






本次还和小伙伴报名了赛道三:基于机器学习的欺诈风险识别。这个赛道主要是使用oneAPI人工智能分析工具包实现任一创意即可。
一、在这个赛道,我们基于某银行的账号流水信息和公安部提供的欺诈黑名单信息用于反欺诈建模。整体建模流程如下。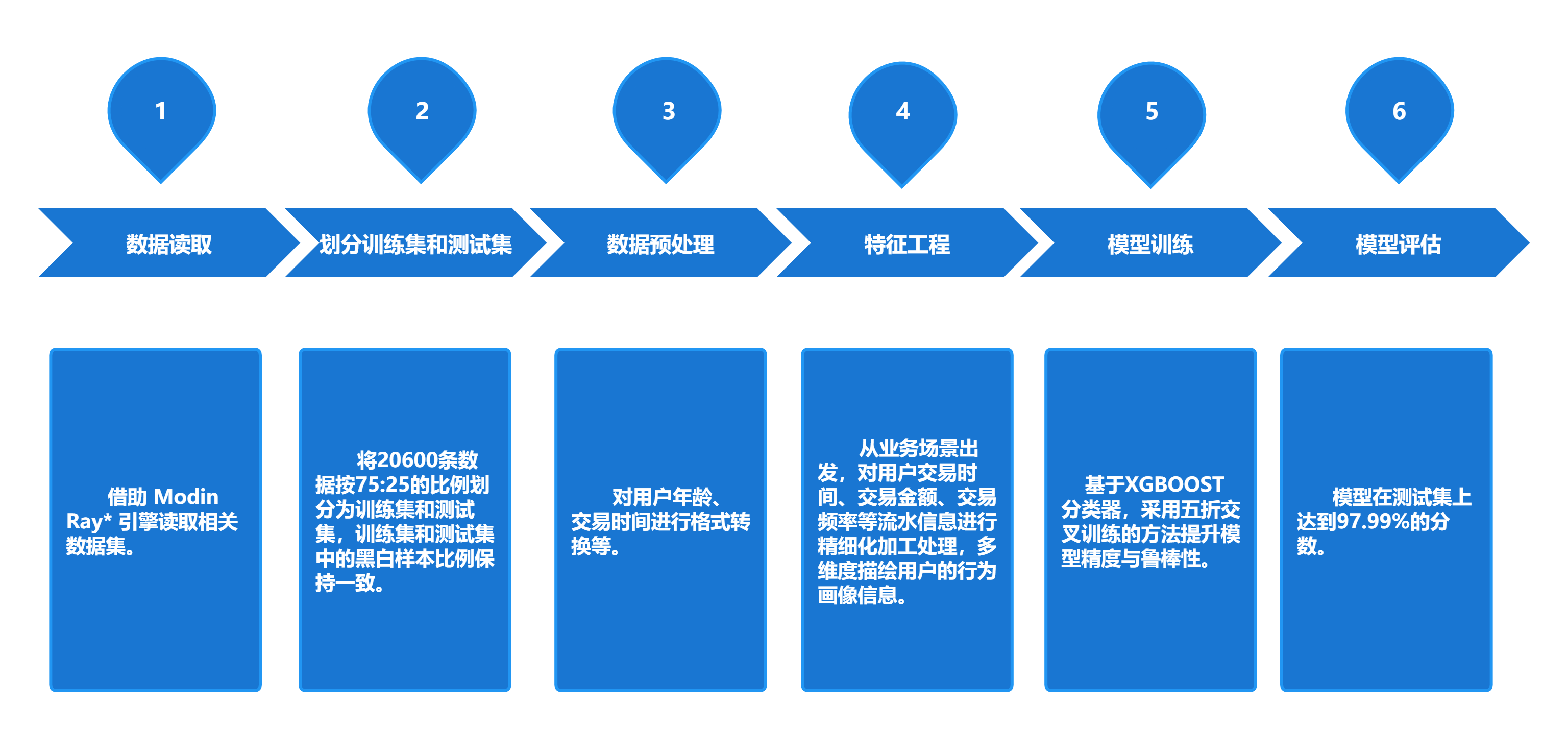
二、用到的oneAPI工具包主要有Intel® Distribution of Modin*、Intel® Extension for Scikit-learn*和XGBoost Optimized for Intel® Architectures,其功能描述如下:

