






Hertz 是字节跳动服务框架团队研发的超大规模的企业级微服务 HTTP 框架,具有高易用性、易扩展、低时延等特点。在经过了字节跳动内部一年多的使用和迭代后,如今已在 CloudWeGo 正式开源。 目前,Hertz 已经成为了字节跳动内部最大的 HTTP 框架,线上接入的服务数量超过 1 万,峰值 QPS 超过 4 千万。除了各个业务线的同学使用外,也服务于内部很多基础组件, 如:函数计算平台 FaaS、压测平台、各类网关、Service Mesh 控制面等,均收到不错的使用反馈。在如此大规模的场景下,Hertz 拥有极强的稳定性和性能,在内部实践中某些典型服务, 如框架占比较高的服务、网关等服务,迁移 Hertz 后相比 Gin 框架,资源使用显著减少,CPU 使用率随流量大小降低 30%—60%,时延也有明显降低。
架构设计
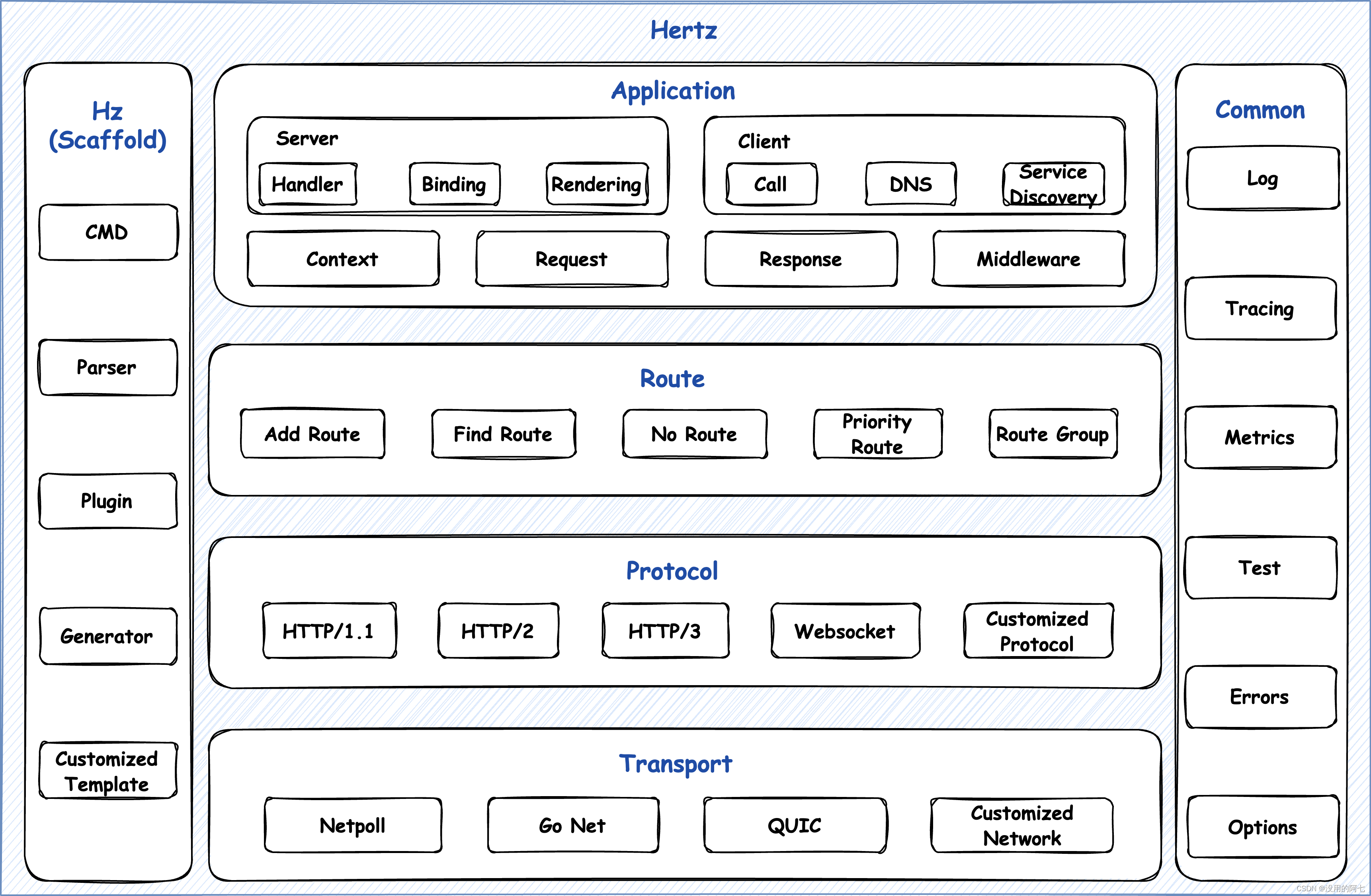
Hertz 从上到下分为:应用层、路由层、协议层和传输层,每一层各司其职,同时公共能力被统一抽象到公共层(Common),做到跨层级复用。 另外,同主库一同发布的还有作为子模块的 Hz 脚手架,它能够协助使用者快速搭建出项目核心骨架以及提供实用的构建工具链。
各层的能力及作用如下:
- 传输层 Transport:抽象网络接口;
- 协议层 Protocol:解析请求,渲染响应编码;
- 路由层 Route:基于URL进行逻辑分发;
- 应用层 Application:业务直接交互,出现大量 API。
路由层解读
Hertz路由层具有良好的通用性,主要提供静态路由、参数路由、为路由配置优先级以及路由修复的能力,如果路由层没办法满足用户需求, Hertz还能支撑用户做自定义路由的扩展。
Hertz 为满足用户需求重新构造了路由树,用户在注册路由时拥有很高的自由度:支持静态路由、参数路由的注册;支持按优先级匹配;支持路由回溯;支持尾斜线重定向。路由层的代码结构如下:
- consts
包含常量定义 - param
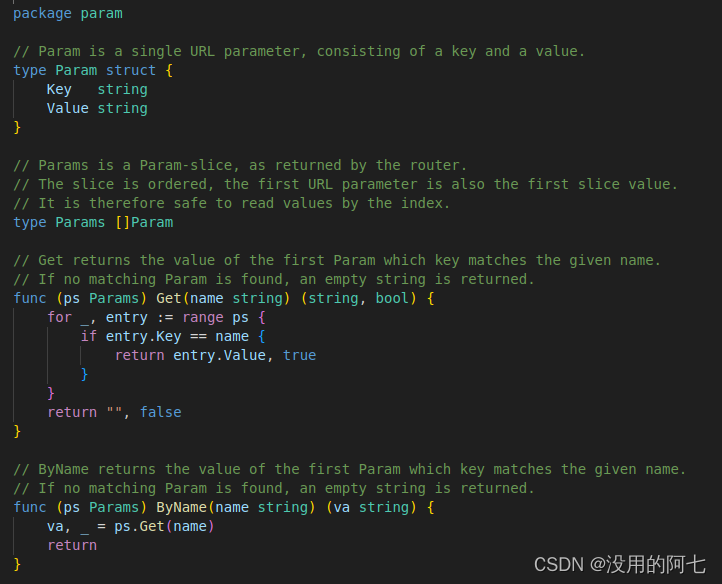
param.go定义了一个处理URL参数的包param,其中包含了类型定义、类型别名、方法定义:
-
类型定义:
Param结构体:定义了一个名为Param的结构体类型,它包含两个字段,Key和Value,分别用于存储URL参数的键和值,都是string类型。
-
类型别名:
Params类型别名:定义了一个Params类型,它是Param结构体的切片(即数组)。这个切片用于存储一系列的URL参数,并且保持参数的顺序。
-
方法定义:
Get方法:这是Params类型的方法,它接收一个参数name,这个参数是想要获取的URL参数的键名。方法遍历Params切片,找到键名匹配的Param项,并返回其值和true。如果没有找到匹配的项,则返回空字符串和false。ByName方法:这是Params类型的另一个方法,它与Get方法功能相似,但只返回参数的值,不返回是否存在的布尔值。如果找不到匹配的项,它将返回空字符串。
这两个方法提供了一种方便的方式来访问URL参数。Get方法返回两个值,一个是参数的值,另一个是表示是否找到该参数的布尔值,这允许调用者区分参数不存在和参数值为空的情况。而ByName方法则简化了这个过程,只返回参数的值,如果参数不存在则返回空字符串,这在某些情况下可以简化代码。
param.go用于从请求中解析和访问URL参数。例如,在一个Web应用中,如果一个请求的URL是http://example.com/api?name=John&age=30,使用这个param包可以方便地获取name和age参数的值。
- default.go && default_windows.go
