







 本文介绍了C语言中文件描述符的工作原理,如何通过文件描述符管理文件对象,以及重定向机制如何利用文件描述符进行流的替换。此外,还详细讨论了缓冲区在提高IO效率中的作用,包括行缓冲、全缓冲和手动刷新策略。
本文介绍了C语言中文件描述符的工作原理,如何通过文件描述符管理文件对象,以及重定向机制如何利用文件描述符进行流的替换。此外,还详细讨论了缓冲区在提高IO效率中的作用,包括行缓冲、全缓冲和手动刷新策略。
前言:
文件描述符 fd 是基础IO中的重要概念,一个 fd 表示一个 file 对象,如常用的标准输入、输出、错误流的 fd 分别为 0、1、2,实际进行操作时,OS 只需要使用相应的 fd 即可,不必关心具体的 file,因此我们可以对标准流实施 重定向,使用指定的文件流,在实际 读/写 时,为了确保 IO 效率,还需要借助缓冲区进行批量读取,最大化提高效率。
正文:
1.文件描述符
每一个进程都会维护一个独立的文件描述符表(File Descriptor Table)用来管理自己打开的文件
#include<iostream>
#include <cstdio>
using namespace std;
int main()
{
//分别打开三个 FILE 对象
FILE* fp1 = fopen("test1.txt", "w");
FILE* fp2 = fopen("test2.txt", "w");
FILE* fp3 = fopen("test3.txt", "w");
//对不同的 FILE* 进行操作
//……
//关闭
fclose(fp1);
fclose(fp2);
fclose(fp3);
fp1 = fp2 = fp3 = NULL;
return 0;
}
那么在 C语言 中,OS 是如何根据不同的 FILE* 指针,对不同的 FILE 对象进行操作的呢?