三、实际建模中对比分析了使用oneAPI工具包前和使用oneAPI工具包后的加工效率,如下图所示,经过英特尔Modin*工具优化,数据读取与数据加工时间减少约30s,效率提高20.68%。同时,XGBoost模型可在3min26s内实现15450条数据的五折交叉训练,并在测试集取得高达97.99%的F1分数,兼顾训练速度与分类精度。
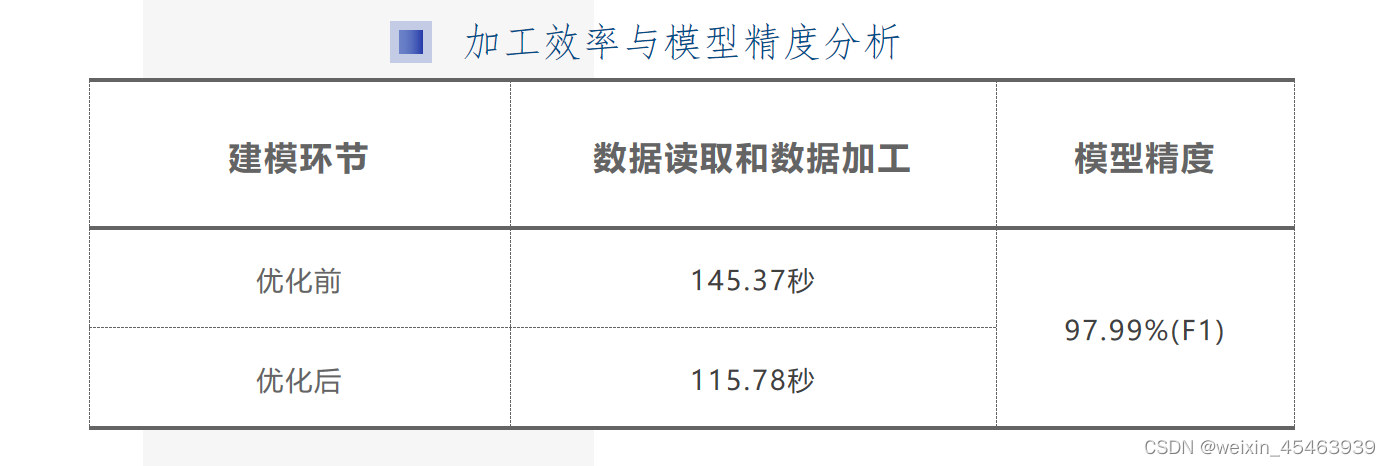
四、模型训练与推理使用Xgboost进行五折交叉验证,模型融合精度要比单折高1%左右,代码详情如下。
def train_and_predict(train_data,train_label,test_data):
'''
train_data:训练集数据,可为dataframe格式
test_data:测试集数据,可为dataframe格式
label:训练集标签,取值0和1,可为series格式
返回predictions_xgb,为每条数据的欺诈概率,取值范围0-1
'''
NFOLD = 5
random_state = 2021
KF = StratifiedKFold(n_splits=NFOLD, shuffle=True, random_state=random_state)
predictions_xgb = np.zeros(len(test))
params = {'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'max_depth': 6,
'subsample': 0.8,
'colsample_bytree': 0.8,
'colsample_bylevel': 0.8,
'colsample_bynode':0.8,
'seed': random_state,
'nthread': 2,
'eta':0.05
}
for fold_, (trn_idx, val_idx) in enumerate(KF.split(train_data,train_label)):
print('----------------------- fold {} -----------------------'.format(str(fold_+1)))
train_matrix = xgboost.DMatrix(train_data.iloc[trn_idx], label = train_label.iloc[trn_idx])
valid_matrix = xgboost.DMatrix(train_data.iloc[val_idx], label = train_label.iloc[val_idx])
test_matrix = xgboost.DMatrix(test_data)
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = xgboost.train(params, train_matrix, num_boost_round=50000, evals=watchlist, verbose_eval=200, early_stopping_rounds=200)
predictions_xgb[:] += (model.predict(test_matrix , ntree_limit=model.best_ntree_limit)/ NFOLD)
return predictions_xgb 总体而言,赛道三是一个创意赛道,使用OneAPI工具进行建模分析即可。比较深刻的一个点是Intel® Distribution of Modin*的使用,在导入pandas之前加入以下三行代码即可使用优化算子,大大加速了复杂的特征加工和处理,包括均值、标准差和差分运算等等,非常适用于大数据场景的和复杂数据加工处理。
import modin.pandas as pd
from modin.config import Engine
Engine.put("dask") 















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









