蘑菇。可食用蘑菇营养丰富、味道鲜美,受到大家的喜爱。然而,部分有毒蘑菇和食用蘑菇宏观特征极其相似,普通人难以正确分辨。有毒蘑菇的危害很大:根据云南省疾控中心统计数据,2021年云南省食用野生菌中毒事件达600余起,导致2000多人中毒,20多人死亡。对于有毒蘑菇的鉴别,目前除了医院、检测机构和专家学者,没有简便高效的手段和途径。在此背景下,本方案利用开源的毒蘑菇图片数据集(https://www.kaggle.com/datasets/stepandupliak/predict-poison-mushroom-by-photo),提出一个基于ResNet的毒蘑菇识别模型,可以较为精确快捷地判别蘑菇类型,从而为人们日常分辨有毒蘑菇提供有效指引。
二、方案简介
本方案通过开源的毒蘑菇数据集,基于神经网络模型ResNet进行图像分类的微调,训练过程中采用图像增强的方法来提升模型的鲁棒性,同时利用Intel® Extension for PyTorch*工具包加速模型的推理,从而得到一个分类精度较高和推理速度快的毒蘑菇识别模型,具有低成本和方便快捷的特点,可为人们日常生活和野外鉴别有毒蘑菇提供精确及时的指引,并且有利于减少人们误食有毒蘑菇等事故的发生。
三、建模流程图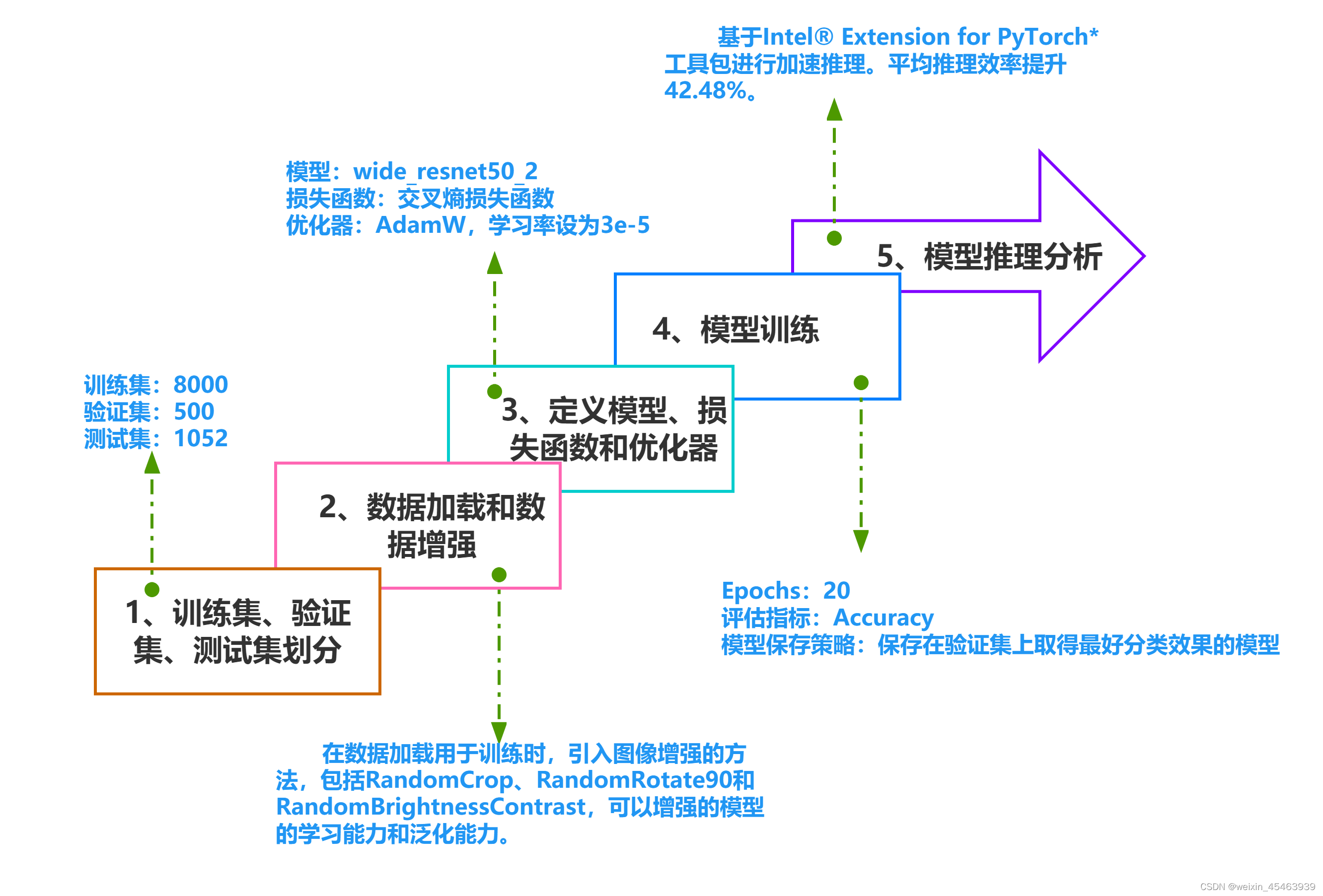
四、硬件配置
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