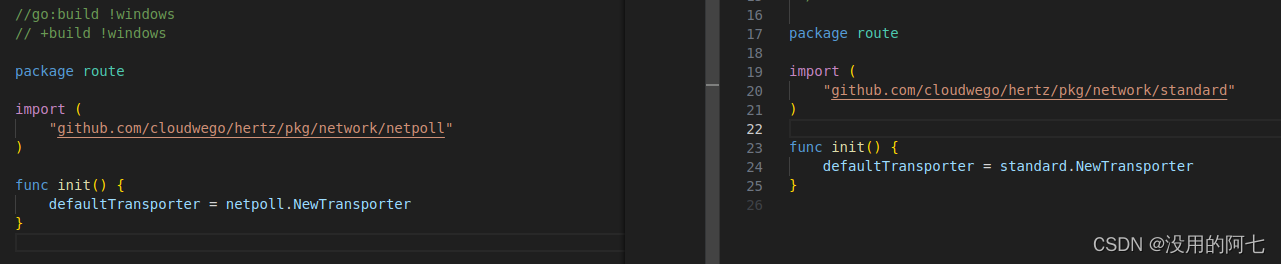
default.go是为非Windows环境设计,而default_windows.go是专门为Windows环境设计。在非Windows环境下,default.go使用netpoll.NewTransporter作为默认的网络传输器创建函数。而在Windows环境下,default_windows.go使用standard.NewTransporter作为默认的网络传输器创建函数。
- engine.go
1. 包和导入
engine.go文件定义了一个HTTP服务器的核心组件。
package route
import (
// ... 省略的导入语句
)
这个文件属于route包,并导入了一系列的包,用于实现网络通信、日志记录、配置管理等功能。
2. 定义常量和变量
const unknownTransporterName = "unknown"
var (
defaultTransporter = standard.NewTransporter
// ... 省略的其他变量
)
这里定义了一个字符串常量unknownTransporterName,用作未知传输器的名称。defaultTransporter是一个全局变量,用于设置默认的网络传输器。
3. Engine结构体
type Engine struct {
// ... 省略的结构体字段
}
Engine结构体包含了HTTP服务器所需的各种配置和状态信息,如路由信息、传输器、中间件、错误处理器等。
4. SetTransporter函数
func SetTransporter(transporter func(options *config.Options) network.Transporter) {
defaultTransporter = transporter
}
SetTransporter函数用于设置默认的传输器生成函数,这个函数可以根据配置生成传输器实例。
5. NewEngine函数
func NewEngine(opt *config.Options) *Engine {
// ... 省略的代码
return engine
}
NewEngine函数用于创建并初始化一个新的Engine实例。
6. ServeHTTP方法
func (engine *Engine) ServeHTTP(c context.Context, ctx *app.RequestContext) {
// ... 省略的代码
}
ServeHTTP方法使得Engine结构体实现了HTTP处理器接口,能够处理HTTP请求。
7. 路由处理
func (engine *Engine) addRoute(method, path string, handlers app.HandlersChain) {
// ... 省略的代码
}
addRoute方法用于向Engine添加新的路由规则。
8. 启动和关闭服务器
func (engine *Engine) Run() (err error) {
// ... 省略的代码
}
func (engine *Engine) Close() error {
// ... 省略的代码
}
Run方法用于启动HTTP服务器,而Close方法用于优雅地关闭服务器。
9. 处理请求和错误
func serveError(c context.Context, ctx *app.RequestContext, code int, defaultMessage []byte) {
// ... 省略的代码
}
serveError是一个辅助函数,用于处理请求错误,并返回相应的HTTP状态码。