- 答案是 文件描述符
fd,这是系统层面的标识符,FILE类型中必然包含了这个成员
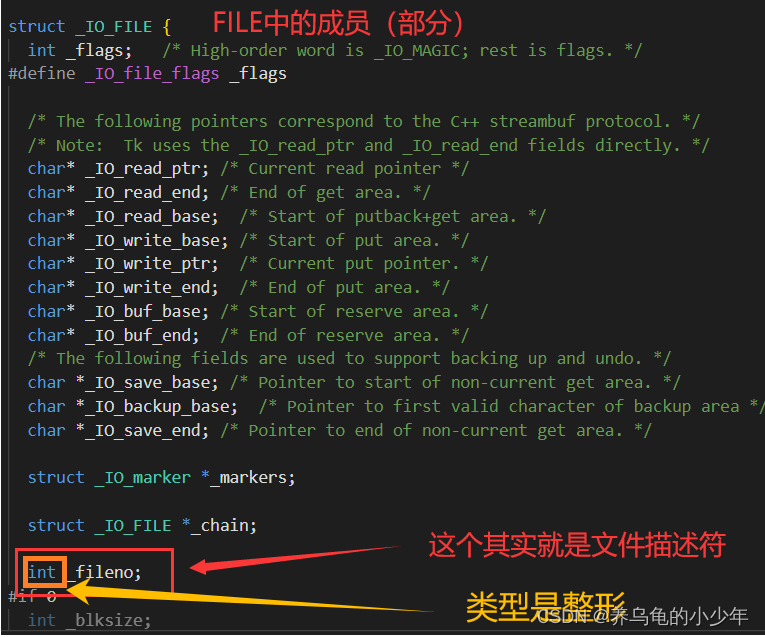
如何证明呢?实践出真知,在上面代码的基础上,加入打印语句
注:stdin 等标准流在 C语言 中被覆写为 FILE 类型
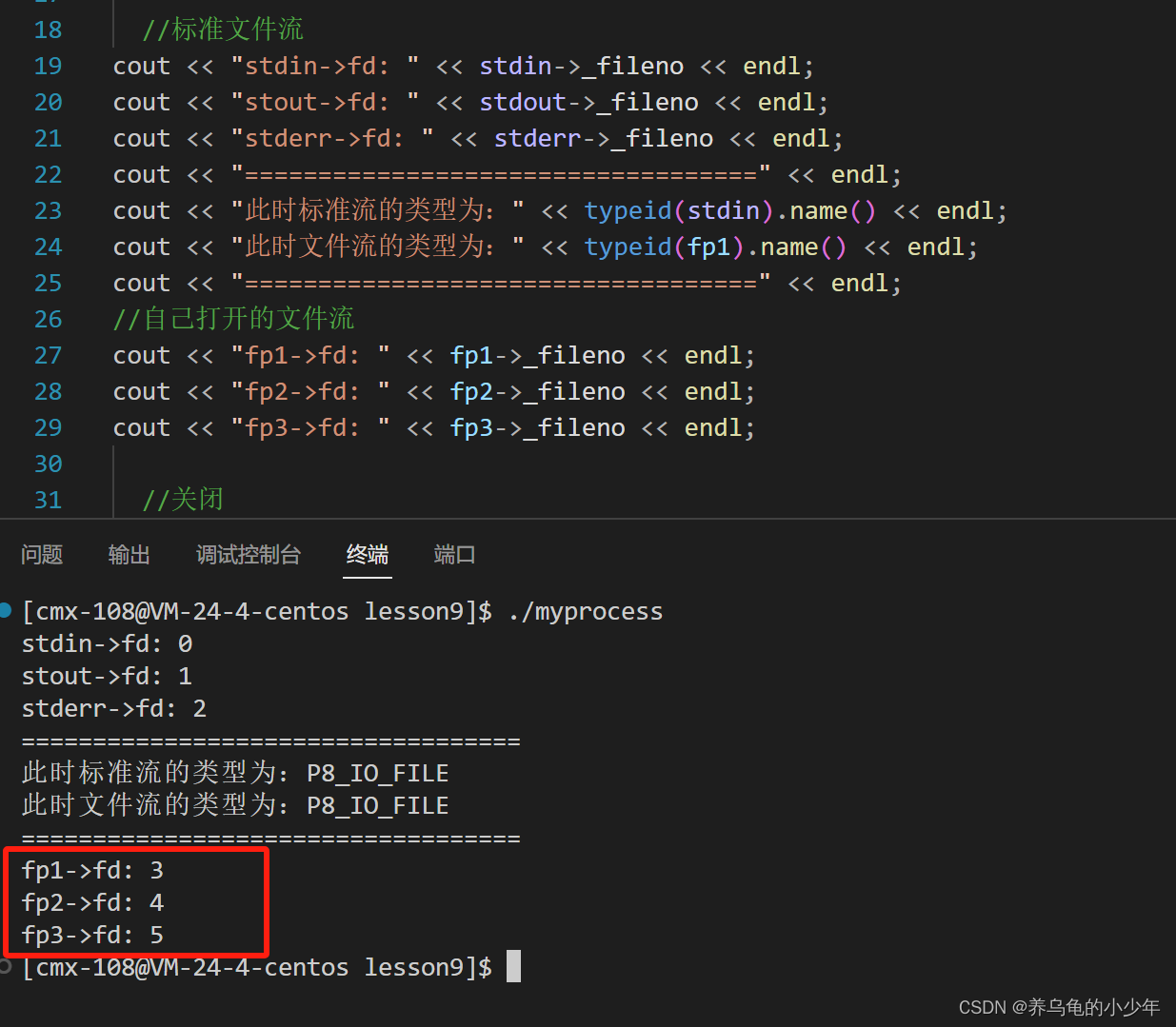
可以看出,FILE 类型中确实有 fd 的存在
文件描述符 是如何设计的?新打开的文件描述符为何是从 3 开始?我们带着问题继续研究。
1.1原理梳理
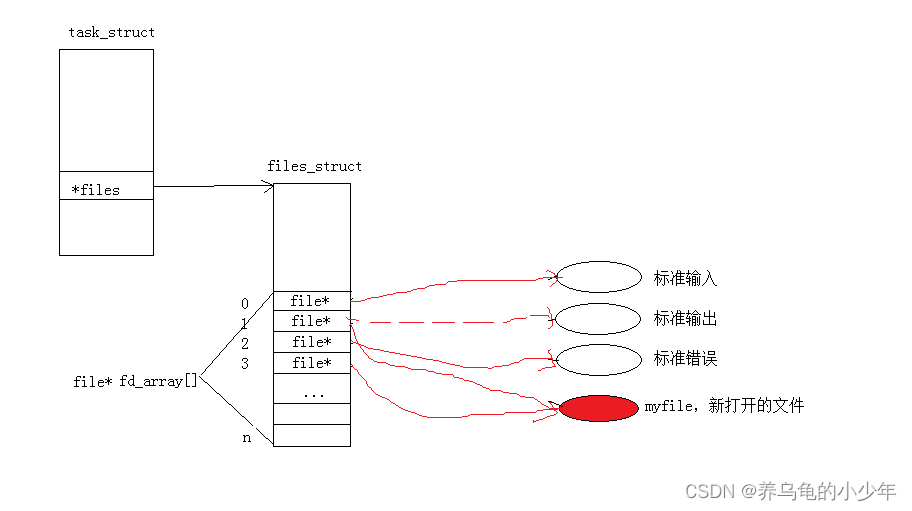
根据 先描述、再组织 原则,OS 将所有的文件都统一视为 file 对象,获取它们的 file* 指针,然后将这些指针存入指针数组中,可以进行高效的随机访问和管理,这个数组为 file* fd_array[],而数组的下标就是神秘的 文件描述符 fd
当一个程序启动时,OS 会默认打开 标准输入、标准输出、标准错误 这三个文件流,将它们的 file* 指针依次存入 fd_array 数组中,显然,下标 0、1、2 分别就是它们的文件描述符 fd;后续再打开文件流时,新的 file* 对象会存入当前未被占用的最小下标处,所以用户自己打开的 文件描述符一般都是从 3 开始
除了文件描述符外,还需要知道文件权限、大小、路径、引用计数、挂载数等信息,将这些文件属性汇集起来,就构成了 struct files_struct 这个结构体,而它正是 task_struct 中的成员之一
1.2struct_file
struct_file结构体是对已打开文件进行描述后形成的结构体,其中包含了众多文件属性,本文探讨的是 文件描述符 fd
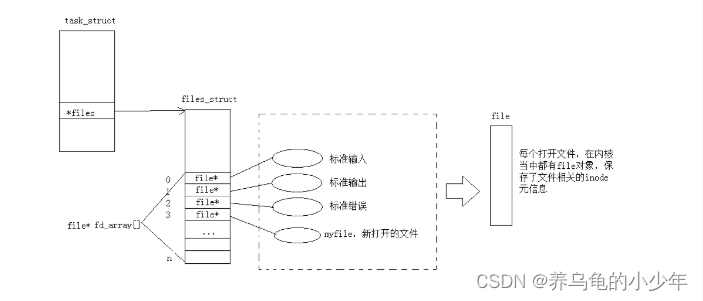
