







自定义函数
语法
delimiter $$
create function 函数名称(参数列表) returns 返回类型
begin
sql语句
end
$$
delimiter ;
说明: delimiter用于设置分割符,默认为分号,主要用于命令行,在“sql语句”部分编写的语句需要以分号结尾,此时回车会直接执行,所以要创建自定义函数前需要指定其它符号作为分割符,此处使用$$,也可以使用其它字符
示例
需求: 创建函数my_trim,用于删除字符串左右两侧的空格
step1: 设置分割符
del1miter $$
step2: 创建函数
create function my_trim(str varchar(100)) returns varchar(100)
begin
return ltrim(rtrim(str));
end
$$
step3: 还原分割符
delimiter ;
调用
直接在查询编辑器中执行,执行之后函数下会产生我们创建的自定义函数
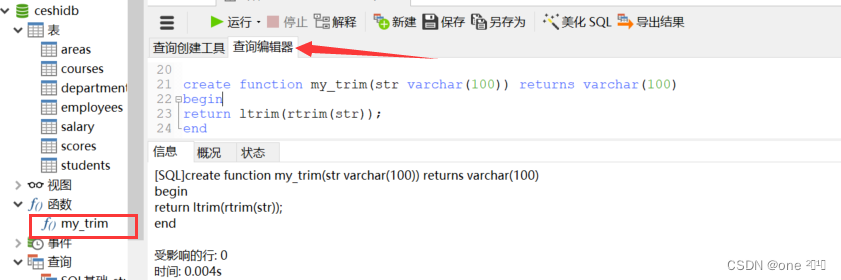
使用自定义函数
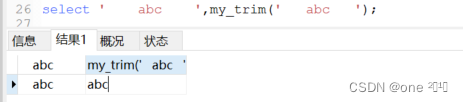
select ' abc ',my trim(' abc ')
存储过程
存储过程,也翻译为存储程序,是一条或者多条SQL语句的集合
语法
delimiter //
create procedure 存储过程名称(数列表)
begin
sq1语句
end//
delimiter ;
示例
需求:创建查询过程,查询学生信息。
step1: 设置分割符
delimiter //
step2:创建存储过程
create procedure proc_stul ()
beginselect * from students;
end//
step3: 还原分割符
delimiter;
调用
语法如下
call 存储过程(参数列表);
调用存储过程 proc-stu
call proc stu():
函数和存储过程的作用
- 存储过程和函数都是为了可重复的执行操作数据库的 sql 语句的集合
- 存储过程和函数都是一次编译,就会被缓存起来,下次使用就直接命中缓存中已经编译好的 sql,不需要重复编译
- 减少网络交互,减少网络访问流量
视图
问题
对于复杂的查询,在多个地方被使用,如果需求发生了改变,需要更改sql语句,则需要在多个地方进行修改,维护起来非常麻烦
解决: 定义视图
视图本质就是对查询的封装
语法:
定义视图,建议以v 开头
create wlew 视图名称 as
select语句;
例:
1、创建视图,查询学生对应的成绩信息
create view v_stu_score_course as
select
stu.*,cs.courseNo, cs.name courseName, sc.score
from
students stu
inner join scores sc on stu.studentNo = sc.studentNoinner join courses cs on cs.courseNo = sc.courseNo
注:视图中返回的结果不能有重名的字段,如果需要,则需给个别名

