






RDD (Resilient Distributed Dataset,弹性分布式数据集:
- 装饰者模式
- 最小的计算单元
- 弹性
- 内存和磁盘的切换
- 数据丢失可自动恢复
- 根据需要重新分区分片
- 分布式
- RDD封装了计算逻辑,计算逻辑不可变,不保存数据
- RDD抽象类,需要子类实现
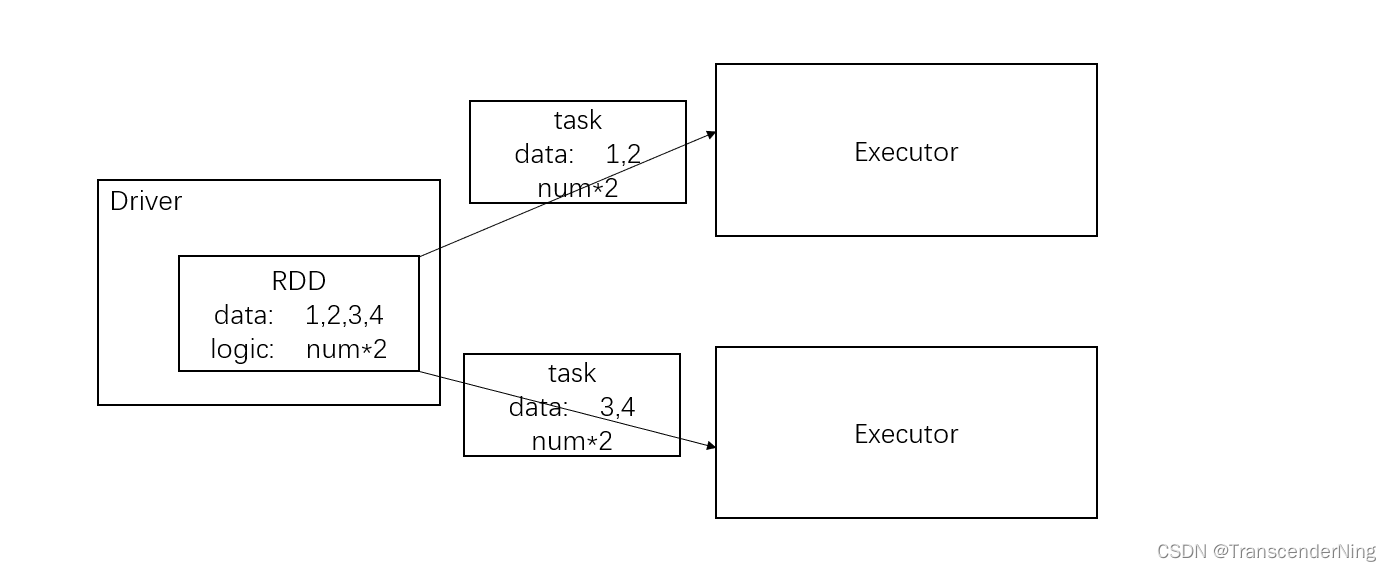
RDD核心属性
- 分区列表:执行并行计算
- 分区计算函数:分区为单位,数据不同,计算逻辑相同
- RDD之间依赖关系:多个RDD之间封装
- 分区器:分区数量
- 首选位置:判断计算发送到哪一个节点性能最优
创建RDD
- 从内存(集合)中创建
//准备环境
val sparkConfi = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//将内存中集合的数据作为处理的数据源
val seq = Seq[Int](1,2,3,4)
//parallelize 并行
sc.parallelize(seq)
//sc.makeRDD(seq)
rdd.collect().foreach(println)
//关闭环境
sc.stop()
从文件中创建RDD
//准备环境
val sparkConfi = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//将文件中的数据作为处理的数据源 以行为单位读取
val rdd: RDD[String] = sc.textFile("path")
// val rdd = sc.wholeTextFile("path") 以文件为单位读取
rdd.collect().foreach(println)
rdd.collect().foreach(println)
//关闭环境
sc.stop()















 3551
3551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