注:文件被打开后,并不会加载至内存中(这样内存早爆了),而是静静的躺在磁盘中,等待进程与其进行 IO,而文件的 inode 可以找到文件的详细信息:所处分区、文件大小、读写权限等,关于 inode 的更多详细信息将会在 【深入理解文件系统】 中讲解
1.3分配规则
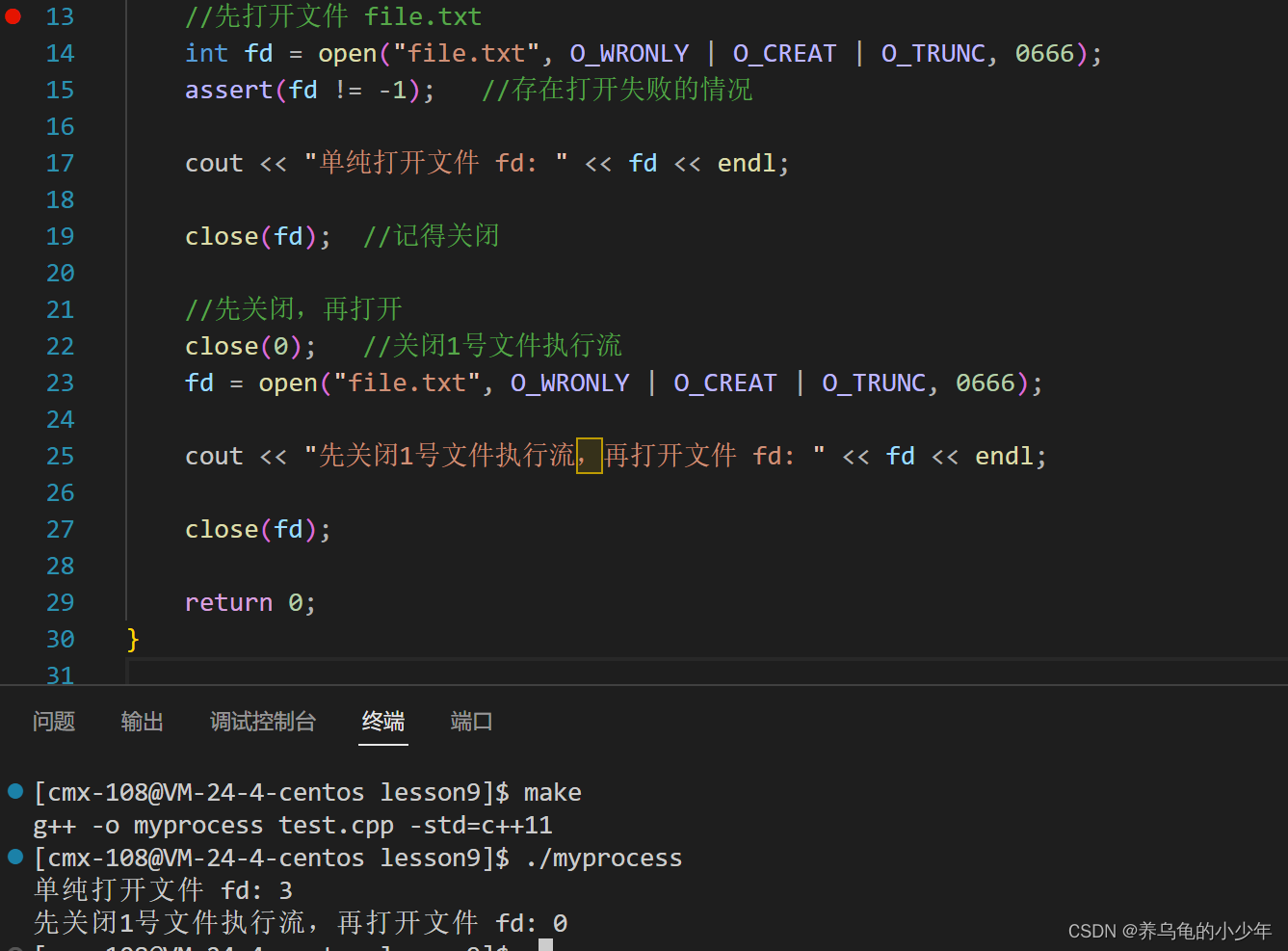
fd 的分配规则为:先来后到,优先使用当前最小的、未被占用的 fd,如果我们在打开文件之前,关闭之前的文件描述符如(stdin 0) 当我们打开文件file.text的时候,会将fd分配为0
#include<iostream>
#include <cstdio>
#include <cassert>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
using namespace std;
int main()
{
//先打开文件 file.txt
int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
assert(fd != -1); //存在打开失败的情况
cout << "单纯打开文件 fd: " << fd << endl;
close(fd); //记得关闭
//先关闭,再打开
close(0); //关闭1号文件执行流
fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
cout << "先关闭1号文件执行流,再打开文件 fd: " << fd << endl;
close(fd);
return 0;
}
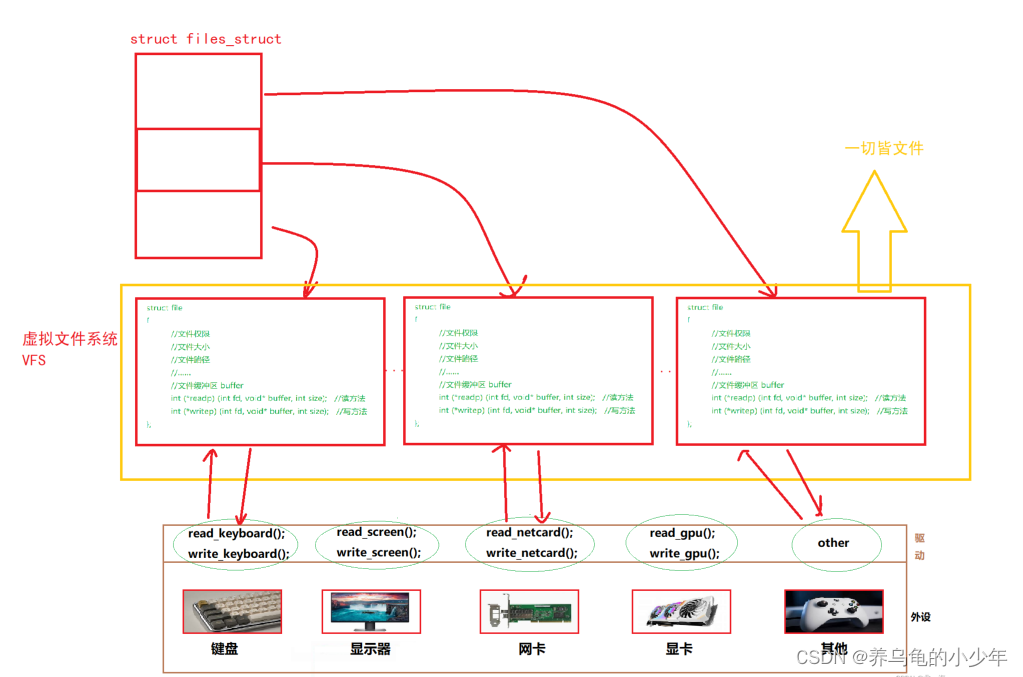
1.4为什么说linux下一切皆文件
如何理解 Linux 中一切皆文件这个概念?
