







关于截图中库表得sql语句在最后
Explain
- explain:模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句
- 使用:explain+查询的sql语句;

解释上述表格中字段的作用:
1. id:表示sql语句中操作表的顺序,常搭配table一起分析。
规则:id越大越先执行。id相同则从上到下依次执行。
2. table:表示操作的是哪 张表。<derived+id>表示为临时表数字表示从id为数字的表中查询的结果集当作临时表。
3. select_type:sql语句查询的类型。用于区别普通查询、联合查询、子查询等复杂的查询。
取值:
* simple:简单的查询,查询中不包含子查询或者union集合操作。
* primary:查询中包含任何复杂的子部份,最外层的select的类型为该值。explain select id from (select id from student) as der;
* subquery:在select或where列表中包含了子查询的为该级别。
* derived:在from列表后边包含子查询。即from后边跟了一个查询来作为结果集(临时表,会影响性能)。
* union:若第二个select出现在union后,则被标记为UNION,若union包含在from子句的子查询中,外层select将被标记为derived。
* union result:从union结果集表获取结果的select语句为该级别
4. partitions:匹配的分区。很少分区,不用管
5. type:查询使用了那种类型。是sql效率的关键指标。要保证查询至少达到range级别,最好到达ref级别。
优先级从上到下
-
system 即表结果集只有一行记录。其实是const的特例
-
const 使用索引一次就找到了,通过唯一unique索引或主键索引primary查询,一次命中且结果集只有一个的情况。
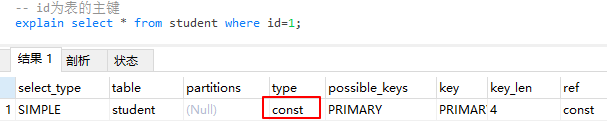
-
eq_ref 唯一性索引扫描。对于每个索引键表只会有与之对应的一条数据。常见于主键或者唯一索引。
对于student表,使用的id字段为主键,表中只会有一条与之对应的记录,因此对于student表而言其查询的type是eq_ref。此处的product表是作为驱动表传递值作为student.id来做检索
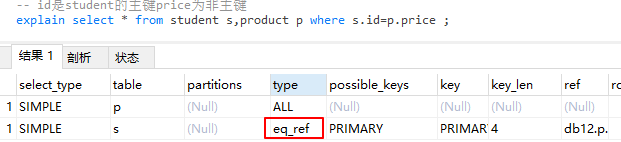
- ref 非唯一性索引扫描,返回所有匹配某个单独值的所有的数据行。可能包含多个
name为非唯一性索引,可能有多个叫张三得学生

-
range 使用索引检索给定范围的行。
优化:对范围结果集做分页。
使用索引,进行范围查询即where条件后逻辑运算符使用了in、between、<、>、<=、>=等,使用一个索引来检索给定范围的行。
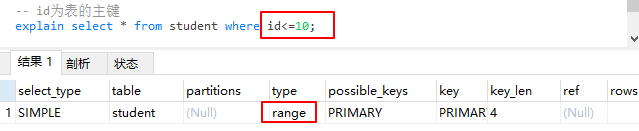
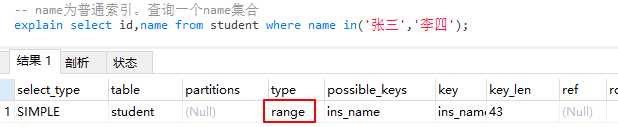
-
index 只遍历索引树,即不走库表的磁盘io只需要走索引的io。比all快。如查询的字段皆是索引字段。要避免该情况发生
- 当覆盖索引时候查**询的结果集在二级索引中都有(例如查询结果集为主键和二级索引字段)**则会选择二级索引去因为二级索引小查询,这是优化器内部优化策略决定的。不一定一致。
- 当不满足上述条件时即查询结果集,则不一定会使用二级索引。
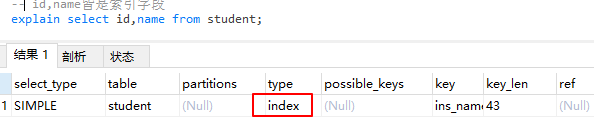
不一致情况。
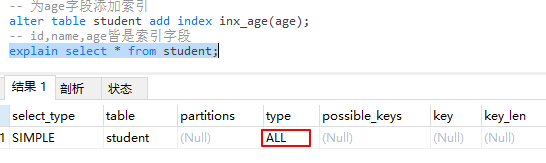
-
all 遍历全表以找到匹配行。未使用索引。
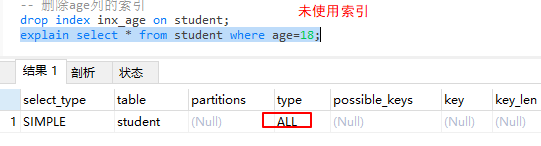
6. possible_keys:显示可能在该表中使用的索引。查询的字段存在索引则列出。不一定被实际使用!使用覆盖索引时可能为null,key中不为null。
7. key:**sql语句实际使用的索引。**注意:查询若使用了索引覆盖,则该索引仅出现在key不出现在possible_keys
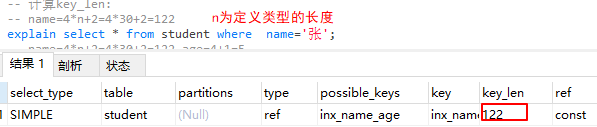
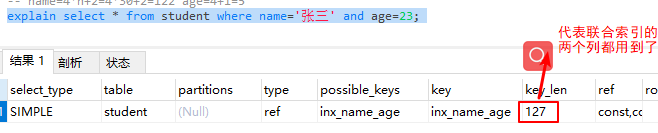
8. key_len:索引中使用的字节数。显示的值为索引字段的最大可能长度(即表中定义的长度范围),并非实际使用长度。可以用来计算该sql使用了联合索中的哪几列。