其中addRoute函数是HTTP服务器中处理路由注册和核心部分。
addRoute 函数
addRoute 函数用于将新的路由添加到Engine的路由树中。以下是函数的步骤和关键点:
- 首先,函数检查传入的
path是否为空,如果为空,则会引发一个panic,因为HTTP路径不能为空。 - 然后,使用
utils.Assert函数确保路径以'/'开头,HTTP方法method不为空,并且处理函数handlers至少有一个。这些断言有助于确保路由的合法性。 - 如果没有禁用打印路由信息(
DisablePrintRoute为false),将调用debugPrintRoute函数打印路由信息,这有助于调试和查看注册的路由。 - 接下来,函数尝试通过
engine.trees.get(method)获取指定HTTP方法的路由器。如果该方法的路由器不存在,将创建一个新的路由器并添加到engine.trees数组中。 - 使用
methodRouter.addRoute(path, handlers)将新路由添加到路由器中。 - 函数计算路径中的参数数量,如果这个数量超过了之前记录的最大参数数量,将更新
engine.maxParams。
func (engine *Engine) addRoute(method, path string, handlers app.HandlersChain) {
// 确保路径不为空且以'/'开头,HTTP方法不为空,处理函数至少有一个
if len(path) == 0 {
panic("path should not be ''")
}
utils.Assert(path[0] == '/', "path must begin with '/'")
utils.Assert(method != "", "HTTP method can not be empty")
utils.Assert(len(handlers) > 0, "there must be at least one handler")
// 打印路由信息,如果未禁用
if !engine.options.DisablePrintRoute {
debugPrintRoute(method, path, handlers)
}
// 获取或创建对应HTTP方法的路由器,并添加路由
methodRouter := engine.trees.get(method)
if methodRouter == nil {
methodRouter = &router{method: method, root: &node{}, hasTsrHandler: make(map[string]bool)}
engine.trees = append(engine.trees, methodRouter)
}
methodRouter.addRoute(path, handlers)
// 更新参数数量
if paramsCount := countParams(path); paramsCount > engine.maxParams {
engine.maxParams = paramsCount
}
}
- routegroup.go
routegroup.go是Go语言Web框架Hertz的一部分,定义了路由分组(Router Group)的功能。路由分组允许开发者将具有相同前缀或中间件的路由组织在一起。
定义接口
首先,定义了两个接口IRouter和IRoutes,它们包含了路由处理所需的所有方法。
// IRouter defines all router handle interface includes single and group router.
