







 Matplotlib 绘制直方图,matplotlib.pyplot.hist()详细用法。
Matplotlib 绘制直方图,matplotlib.pyplot.hist()详细用法。
Matplotlib学习笔记003 绘制直方图
文章目录
一、matplotlib.pyplot.hist()
直方图(Histogram),又称质量分布图,是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据类型,纵轴表示分布情况。
使用matplotlib.pyplot.hist函数绘制直方图,函数具体如下:
matplotlib.pyplot.hist(x, bins=None, range=None, density=False, weights=None, cumulative=False, bottom=None, histtype='bar', align='mid', orientation='vertical', rwidth=None, log=False, color=None, label=None, stacked=False, *, data=None, **kwargs)
主要参数说明
# x: 数组或者可以循环的序列。直方图将会从这组数据中进行分组。
# bins: 整数或者序列(数组/列表等)。如果bins为整数,代表的是要均分成多少组。如果是序列,那么就会按照序列中指定的值进行分组。比如bins=[1,2,3,4],那么分组的时候会按照三个区间分成3组,分别是[1,2)/[2,3)/[3,4]。
# range: 元组或者None。bins是整数时,若range为元组且则指定bins的下限和上限范围,忽略上下异常值。若range为None,则指定范围为(x.min(), x.max()),如果bin是一个序列(已指定范围了),那么range没有有没有设置没有任何影响。
# density: 默认是False,如果等于True,那么将会使用频率分布直方图。每个条形表示的不是个数,而是频率/组距(落在各组样本数据的个数称为频数,频数除以样本总个数为频率)。
# weights: 与x形状相同的权重数组。x中的每个值仅将其相关权重贡献给bins计数(而不是 1)。如果密度为True,则权重被归一化,因此密度在该范围内的积分保持为 1。