现象:即使是标准输入(键盘)、标准输出(显示器) 在 OS 看来,不过是一个 file 对象
原理:无论是硬件(外设),还是软件(文件),对于 OS 来说,只需要提供相应的 读方法 和 写方法 就可以对其进行驱动,打开文件流后,将 file* 存入 fd_array 中管理即可,因此在 Linux 中,一切皆文件
2.重定向
2.1重定向本质
前面说过,OS 在进行 IO 时,只会根据标准输入、输出、错误对应的文件描述符 0、1、2 来进行操作,也就是说 OS 作为上层不必关心底层中具体的文件执行流信息(fd_array[] 中存储的对象) 因此我们可以做到 “偷梁换柱”,将这三个标准流中的原文件执行流进行替换,这样就能达到重定义的目的了

2.2指令重定向
echo you can see me > file.txt

可以看到数据直接输出至文件 file.txt 中
当然也可以 从 file.txt 中读取数据,而非键盘

现在可以理解了,> 可以起到将标准输出重定向为指定文件流的效果,>> 则是追加写入
而 < 则是从指定文件流中,标准输入式的读取出数据
我们也可以利用指令将标准输出和错误都重定向到文件
#include <iostream>
using namespace std;
int main()
{
cout << "标准输出 stdout" << endl;
cerr << "标准错误 stderr" << endl;
return 0;
}

2.3函数重定向
系统级接口 int dup2(int oldfd, int newfd)
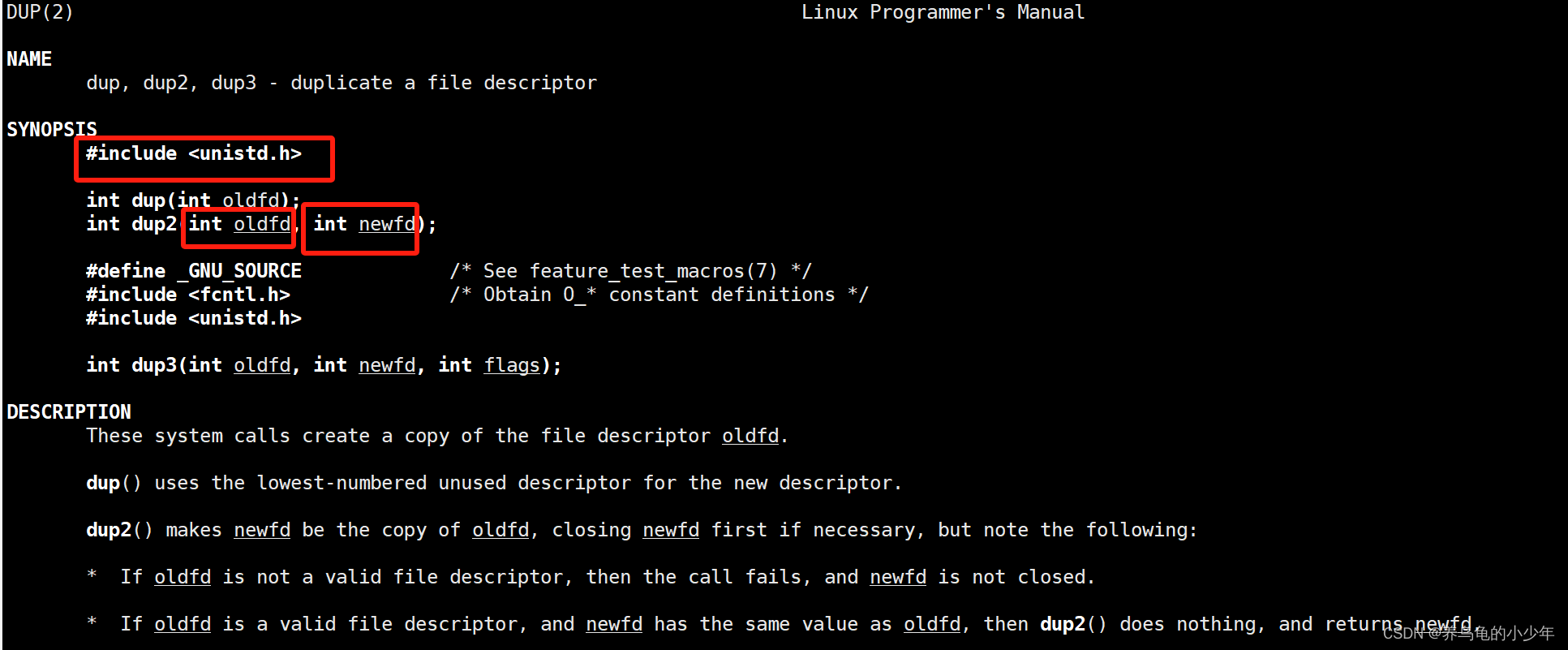
函数解读:将老的 fd 重定向为新的 fd,参数1 oldfd 表示新的 fd,而 newfd 则表示老的 fd,重定向完成后,只剩下 oldfd,因为 newfd 已被覆写为 oldfd 了;如果重定向成功后,返回 newfd,失败返回 -1