type IRouter interface {
IRoutes
Group(string, ...app.HandlerFunc) *RouterGroup
}
// IRoutes defines all router handle interface.
type IRoutes interface {
Use(...app.HandlerFunc) IRoutes
// ... 其他HTTP方法的声明
}
IRouter接口扩展了IRoutes接口,添加了Group方法,用于创建新的路由分组。
RouterGroup 结构体
RouterGroup结构体是路由分组的实现,它包含中间件链(Handlers)、基础路径(basePath)和关联的Engine。
// RouterGroup is used internally to configure router, a RouterGroup is associated with
// a prefix and an array of handlers (middleware).
type RouterGroup struct {
Handlers app.HandlersChain
basePath string
engine *Engine
root bool
}
Use 方法
Use方法用于向当前路由分组添加中间件。
func (group *RouterGroup) Use(middleware ...app.HandlerFunc) IRoutes {
group.Handlers = append(group.Handlers, middleware...)
return group.returnObj()
}
Group 方法
Group方法用于创建一个新的子路由分组,可以有新的前缀和中间件。
func (group *RouterGroup) Group(relativePath string, handlers ...app.HandlerFunc) *RouterGroup {
return &RouterGroup{
Handlers: group.combineHandlers(handlers),
basePath: group.calculateAbsolutePath(relativePath),
engine: group.engine,
}
}
处理HTTP方法的快捷方法
代码中定义了一系列快捷方法,如GET、POST、PUT等,它们是Handle方法的封装,用于根据不同的HTTP方法注册路由。
// GET is a shortcut for router.Handle("GET", path, handle).
func (group *RouterGroup) GET(relativePath string, handlers ...app.HandlerFunc) IRoutes {
return group.handle(consts.MethodGet, relativePath, handlers)
}
Static 、 StaticFile 方法 和 StaticFS 方法
Static 、StaticFile 和 StaticFS 方法为路由分组(RouterGroup)中处理静态文件和文件夹的方法。
1. StaticFile 方法
StaticFile 方法用于注册单个路由,以便从本地文件系统提供单个文件的服务。例如,可以设置一个路由来提供网站的 favicon.ico 文件。
func (group *RouterGroup) StaticFile(relativePath, filepath string) IRoutes {
// 检查路由路径是否包含 URL 参数,这在服务静态文件时是不允许的
if strings.Contains(relativePath, ":") || strings.Contains(relativePath, "*") {
panic("URL parameters can not be used when serving a static file")
}
// 定义处理函数,使用 RequestContext 的 File 方法来提供文件服务
handler := func(c context.Context, ctx *app.RequestContext) {
ctx.File(filepath)
}
// 为相对路径注册 GET 和 HEAD 请求的处理函数
group.GET(relativePath, handler)
group.HEAD(relativePath, handler)
// 返回当前的 IRoutes 对象,可以是 RouterGroup 或 Engine
return group.returnObj()
}
这个方法首先检查提供的相对路径是否包含 URL 参数(: 或 *),如果包含,则会抛出一个错误,因为静态文件服务不支持 URL 参数。然后,定义了一个处理函数,使用 RequestContext 的 File 方法来响应请求并提供指定路径的文件。最后,为这个路径注册了 GET 和 HEAD 请求的处理函数,并返回当前的路由对象。
2. Static 方法
Static 方法用于注册一个路由,以便从给定的文件系统根目录提供服务。
func (group *RouterGroup) Static(relativePath, root string) IRoutes {
// 使用 StaticFS 方法并传入一个基于操作系统文件系统的 app.FS 实例
return group.StaticFS(relativePath, &app.FS{Root: root})
}
这个方法是一个便利方法,它使用 StaticFS 方法并传入一个 app.FS 实例,该实例使用操作系统的文件系统。
3. StaticFS 方法
StaticFS 方法类似于 Static,但它允许使用自定义的 FS 来提供静态文件服务。
func (group *RouterGroup) StaticFS(relativePath string, fs *app.FS) IRoutes {
// 与 StaticFile 类似,检查路由路径是否包含 URL 参数
if strings.Contains(relativePath, ":") || strings.Contains(relativePath, "*") {
panic("URL parameters can not be used when serving a static folder")
}
// 创建一个请求处理函数,使用 FS 的 NewRequestHandler 方法
handler := fs.NewRequestHandler()
// 构造 URL 模式,用于匹配路径和任意文件路径
urlPattern := path.Join(relativePath, "/*filepath")
// 为 URL 模式注册 GET 和 HEAD 请求的处理函数
group.GET(urlPattern, handler)
group.HEAD(urlPattern, handler)
// 返回当前的 IRoutes 对象
return group.returnObj()