2、使用:视图的用途就是查询
select * from v stu score course;
3、查看视图:查看表会将所有的视图也列出来
show tables;
4、删除视图
drop view 视图名称;
例
drop view y stu score course;
事务
为什么要有事务
- 事务广泛的运用于订单系统、银行系统等多种场景
- 例如: A用户和B用户是银行的储户,现在A要给B转账500元,那么需要做以下几件事:0
1、检查A的账户余额>500元
2、A 账户中扣除500元:
3、B 账户中增加500元
- 正常的流程走下来,A账户扣了500,B账户加了500,皆大欢喜。那如果A账户扣了钱之后,系统出故障了呢? A白白损失了500,而B也没有收到本该属于他的500。以上的案例中,隐藏着一个前提条件: A扣钱和B加钱,要么同时成功,要么同时失败。事务的需求就在于此
- 所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转帐工作:从一个帐号扣款并使另一个帐号增款,这两个操作要么都执行,要么都不执行。所以,应该把他们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性
事务类型
所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
一:所有操作都执行成功
- 开启事务
- 提交事务
二:任何一步操作失败
- 开启事务
- 回滚事务
事务命令
要求: 表的引擎类型必须是innodb类型才可以使用事务,这是mysql表的默认引警。
表的创建语句,可以看到enginer=innodb
show create table students:
事务触发场景
修改数据的命令会触发事务,包括insert、update、delete
开启事务,命令如下:
开启事务后执行修改命令,变更会维护到本地缓存中,而不维护到物理表中
begin;
提交事务,命令如下
将缓存中的数据变更护到物理表中
commit;
回滚事务,命令如下:
放弃缓存中变更的数据
rollback;
提交
注:为了演示效果,需要打开两个命令行窗口,使用同一个数据库,操作同一张表
step1: 查询
命令行1和命令行2: 查询学生信息
select · from students where nane in("大乔 ,"小乔');
step2: 修改数据
命令行1: 开启事务,修改数据
begin;
update students set age=age-5 where name ="大乔";update students set age=age+5 where name="小乔";
命令行1:查询数据,发现数据已经变化
select * from students where name in('大乔 ','小乔');
step3:查询
命令行2:查询数据,发现数据没有变化
select · from students where nane in("大乔 ,"小乔");
step4:提交
命令行1:完成提交
commit;
step5: 查询
命令行2:查询数据,发现数据已经变化
select * from students where name in("大乔","小乔");
回滚
为了演示效果,需要打开两个命令行窗口,使用同一个数据库,操作同一张表
step1:查询
命令行1和命令行2: 查询学生信息
select * from students where name in ("大乔" ,"小乔");
step2: 修改数据
命令行1:开启事务,修改数据
begin:
update students set age=age-5 where name="大乔";update students set age=age+5 where name "小乔";
命令行1:查询数据,发现数据已经变化
select * from students where name in ("大乔" ,"小乔")
step3: 查询
命令行2:查询数据,发现数据没有变化
select * from students where name in("大乔" ,"小乔");
step4: 回滚
命令行1: 完成回滚
rollback;
step5: 查询
命令行1:查询数据,发现数据恢复为开启事务前的状态
select * from students where name in("大乔","小乔");
索引
一般的应用系统对比数据库的读写比例在10:1左右,而且插入操作和更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重当数据库中数据量很大时,查找数据会变得很慢
优化方案:索引
索引演示
导入测试表test index
右键点击某个数据库->运行sq1文件->选择test_1ndex.sq1->点击开始
查询
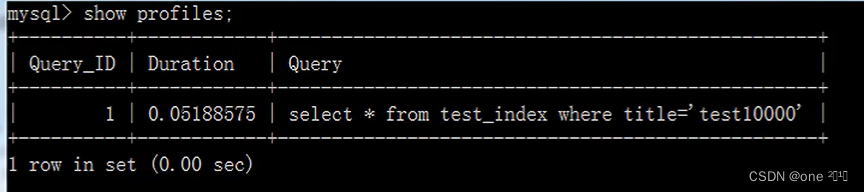
开启运行时间监测:
set profiling=1;
查找第1万条数据test10000
select * from test index where title="test10000"
查看执行的时间:
show profiles;
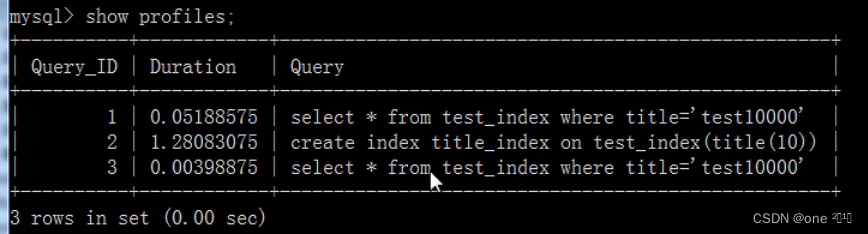
为表title index的title列创建索引:
create index title_index on test_index(title(10));
执行查询语句:
select * from test_index where title="test10000";
再次查看执行的时间
show profiles;
语法
查看索引
show index from 表名;

创建索引
方式一:建表时创建索引
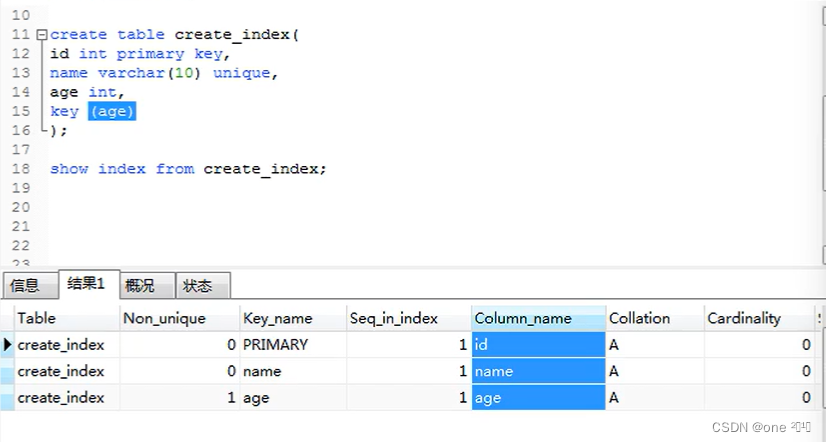
create table create_index(
id int primary key,
name varchar(10) unique,
age int,key (age)
);
- 主键列会自动创建索引
- 唯一约束会自动创建索引
- 使用key关键字创建索引
 方式二:对于已经存在的表,添加索引
方式二:对于已经存在的表,添加索引
create index 索引名称 on 表名(学段名称(长度))
- create index age_index on create_index(age);
- create index name_index on create_index(name(10));
注:如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致,字段类型如果不是字符串,可以不填写长度部分
删除索引:
drop index 索引名称 on 表名;
索引的作用
提高查询速度
索引的缺点
降低更新表的速度
分析查询
是否用到索引,在哪个表中用到了索引,可以使用分析查询
explain
select * from test_index where title="test10000"

















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