# cumulative: 如果这个和density都等于True,那么返回值的第一个参数会不断的累加,最终等于1。
# bottom: 每个组图形底部的位置。如果是标量,则每个箱的底部移动相同的量。如果是数组,则每个 bin 都会独立移动,并且底部的长度必须与组数bins的数量相匹配。如果没有,默认为 0。
# histtype: 要绘制的直方图类型。四种取值{'bar', 'barstacked', 'step', 'stepfilled'},默认值:'bar'
# 四种取值的具体含义如下:
'bar' 是传统的条形直方图。如果给出多个数据,则条形图并排排列。
'barstacked' 是一种条形直方图,其中多个数据堆叠在一起。
'step' 生成默认未填充的线图。
'stepfilled' 生成一个默认填充的线图。
# align: 直方图条的水平对齐方式。三种取值{'left', 'mid', 'right'},默认值:'mid'
# orientation: 垂直方向,两种取值{'vertical', 'horizontal'}, 默认值: 'vertical'
# rwidth : float,None,默认为None。表示条的相对宽度,作为 bin 宽度的一部分。如果 None,则自动计算宽度。若histtype为'step' 或 'stepfilled' 则忽略。
# log : 日志,Bool类型,默认为False。如果True,直方图轴将设置为对数刻度。
# color : 颜色、颜色序列或None。默认为None,使用标准线条颜色序列。
# label : 标签,str,None类型,默认为None.字符串或字符串序列以匹配多个数据集。条形图为每个数据集生成多个补丁,但只有第一个获得标签,可以使用图列legend()
# stacked : 堆叠,Bool类型,默认为False。若为True, 则多个数据相互堆叠;若为False时,histtype='bar',则多个数据并排排列,histtype='step'则多个数据堆叠在一起。
# egdecolor:直方图边框颜色,
该函数有三个返回值,具体如下:
# 参数顺序(num,bins,patches)
# n:数组。每个区间内值出现的个数,如果density=True,那么这个将返回的是频率/组距。
# bins:数组。区间的值。
# patches:BarContainer或单个多边形的列表或此类对象的列表。
二、部分参数详解
1. bins
bins为整数或者序列(数组/列表等)。如果bins为整数,代表的是要均分成多少组。如果是序列,那么就会按照序列中指定的值进行分组。比如bins=[1,2,3,4], 那么分组的时候会按照三个区间分成3组,分别是[1,2)/[2,3)/[3,4]。
bins为整数时
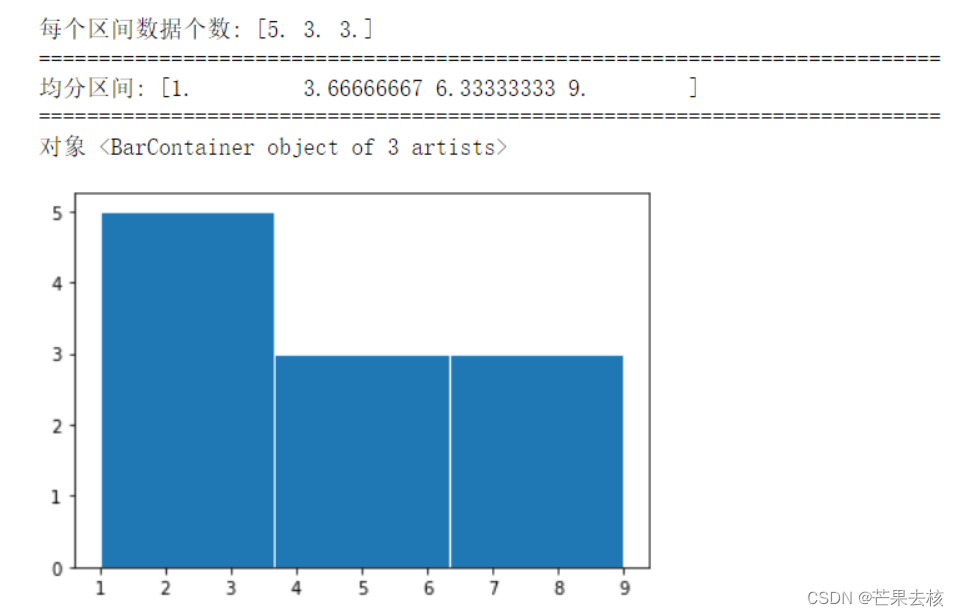
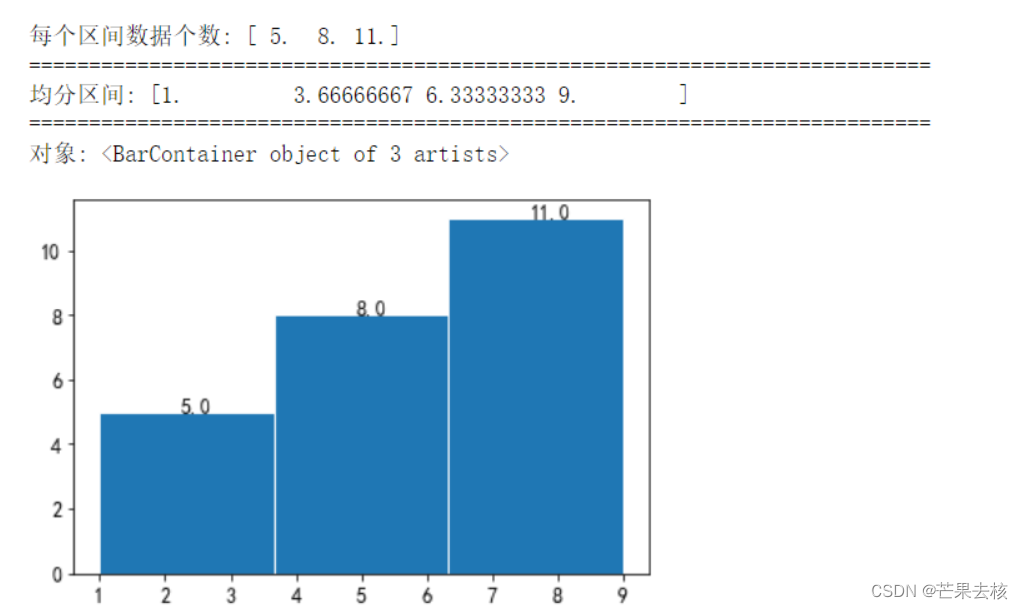
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=3,edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
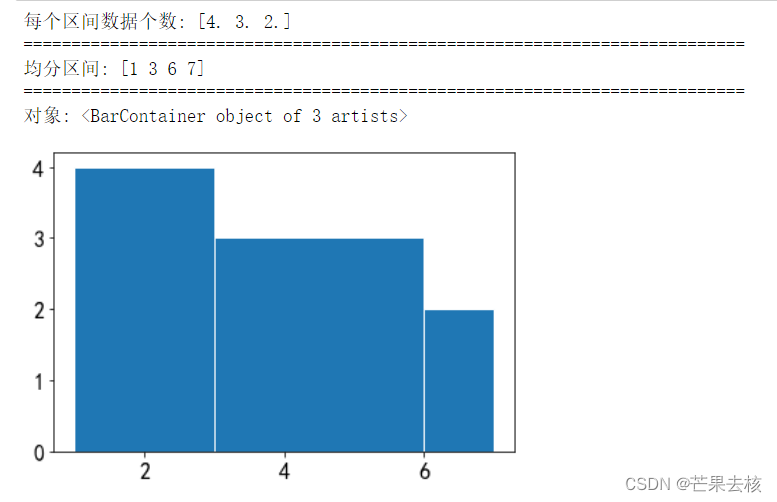
bins为序列时:
注意:如果x中的数不在指定的序列中,则是无效的。例如下面bins指定的区间最大值为7,则x列表中的8和9是无效数据。
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=[1,3,6,7],edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
2. range
range为元组或None,默认为None。bins是整数时,若range为元组则指定bins的下限和上限范围,忽略上下异常值,若range为None,则指定范围为(x.min(), x.max())。如果bins是一个序列(已指定范围了),那么range的设置不起作用。
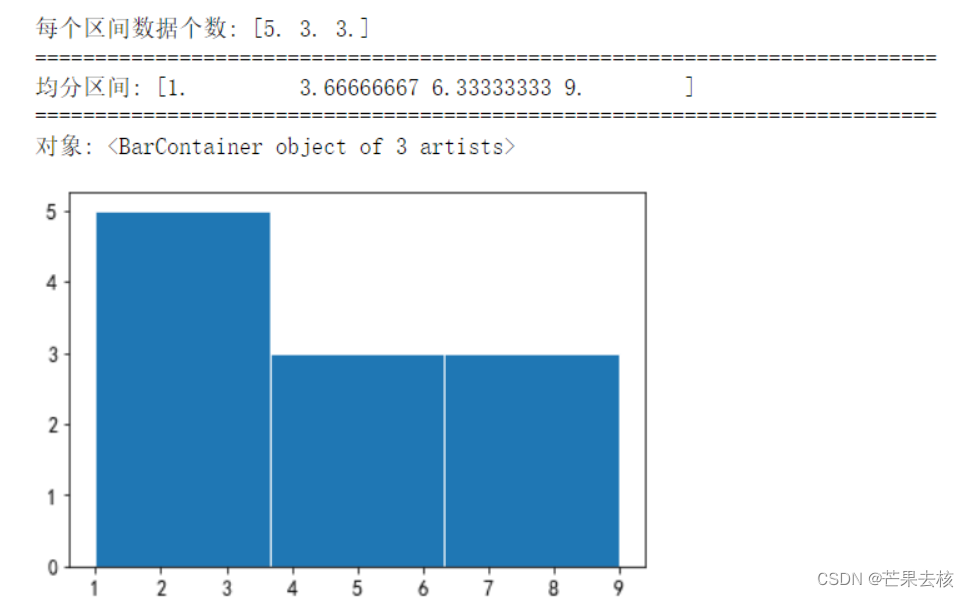
bins为整数,且range为None,均分区间bins的范围为 (x.min(), x.max())
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=3,range=None,edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
x最小值为1,最大值的9.