参数设计比较奇怪,估计作者认为 newfd 表示重定向后,新的 fd
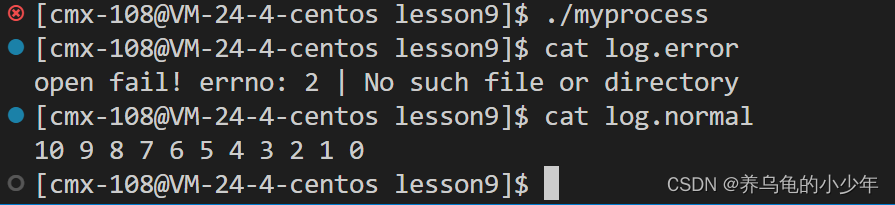
下面来直接使用,模拟实现报错场景,将正常信息输出至 log.normal,错误信息输出至 log.error 中
#include <iostream>
#include <cstdlib>
#include <cerrno>
#include <cassert>
#include <cstring>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
using namespace std;
int main()
{
//打开两个目标文件
int fdNormal = open("log.normal", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fdError = open("log.error", O_WRONLY | O_CREAT | O_TRUNC, 0666);
assert(fdNormal != -1 && fdError != -1);
//进行重定向
int ret = dup2(fdNormal, 1);
assert(ret != -1);
ret = dup2(fdError, 2);
assert(ret != -1);
for(int i = 10; i >= 0; i--)
cout << i << " "; //先打印部分信息
cout << endl;
int fd = open("cxk.txt", O_RDONLY); //打开不存在的文件
if(fd == -1)
{
//对于可能存在的错误信息,最好使用 perror / cerr 打印,方便进行重定向