案例:图1说明只是用了联合索引的name字段即最左前缀。
9. ref:在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),func,NULL,字段名(例:product.price)。即显示where条件中索引=什么的描述。

10. rows:计划出该sql执行大致的扫描行。
11. filtered:多表查询时,rows*filtered/100可以估算出将要和explain中前一个表(指id比当前表小的表)进行连接的行数
12. extra:显示其他非常重要得消息
注意该值的显示由select后的字段和where后的字段共同控制。
坏的情况
- using filesort:文件排序。即无法利用索引完成得排序操作称为文件排序。优化:对排序字段进行索引覆盖
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HGHNqGPB-1629266759691)(C:\Users\telek\AppData\Roaming\Typora\typora-user-images\image-20210817141255943.png)]](https://img-blog.csdnimg.cn/1dd1cfc71a614991acb490093f37d522.png)
- using temporary:mysql需要创建一张临时表来处理查询。该情况一般要进行优化。如在去重字时对去重字段添加索引,他就会去找索引树,而不是创建临时表。一般常见于order by 和group by时未使用到索引
未优化:

优化后:为actor表的name字段添加索引后执行该sql发现extra变为了using index
- select table optimized away:使用某些聚合函数来访问存在索引的某个字段。效率比较高,因为在索引树种就可以得到结果。
- others:查阅官方文档即可https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
eg:
-- 删除多列索引、为name字段建立索引
-- using index 覆盖索引。
explain select name from student where name='张三';
explain select id,name from student where name='张三' and id=1;
-- using where 即where子句未被全覆盖。
explain select name,age from student where name='张三' and age=23;
好的情况
- using index:查询的结果集走了** 覆盖索引 **(不用回表操作)。同时出现using where代表索引被用来执行索引键值得查找。select字段和where字段皆为索引
- using where:使用where语句来搜索结果,并且where子句的列未被索引全覆盖
- using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围

最左前缀匹配原则:

优化原则
- 全值匹配:对于联合索引来讲,应当在不违背最左前缀匹配原则的情况下尽可能命中多个索引字段,效率会比较高
-- 联合索引的全值匹配原则inx_name_age_position
explain select id,name,age,position,hire_time from employees where name='Lucy';
explain select id,name,age,position,hire_time from employees where name='Lucy' and age=23;
-- 注意:联合索引字段全部命中,效率最高
explain select id,name,age,position,hire_time from employees where name='Lucy' and age=23 and position='dev';
-- 注意当顺序打乱后mysql内部优化器会优化为上边的sql执行顺序
explain select id,name,age,position,hire_time from employees where position='dev' and age=23 and name='Lucy';
- 最左前缀原则:对于联合索引的使用,where条件种必须要有多列索引中的第一列。
-- 2. 最左前缀原则
explain select id,name,age,position,hire_time from employees where name='Lucy' and age=23 and position='dev';
explain select id,name,age,position,hire_time from employees where age=23 and position='dev';
explain select id,name,age,position,hire_time from employees where position='dev';
-- 语句2、3种未包含最左前缀name字段的筛选,故不使用索引查询
- 不在索引列上做任何操作。(计算、函数、类型转换),会导致索引失效而转向全表扫描。因为操作后和索引树种的数据不匹配了,所以失效了。
-- 3. 不对索引做任何操作
explain select id,name,age,position,hire_time from employees where name='HanMeimei';
-- 此处更改了name的取值,索引会失效
-- left函数是取最左边n位字符
explain select id,name,age,position,hire_time from employees where left(name,3)='Han';
- 日期类型的小优化
-- 为trim_time列添加普通索引
alter table emplyees add INDEX `idx_hire_time`(`hire_time`) USING BTREE COMMENT '单列普通索引'
-- 4. 日期类型的小优化
explain select id,name,age,position,hire_time from employees where hire_time>='2021-08-17';
-- 查询当天的数据,该类型不会走索引,索引失效了
explain select id,name,age,position,hire_time from employees where date(hire_time)='2021-08-17';
-- 优化:范围查询使该sql可能走索引
explain select id,name,age,position,hire_time from employees where hire_time>='2021-08-17 00:00:00' and hire_time<='2021-08-17 23:59:59';
-- date函数:只保留年月日,当天
select DATE('2021-08-17 14:25:35');
select '2021-08-17 14:25:35';
-- 删除hire_time列的索引
alter table db12.emplyees drop INDEX idx_hire_time;
- 不能使用组合索引中范围条件右边的列。否则范围之后得索引全失效
-- 5. 不使用索引中范围条件的右边的列
explain select id,name,age,position,hire_time from employees where name='Lucy' and age=23 and position='dev';
-- age取范围时候在索引树中是有序的,而position列不一定是有序的,故组合索引不走position列
explain select id,name,age,position,hire_time from employees where name='Lucy' and age>23 and position='dev';
result:根据key_len判断具体使用了联合索引中的哪个字段。


联合索引所引树存储结构

- 尽量使用覆盖索引。此时extra显示using index。只访问索引列的查询,减少select *语句
-- 6. 使用覆盖索引
-- 推荐使用,查询的字段覆盖了全索引。
explain select name,age,position from employees where name='Lucy' and age=23 and position='dev';
explain select * from employees where name='Lucy' and age=23 and position='dev';
explain select id,name,age,position,hire_time from employees where name='Lucy' and age=23 and position='dev';
- mysql在使用不等于或者大于、小于时候可能无法使用索引,会导致全表扫描。
- is null,is not null 一般情况下也无法使用索引。
- like以通配符开头,mysql索引失效,会变成全表扫描。优化:使用覆盖索引进行优化使其从all变为index。
- where后边尽量字段类型和给的值类型匹配。字符串不加单引号导致索引失效
- 少用or、in
- 范围查询优化:对范围列添加单列索引。当范围太大时可能不会走索引。

索引失效


图片中6得结论现在随着mysql得升级type已经从all变为了range
图片8中补充以’xx%'方式进行like得type结果是个range范围得。关于%%这种是需要concat去拼接得。如果实际业务非要使用%%这种去查询还要使索引不失效,可以使用覆盖索引实现,即查询得字段全部是建立了索引得字段,这样可以使%%索引不失效
该图片结论不一定正确随着版本得迭代

排序和where同时是组合索引得使用情况:



数据库表准备
-- ----------------------------
-- Table structure for employees
-- ----------------------------
DROP TABLE IF EXISTS `employees`;
CREATE TABLE `employees` (
`id` int NOT NULL AUTO_INCREMENT COMMENT 'id主键',
`name` varchar(24) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '姓名',
`age` int NOT NULL COMMENT '年龄',
`position` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '职位',
`hire_time` timestamp NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_name_age_position`(`name`, `age`, `position`) USING BTREE COMMENT '联合索引'
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of employees
-- ----------------------------
INSERT INTO `employees` VALUES (1, 'LiLei', 22, 'manager', '2021-08-17 14:25:01');
INSERT INTO `employees` VALUES (2, 'HanMeimei', 23, 'dev', '2021-08-17 14:25:19');
INSERT INTO `employees` VALUES (3, 'Lucy', 23, 'dev', '2021-08-17 14:25:35');
SET FOREIGN_KEY_CHECKS = 1;
















 1898
1898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