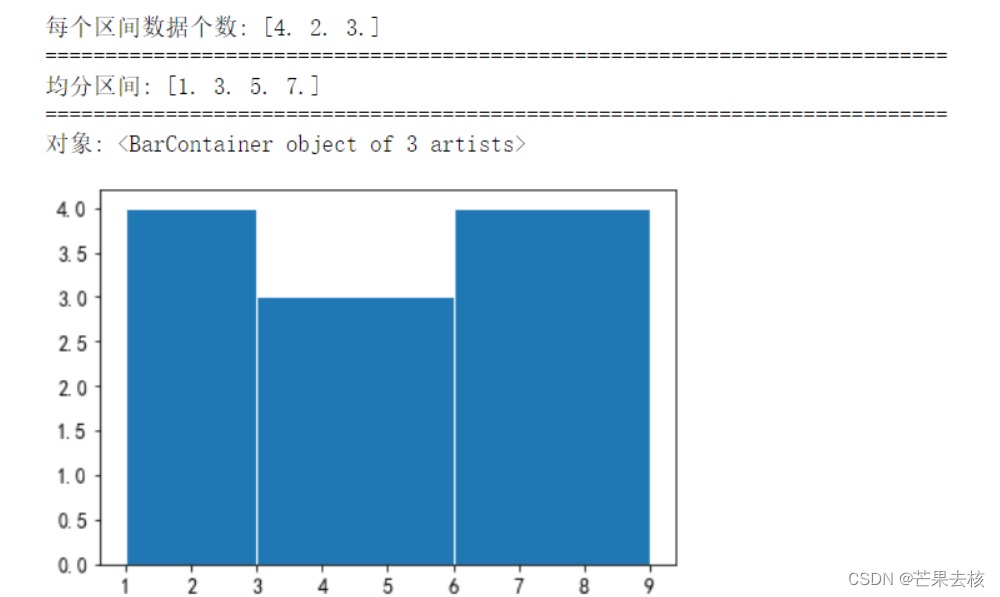
bins为整数,且range为序列,则均分区间bins的范围为range指定的序列,如下:
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=3,range=(1,7),edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象

bins为序列,已经指定了范围,range指定的范围不起作用。
x = [1,4,2,6,3,7,2,8,5,2,9]
plt.hist(x,bins=[1,3,6,9],range=(1,7),edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
3. density
density 默认是False,如果等于True,那么将会使用频率分布直方图。每个条形表示的不是个数,而是频率/组距(落在各组样本数据的个数称为频数,频数/样本总个数*区间=频率),整个直方图面积为1。
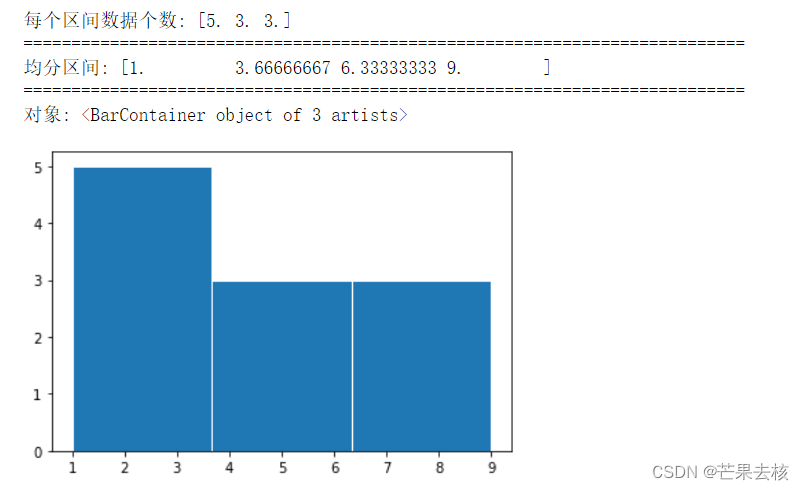
density=False
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=3,range=(1,9),density=False,edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
density=True
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=3,range=(1,9),density=True,edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
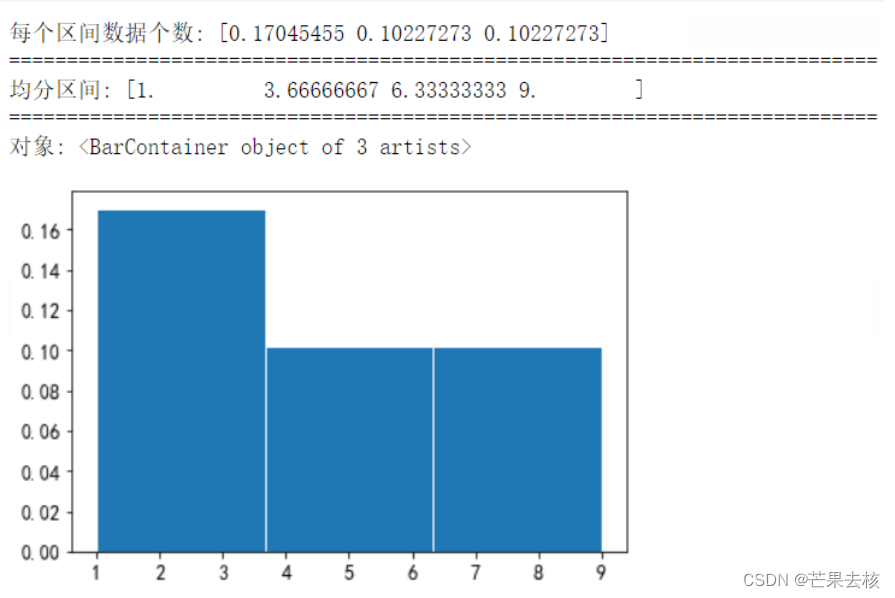
可以算出整个条形图面积为1。