cerr << "open fail! errno: " << errno << " | " << strerror(errno) << endl;
exit(-1); //退出程序
}
close(fd);
return 0;
}
在开发大型项目时,将 错误信息 单独剥离出来是一件很重要的事
3.缓冲区
缓冲区 其实就是一个 buffer 数组,配合不同的刷新策略,起到提高 IO 效率的作用
3.1缓冲区意义
CPU 计算速度非常快!而磁盘的读取速度相对于 CPU 来说是非常非常慢的,因此需要先将数据写入缓冲区中,依据不同的刷新策略,将数据刷新至内核缓冲区中,供 CPU 进行使用,这样做的是目的是尽可能的提高效率,节省调用者的时间
本来 IO 就慢,如果没有缓冲区的存在,那么速度会更慢,下面通过一个代码来看看是否进行 IO 时,CPU的算力差距
#include <iostream>
#include <unistd.h>
#include <signal.h>
using namespace std;
int count = 0;
int main()
{
//定一个 1 秒的闹钟,查看算力
alarm(1); //一秒后闹钟响起
while(true)
{
cout << count++ << endl;
}
return 0;
}
取消 IO
int count = 0;
void handler(int signo)
{
cout << "count: " << count << endl;
exit(1);
}
int main()
{
//定一个 1 秒的闹钟,查看算力
signal(14, handler);
alarm(1); //一秒后闹钟响起
while(true) count++;
return 0;
}
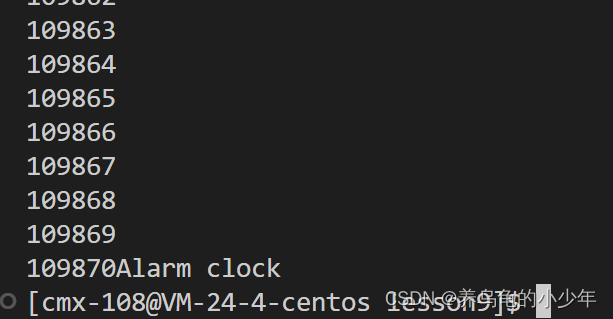
