







1. MySQL_简介
- MySQL是一个关系型数据库管理系统,由瑞典MySQL AB(创始人Michael Widenius)公司开发,2008被Sun收购(10亿美金),2009年Sun被Oracle收购。MariaDB
- MariaDB基于事务的Maria存储引擎,替换了MySQL的MyISAM存储引擎; 它使用了Percona的 XtraDB代替了InnoDB存储引擎。
- MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL是开源的,所以你不需要支付额外的费用。
- MySQL是可以定制的,采用了GPL(GNU General Public License)协议,你可以修改源码来开发自己的MySQL系统。
- MySQL支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。
- MySQL使用标准的SQL数据语言形式。
- MySQL可以允许于多个系统上,并且支持多种语言。这些编程语言包括C、C++、C#、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
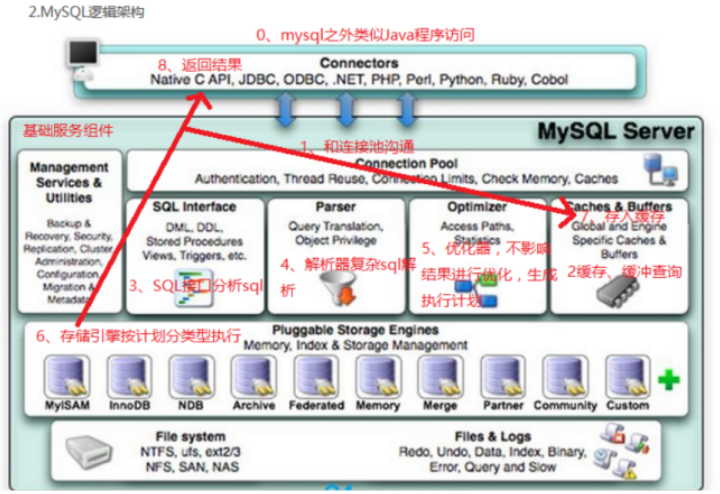
2. MySQL架构_逻辑架构
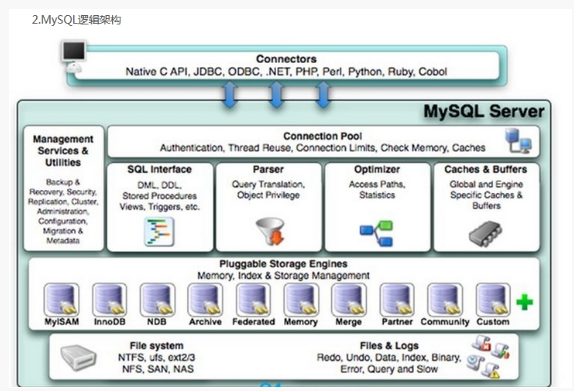
(1)连接层
最上层是一些客户端和连接服务,包含本地socket通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。
主要完成一些类似于连接处理、授权认证、及相关的安全方案。
在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。
同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
(2)服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化及部分内置函数的执行。
所有跨存储引擎的功能也在这一层实现,如过程、函数等。
在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化:如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。
如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
2.1 Management Serveices & Utilities: 系统管理和控制工具
2.2 SQL Interface: SQL接口
· 接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
2.3 Parser: 解析器
· SQL命令传递到解析器的时候会被解析器验证和解析。
2.4 Optimizer: 查询优化器。
· SQL语句在查询之前会使用查询优化器对查询进行优化。
2.5 Cache和Buffer: 查询缓存。
· 如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
· 这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
(3)引擎层
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。后面介绍MyISAM和InnoDB
(4)存储层
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
(5)利用show profiles 查看sql的执行周期
了解查询语句底层执行的过程:查看是否开启计划。
修改配置文件/etc/my.cnf,先开启查询缓存
新增一行:query_cache_type=1
重启mysql:systemctl restart mysqld
再开启查询执行计划
show variables like '%profiling%';
set profiling=1;
执行语句两次:select * from mydb.mytbl where id=1 ;
显示最近执行的语句
show profiles;
显示执行计划
show profile cpu,block io for query 6;
执行编号7时,比执行编号6时少了很多信息,从下面截图中可以看出查询语句直接从缓存中获取数据;
注意:SQL必须是一致的,否则,不能命中缓存。
如果对数据库表进行 insert ,update ,delete 这个时候,缓存会失效!