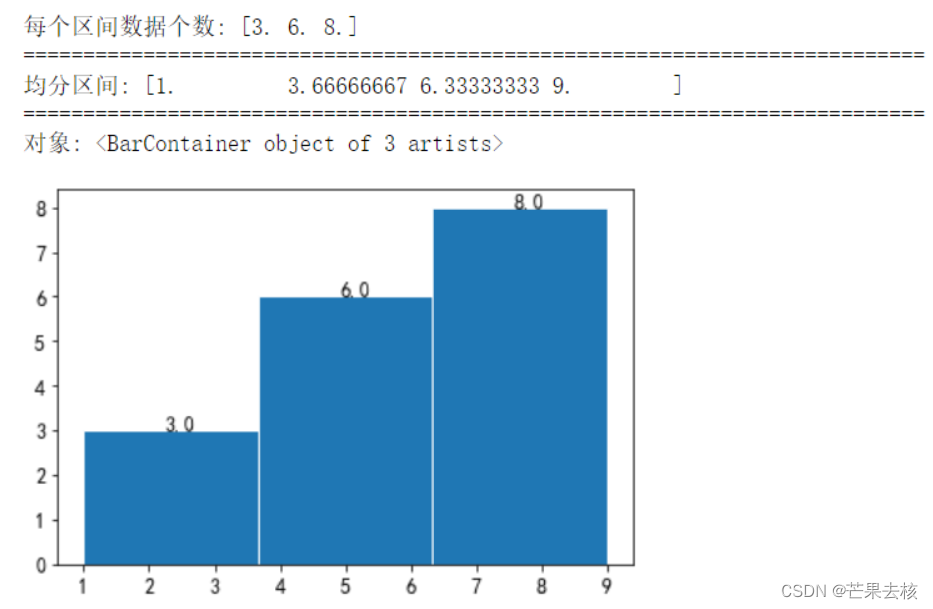
4. weights
weights是与x形状相同的权重数组。x中的每个值仅将其相关权重贡献给bins计数(而不是 1)。如果密度为True,则权重被归一化,因此密度在该范围内的积分保持为 1。
counts列表中的元素对应的是x列表中元素的权重,若权重为2则相当于两个数
x = [1,2,3,4,5,6,7,8,9]
counts = [1,1,1,2,2,2,3,3,2]
num,bins,patches = plt.hist(x,bins=3,range=(1,9),density=False,weights=counts,edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
#设置注释文本plt.annotate
for num,bin in zip(num,bins):
plt.annotate(num,xy=(bin,num),xytext=(bin+1.25,num))
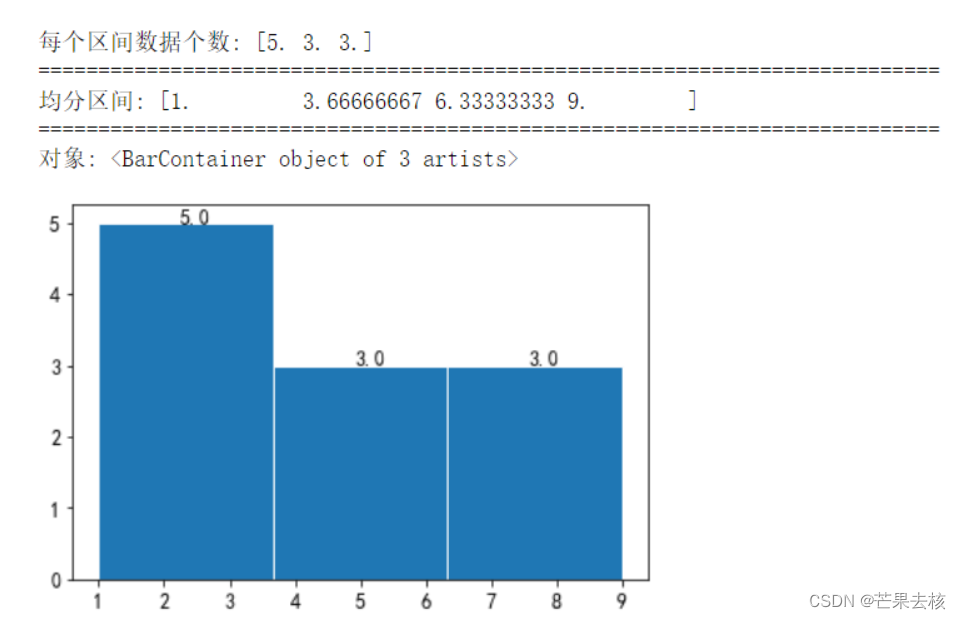
5. cumulative
cumulative 为bool或-1,默认为False。 如果为True,则计算直方图,其中每个箱子给出该箱子中的计数加上较小值的所有箱子。最后一个箱子给出了数据点的总数。如果density也为真,则对直方图进行归一化,使最后一个箱子等于1。如果累积数小于0(例如,-1),则累积方向相反。在这种情况下,如果density也为真,则对直方图进行归一化,使第一个箱子等于1。
cumulative=False:不累加
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=3,range=(1,9),density=False,cumulative=False,edgecolor='w')
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
#设置注释文本plt.annotate
for num,bin in zip(num,bins):
plt.annotate(num,xy=(bin,num),xytext=(bin+1.25,num))
cumulative=True:数值累加
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=3,range=(1,9),density=False,cumulative=True,edgecolor='w') # cumulative=True 累积
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
#设置注释文本plt.annotate
for num,bin in zip(num,bins):
plt.annotate(num,xy=(bin,num),xytext=(bin+1.25,num))
density=True,cumulative=True:频率累加
x = [1,4,2,6,3,7,2,8,5,2,9]
num,bins,patches = plt.hist(x,bins=3,range=(1,9),density=True,cumulative=True,edgecolor='w') # 累积后归一化
print("每个区间数据个数:",num) #每个区间内值出现的个数
print("="*75)
print("均分区间:",bins)
print("="*75)
print("对象:",patches) # 每根条(直方图条)的对象
#设置注释文本plt.annotate
for num,bin in zip(num,bins):
plt.annotate(num,xy=(bin,num),xytext=(bin+1.25 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