最终在没有 IO 的情况下,count 累加了 5亿+ 次,由此可以看出频繁 IO 对 CPU 计算的影响有多大,假若没有缓冲区,那么整个累加值将会更多(因为需要花费更多的时间在 IO 上)

因此在进行 读取 / 写入 操作时,常常会借助 缓冲区 buffer
#include <iostream>
#include <cassert>
#include <cstdio>
#include <cstring>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
using namespace std;
int main()
{
int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
assert(fd != -1);
char buffer[256] = { 0 }; //缓冲区
int n = read(0, buffer, sizeof(buffer)); //读取信息至缓冲区中
buffer[n] = '\0';
//写入成功后,在写入文件中
write(fd, buffer, strlen(buffer));
close(fd);
return 0;
}

3.2刷新策略
缓冲区有多种刷新策略,比如 C语言 中 scanf 的缓冲区刷新策略为:遇到空白字符或换行就刷新,因此在输入时需要按一下回车,缓冲区中的数据才能刷新至内核缓冲区中,而 printf 的刷新策略为 行缓冲,即遇到 \n 才会进行刷新
总体来说,缓冲区的刷新策略分为以下三种:
行缓冲(Line Buffering):在行缓冲模式下,缓冲区在遇到换行符 \n 时自动刷新。也就是说,当遇到换行符时,缓冲区中的数据会被立即写入文件
全缓冲(Fully Buffered):在全缓冲模式下,缓冲区满时会触发刷新,此时缓冲区中的数据才会被写入文件