}
这个方法首先检查路径是否包含 URL 参数,然后创建一个请求处理函数,该函数将使用 FS 的 NewRequestHandler 方法来提供文件服务。接着,构造一个 URL 模式,用于匹配路径和后续的任意文件路径(使用 *filepath 作为通配符)。最后,为这个模式注册 GET 和 HEAD 请求的处理函数,并返回当前的路由对象。
辅助方法
1. combineHandlers 方法
combineHandlers 方法用于合并当前路由分组的中间件和新提供的中间件。
func (group *RouterGroup) combineHandlers(handlers app.HandlersChain) app.HandlersChain {
// 计算合并后的中间件链的大小
finalSize := len(group.Handlers) + len(handlers)
// 如果合并后的中间件数量超过了预设的限制,则抛出错误
if finalSize >= int(rConsts.AbortIndex) {
panic("too many handlers")
}
// 创建一个新的中间件链并复制现有和新的中间件
mergedHandlers := make(app.HandlersChain, finalSize)
copy(mergedHandlers, group.Handlers)
copy(mergedHandlers[len(group.Handlers):], handlers)
// 返回合并后的中间件链
return mergedHandlers
}
这个方法首先计算合并现有中间件和新中间件后的大小,然后检查是否超过了最大限制(rConsts.AbortIndex)。如果没有超过限制,它会创建一个新的中间件链,将现有中间件和新中间件复制进去,并返回这个合并后的中间件链。
2. calculateAbsolutePath 方法
calculateAbsolutePath 方法用于计算相对路径和当前路由分组的基础路径合并后的绝对路径。
func (group *RouterGroup) calculateAbsolutePath(relativePath string) string {
// 使用 joinPaths 函数合并基础路径和相对路径
return joinPaths(group.basePath, relativePath)
}
这个方法使用一个辅助函数 joinPaths(在代码中未显示,但可以推断其功能)来合并 RouterGroup 的 basePath 和提供的相对路径,返回完整的绝对路径。
4. returnObj 方法
returnObj 方法用于确定返回给调用者的 IRoutes 对象是当前的路由分组还是整个路由引擎。
func (group *RouterGroup) returnObj() IRoutes {
// 如果是根路由分组,返回引擎;否则返回当前分组
if group.root {
return group.engine
}
return group
}
这个方法检查当前的路由分组是否是根分组,如果是,则返回关联的路由引擎(Engine);否则返回当前的路由分组对象。这允许在调用链的末尾返回一个更高级别的对象,从而提供更广泛的路由定义能力。
这些方法共同构成了Hertz框架中路由分组处理静态资源请求的能力,并通过中间件链的概念提供了灵活的路由处理方式。
- tree.go
tree.go实现了一个用于处理HTTP请求路由的树状结构。
文件tree.go实现了一个用于处理HTTP请求路由的树状结构。以下是对代码中关键部分的摘录和解释:
定义 Router 结构体
type router struct {
method string
root *node
hasTsrHandler map[string]bool
}
这是主要的路由器结构,包含HTTP方法、根节点以及一个映射,用于存储具有尾部斜杠重定向处理程序的路径。
定义 MethodTrees 类型
type MethodTrees []*router
这是一个路由器切片的别名,用于存储不同HTTP方法的路由器。
get 方法
func (trees MethodTrees) get(method string) *router {
for _, tree := range trees {
if tree.method == method {
return tree
}
}
return nil
}
get方法用于根据HTTP方法获取相应的路由器实例。
countParams 函数
func countParams(path string) uint16 {
var n uint16
s := bytesconv.S2b(path)
n += uint16(bytes.Count(s, bytestr.StrColon))
n += uint16(bytes.Count(s, bytestr.StrStar))
return n
}
countParams函数用于计算路径字符串中参数的数量。
定义 Node 结构体
type node struct {
kind kind
label byte
prefix string
parent *node
children children
// original path
ppath string
// param names
tpnames []string
handlers app.HandlersChain
paramChild *node
anyChild *node
// isLeaf indicates that node does not have child routes
isLeaf bool
}
node结构体代表路由树中的节点,包含节点类型、标签、前缀、父节点、子节点、原始路径、参数名称、处理程序链、参数子节点、任意子节点和叶子节点标志。
定义 Kind 常量
const (
skind kind = iota // static kind
pkind // param kind
akind // all kind
paramLabel = byte(':') // param label
anyLabel = byte('*') // any label
slash = "/" // slash
nilString = "" // nil string
)
定义了路由节点的类型和一些常量。
在tree.go文件中,有几个函数对于路由树的构建和查找过程至关重要。
1. addRoute 方法
// addRoute 方法用于将指定的路由规则添加到路由器中。
func (r *router) addRoute(path string, h app.HandlersChain) {
// 检查路径是否有效,例如是否以 '/' 开头,是否包含有效的参数和通配符。
checkPathValid(path)
// 初始化用于存储参数名称的切片和原始路径。
var (
pnames []string // 用于存储路径参数名称。
ppath = path // 保存传入的原始路径。
)
// 如果传入的处理函数是 nil,则抛出错误。
if h == nil {
panic(fmt.Sprintf("Adding route without handler function: %v", path))
}
// 遍历路径字符串,处理静态路由、参数路由和通配符路由。
for i, lcpIndex := 0, len(path); i < lcpIndex; i++ {
// 如果当前字符是参数标记(':'),则识别参数部分。
if path[i] == paramLabel {
j := i + 1 // 参数名称开始的索引。
// 插入静态路由部分到树中。
r.insert(path[:i], nil, skind, nilString, nil)
// 找到参数部分的结束位置。
for ; i < lcpIndex && path[i] != '/'; i++ {
}
// 将参数名称添加到列表中,并更新路径字符串。
pnames = append(pnames, path[j:i])
path = path[:j] + path[i:]
i, lcpIndex = j, len(path)
// 如果参数部分是路径的最后一个片段,则将其与处理程序一起插入树中。
if i == lcpIndex {
r.insert(path[:i], h, pkind, ppath, pnames)
return
} else {
// 否则,仅插入参数节点,不包含处理程序。
r.insert(path[:i], nil, pkind, nilString, pnames)
}
} else if path[i] == anyLabel {
// 如果当前字符是通配符标记('*'),则处理通配符路由。
// 插入静态路由部分到树中。
r.insert(path[:i], nil, skind, nilString, nil)
// 将通配符名称添加到列表中,并更新路径字符串。
pnames = append(pnames, path[i+1:])
// 插入通配符节点,并关联处理程序。
r.insert(path[:i+1], h, akind, ppath, pnames)
return
}
}
// 如果路径中没有参数或通配符,或者处理完它们之后,将剩余的静态路由插入树中。
r.insert(path, h, skind, ppath, pnames)
}
addRoute方法用于将一个新的路由添加到路由器中,这个函数是路由注册过程的核心。它首先验证路径格式,然后根据路径中的静态部分、参数(用:标识)和通配符(用*标识)递归地构建树节点。在处理参数和通配符时,它会先将路径的静态部分添加到树中,然后为参数或通配符创建特殊的节点,并在必要时将处理程序(h)与这些节点关联。如果路径中包含参数或通配符,它们会在路径字符串中被替换,以反映实际存储在树中的结构。最后,如果路径是一个静态字符串且没有参数或通配符,它将作为一个静态路由被添加到树中,并与相应的处理程序关联。
2. insert 方法
// insert 方法尝试将新路由添加到路由树中。
func (r *router) insert(path string, h app.HandlersChain, t kind, ppath string, pnames []string) {
// 从根节点开始。
currentNode := r.root
if currentNode == nil {
panic("hertz: invalid node") // 如果根节点是无效的,抛出错误。
}
search := path // 当前搜索的路径片段。
for {
// 计算当前搜索路径和当前节点前缀的长度。
searchLen := len(search)
prefixLen := len(currentNode.prefix)
lcpLen := 0 // 最长公共前缀长度。
// 确定最长公共前缀。
max := prefixLen
if searchLen < max {
max = searchLen
}
for ; lcpLen < max && search[lcpLen] == currentNode.prefix[lcpLen]; lcpLen++ {
}
// 如果最长公共前缀长度为0,说明当前节点和搜索路径没有共同前缀。
if lcpLen == 0 {
// 在根节点处分配新路径。
currentNode.label = search[0]
currentNode.prefix = search
if h != nil {
// 如果提供了处理程序,设置节点的类型、处理程序等。
currentNode.kind = t
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}
// 更新叶子节点状态。
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
} else if lcpLen < prefixLen {
// 需要分割当前节点,因为新路径和当前节点的前缀有部分匹配,但不完全匹配。
// 创建新节点,用于分割后的路径。
n := newNode(
// ... 传递参数给 newNode,创建新节点 ...
)
// 如果当前节点有子节点或特殊类型的子节点(paramChild 或 anyChild),更新它们的父节点为新创建的节点。
for _, child := range currentNode.children {
child.parent = n
}
// 重置当前节点的状态,为新路径做准备。
currentNode.kind = skind
// ... 重置 currentNode 的其他字段 ...
// 将新节点添加到当前节点的子节点列表。
currentNode.children = append(currentNode.children, n)
// 如果已处理完搜索路径,设置当前节点的处理程序等信息。
if lcpLen == searchLen {
currentNode.kind = t
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
} else {
// 继续递归创建子节点。
n = newNode(
// ... 为剩余路径创建新节点 ...
)
// 添加新创建的节点到当前节点的子节点列表。
currentNode.children = append(currentNode.children, n)
}
// 更新叶子节点状态。
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
} else if lcpLen < searchLen {
// 继续搜索剩余的路径片段。
search = search[lcpLen:] // 更新剩余的搜索路径。
// 尝试找到与剩余路径片段第一个字符匹配的子节点。
c := currentNode.findChildWithLabel(search[0])
if c != nil {
// 如果找到子节点,继续在该子节点上递归。
currentNode = c
continue
}
// 如果没有找到子节点,创建一个新的子节点。
n := newNode(
// ... 为剩余路径创建新节点 ...