手动刷新缓冲区:使用 fflush() 函数手动刷新缓冲区。这对于确保数据在特定时刻被写入文件很有用
关闭文件时刷新:当文件关闭时,C库会自动刷新缓冲
一般而言,显示器的刷新策略为 行缓冲,而普通文件的刷新策略为 全缓冲
一个简单的 demo 观察 行缓冲
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
while(true)
{
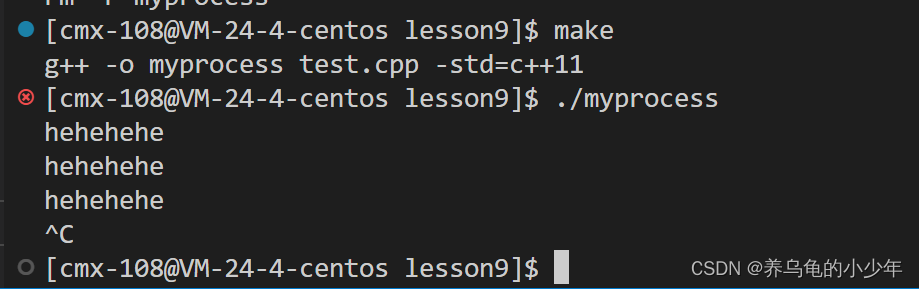
//未能触发行缓冲的刷新策略,只能等缓冲区满了被迫刷新
printf("%s", "hehehehe");
sleep(1);
}
return 0;
}
无法刷新 没有触发行刷新

修改代码:
while(true)
{
//能触发行缓冲的刷新策略
printf("%s\n", "hehehehe");
sleep(1);
}
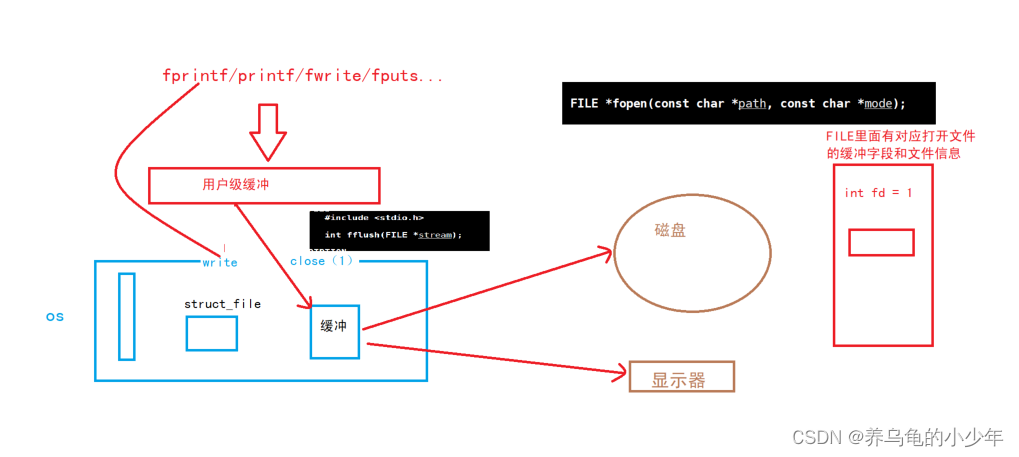
3.3用户级缓冲和内核级缓冲
每一个 file 对象中都有属于自己的缓冲区及刷新策略,而在系统中,还存在一个内核级缓冲区,这个缓冲区才是 CPU 真正进行 IO 的区域
IO 流程:
先将普通缓冲区中的数据刷新至内核级缓冲区中,CPU 再从内核级缓冲区中取数据进行运算,然后存入内核级缓冲区中,最后再由内核级缓冲区冲刷给普通缓冲区
4总结:
以上就是本次有关 Linux 基础IO【重定向及缓冲区理解】的全部内容了,在这篇文章中,我们深入理解了文件描述符的概念,学习了重定向的多种方法,最后还学习了缓冲区的相关知识,清楚了普通文件与特殊文件的不同刷新策略。















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