)
// 根据新节点的类型,将其添加到适当的子节点列表。
switch t {
case skind:
currentNode.children = append(currentNode.children, n)
case pkind:
currentNode.paramChild = n
case akind:
currentNode.anyChild = n
}
// 更新叶子节点状态。
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
} else {
// 路径已经完全匹配到当前节点。
// 如果当前节点已经有处理程序,并且尝试再次添加处理程序,则报错。
if currentNode.handlers != nil && h != nil {
panic("handlers are already registered for path '" + ppath + "'")
}
// 如果提供了处理程序,更新当前节点的处理程序等信息。
if h != nil {
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}
}
return // 完成插入操作。
}
}
insert方法是addRoute的一个辅助方法,用于递归地将路由信息插入到树的适当位置。它处理节点的创建和分割,确保树的结构正确地反映了路由的定义。
3. find 方法
func (r *router) find(path string, paramsPointer *param.Params, unescape bool) (res nodeValue) {
// ... 省略代码 ...
}
find方法是查找路由的核心,它根据请求的路径在树中搜索相应的处理程序。它还处理URL参数的解析,并将结果存储在param.Params结构中。此方法对于处理进入的HTTP请求并确定适当的处理程序至关重要。insert 方法的核心是处理路由路径的递归插入,同时确保树的每个节点正确地表示路径的每个部分。它处理了几种情况,包括在根节点处开始新路径、在树中分割现有节点以适应新路径,以及在现有节点下创建新的子节点。这个过程确保了路由树的结构能够高效地处理路由匹配和参数解析。
4. checkPathValid 函数
// checkPathValid 函数检查提供的路径是否有效。
func checkPathValid(path string) {
// 如果路径为空字符串,则抛出错误。
if path == nilString {
panic("empty path")
}
// 路径必须以 '/' 开头,否则抛出错误。
if path[0] != '/' {
panic("path must begin with '/'")
}
// 遍历路径字符串的每个字节。
for i, c := range []byte(path) {
// 根据当前字符判断其类型(参数或通配符)。
switch c {
case ':': // 命名参数的开始。
// 如果命名参数后面紧跟着 '/' 或是路径的最后一个字符,则抛出错误。
if (i < len(path)-1 && path[i+1] == '/') || i == (len(path)-1) {
panic("wildcards must be named with a non-empty name in path '" + path + "'")
}
// 移动到命名参数的名称部分。
i++
// 检查命名参数的名称是否只包含一个字符。
for ; i < len(path) && path[i] != '/'; i++ {
// 路径片段中只能有一个命名参数或通配符。
if path[i] == ':' || path[i] == '*' {
panic("only one wildcard per path segment is allowed, find multi in path '" + path + "'")
}
}
case '*': // 通配符。
// 通配符不能是路径的最后一个字符,除非它位于路径的末端。
if i == len(path)-1 {
panic("wildcards must be named with a non-empty name in path '" + path + "'")
}
// 通配符前必须有 '/'。
if i > 0 && path[i-1] != '/' {
panic(" no / before wildcards in path " + path)
}
// 检查通配符是否位于路径片段的开始。
for ; i < len(path); i++ {
if path[i] == '/' {
panic("catch-all routes are only allowed at the end of the path in path '" + path + "'")
}
}
}
}
}
这个函数通过对路径字符串的每个字符进行迭代检查,确保路径满足以下条件:
- 路径不能为空,且必须以/开头。
- 命名参数(例如:variable)必须有名称,且每个路径片段只能有一个命名参数或通配符。
- 通配符(*)必须位于路径片段的末尾,且其前面必须有/。
如果路径不符合这些规则,函数将通过panic抛出一个错误,提供有关问题的具体信息。这有助于在注册路由时捕捉和修复路径定义错误。
5. findCaseInsensitivePath 方法
// 定义一个方法findCaseInsensitivePath,它是node结构体的一个实例方法。
// 参数path是待查找的路径字符串,fixTrailingSlash是一个布尔值,表示是否修复尾部斜杠。
// 返回值ciPath是找到的路径的字节切片,found是一个布尔值,表示是否找到匹配的路径。
func (n *node) findCaseInsensitivePath(path string, fixTrailingSlash bool) (ciPath []byte, found bool) {
ciPath = make([]byte, 0, len(path)+1) // 预分配足够的内存空间以存储路径
// 匹配paramKind类型的节点。
if n.label == paramLabel {
end := 0
// 找到path中第一个'/'的位置。
for end < len(path) && path[end] != '/' {
end++
}
// 将path的开始部分添加到ciPath中。
ciPath = append(ciPath, path[:end]...)
// 如果找到了'/',处理后续的子路径。
if end < len(path) {
if len(n.children) > 0 {
path = path[end:] // 截取子路径继续查找
// 跳转到loop标签,继续查找。
goto loop
}
// 如果没有子节点,检查是否需要修复尾部斜杠。
if fixTrailingSlash && len(path) == end+1 {
return ciPath, true
}
return // 如果没有找到匹配,返回
}
// 如果当前节点有处理器,返回当前路径和true。
if n.handlers != nil {
return ciPath, true
}
// 如果只有一个子节点,检查是否修复尾部斜杠。
if fixTrailingSlash && len(n.children) == 1 {
// 没有找到处理器。检查是否存在带或不带尾部斜杠的处理器。
n = n.children[0]
if n.prefix == "/" && n.handlers != nil {
return append(ciPath, '/'), true
}
}
return // 如果没有找到匹配,返回
}
// 匹配anyLabel类型的节点,表示匹配任何路径。
if n.label == anyLabel {
return append(ciPath, path...), true
}
// 匹配静态路径。
if len(path) >= len(n.prefix) && strings.EqualFold(path[:len(n.prefix)], n.prefix) {
path = path[len(n.prefix):] // 截取匹配后的子路径
ciPath = append(ciPath, n.prefix...) // 将匹配的前缀添加到ciPath中
// 如果子路径为空,检查是否有处理器。
if len(path) == 0 {
if n.handlers != nil {
return ciPath, true
}
// 没有找到处理器,尝试添加尾部斜杠修复路径。
if fixTrailingSlash {
for i := 0; i < len(n.children); i++ {
if n.children[i].label == '/' {
n = n.children[i]
if (len(n.prefix) == 1 && n.handlers != nil) ||
(n.prefix == "*" && n.children[0].handlers != nil) {
return append(ciPath, '/'), true
}
return // 如果没有找到匹配,返回
}
}
}
return // 如果没有找到匹配,返回
}
} else if fixTrailingSlash {
// 没有找到静态路径匹配,尝试修复尾部斜杠。
if path == "/" {
return ciPath, true
}
// 如果前缀与path匹配,只是差一个尾部斜杠。
if len(path)+1 == len(n.prefix) && n.prefix[len(path)] == '/' &&
strings.EqualFold(path, n.prefix[:len(path)]) &&
n.handlers != nil {
return append(ciPath, n.prefix...), true
}
}
loop:
// 首先匹配静态类型的子节点。
for _, node := range n.children {
if unicode.ToLower(rune(path[0])) == unicode.ToLower(rune(node.label)) {
// 递归查找子节点。
out, found := node.findCaseInsensitivePath(path, fixTrailingSlash)
if found {
return append(ciPath, out...), true
}
}
}
// 如果有参数类型的子节点,递归查找。
if n.paramChild != nil {
out, found := n.paramChild.findCaseInsensitivePath(path, fixTrailingSlash)
if found {
return append(ciPath, out...), true
}
}
// 如果有任意类型的子节点,递归查找。
if n.anyChild != nil {
out, found := n.anyChild.findCaseInsensitivePath(path, fixTrailingSlash)
if found {
return append(ciPath, out...), true
}
}
// 如果没有找到匹配,检查是否可以推荐重定向到不带尾部斜杠的相同URL。
found = fixTrailingSlash && path == "/" && n.handlers != nil
return // 返回最终结果
}
findCaseInsensitivePath方法用于进行不区分大小写的路径查找,并且能够处理尾部斜杠的修复。这使得路由匹配更加灵活,允许在忽略大小写和尾部斜杠的情况下匹配路径。
6. newNode 函数
// 定义一个名为newNode的函数,用于创建一个新的node实例。
// 参数t是节点类型,pre是节点的前缀字符串,p是父节点的指针,
// child是子节点列表,mh是处理器链,ppath是路径字符串,
// pnames是参数名称列表,paramChildren是参数类型的子节点,
// anyChildren是任意类型的子节点。
func newNode(t kind, pre string, p *node, child children, mh app.HandlersChain, ppath string, pnames []string, paramChildren, anyChildren *node) *node {
// 返回一个新的node实例,使用传入的参数初始化其字段。
return &node{
kind: t, // 节点类型
label: pre[0], // 节点标签,取前缀字符串的第一个字符
prefix: pre, // 节点前缀
parent: p, // 父节点指针
children: child, // 子节点列表
ppath: ppath, // 路径字符串
pnames: pnames, // 参数名称列表
handlers: mh, // 处理器链
paramChild: paramChildren, // 参数类型的子节点
anyChild: anyChildren, // 任意类型的子节点
// 判断当前节点是否为叶子节点,即没有子节点、参数子节点或任意子节点
isLeaf: child == nil && paramChildren == nil && anyChildren == nil,
}
}
newNode函数用于创建新的树节点。它初始化节点的所有属性,包括节点类型、标签、前缀、父节点、子节点列表、处理程序链、原始路径、参数名称以及特殊类型的子节点(参数子节点和任意子节点)。
这些函数共同构成了路由树的核心功能,使得Web框架能够注册路由、匹配请求路径,并执行相应的处理程序。















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