如:select * from mydb.mytbl where id=2 和 select * from mydb.mytbl where id>1 and id<3 虽然查询结果一致,但并没有命中缓存。
(6) 查询说明
mysql的查询流程大致是
- 首先,mysql客户端通过协议与mysql服务器建连接,发送查询语句,先检查查询缓存,如果命中,直接返回结果,否则进行语句解析,也就是说,在解析查询之前,服务器会先访问查询缓存(query cache)——它存储SELECT语句以及相应的查询结果集
- 如果某个查询结果已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可,这将大大提高系统的性能。
- 语法解析器和预处理:首先mysql通过关键字将SQL语句进行解析,并生成一颗对应的“解析树”
mysql解析器将使用mysql语法规则验证和解析查询 - 预处理器则根据一些mysql规则进一步检查解析树是否合法。
- 查询优化器当解析树被认为是合法的了,并且由优化器将其转化成执行计划
- 一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
然后,mysql默认使用的B+TREE索引,并且一个大致方向是:无论怎么折腾sql,至少在目前来说,mysql只少用到表中的一个索引。
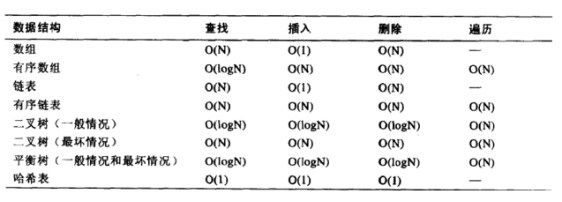
3.数据结构
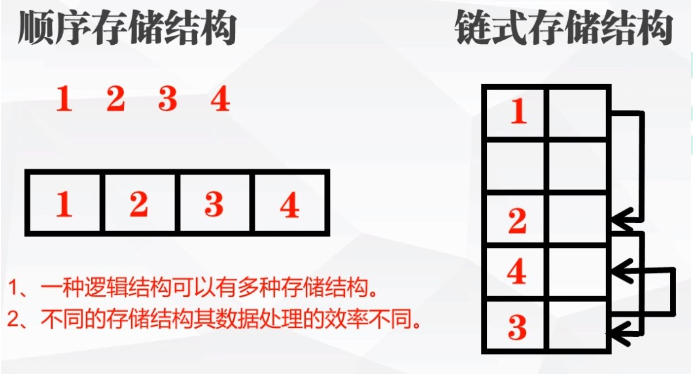
(1)数据结构分类
数据结构有很多种,一般来说,按照数据的逻辑结构对其进行简单的分类,包括线性结构和非线性结构两类。
线性结构:
•线性结构作为最常用的数据结构,其特点是数据元素之间存在一对一的线性关系。
•线性结构有两种不同的存储结构,即顺序存储结构和链式存储结构。
◦顺序存储的线性表称为顺序表,顺序表中的存储元素是连续的
◦链式存储的线性表称为链表,链表中的存储元素不一定是连续的,元素节点中存放数据元素以及相邻元素的地址信息
•线性结构常见的有:数组、链表、队列和栈。
非线性结构:
非线性结构包括:二维数组,多维数组,树结构,图结构
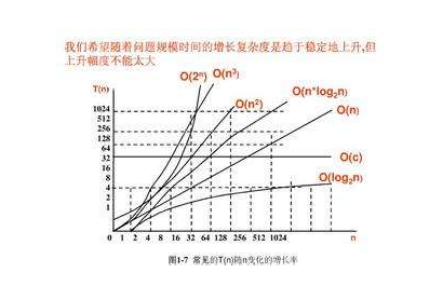
常见的算法时间复杂度由小到大依次为:O—理解为一个函数
Ο(1)<Ο(log2N)<Ο(n)<Ο(nlog2N)<Ο(n^2)<Ο(n^3)< Ο(n^k) <Ο(2^n)
MySQL的InnoDB引擎的存储方式也是B+树机制。
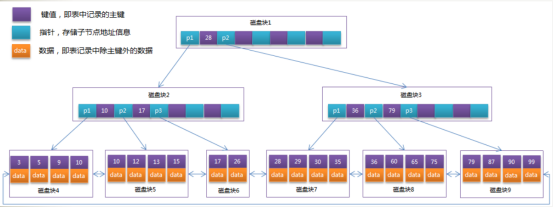
4. MySQL架构_存储引擎简介
查看mysql提供什么存储引擎:show engines;
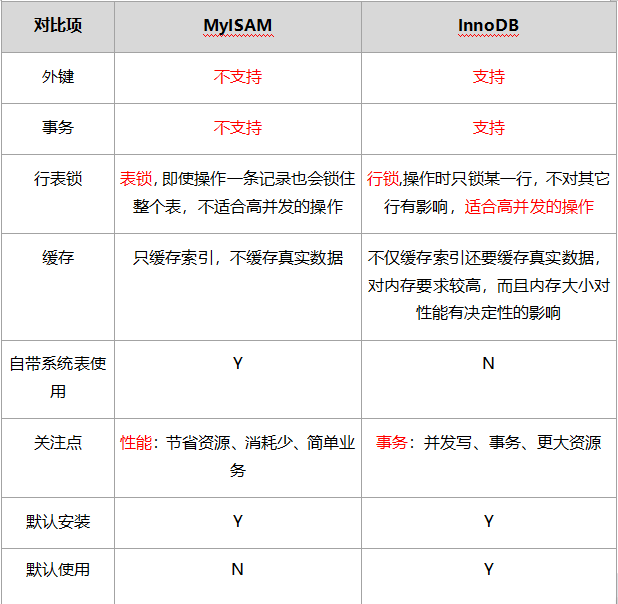
(1)MyISAM和InnoDB 面试题
(2)我们手写sql的顺序
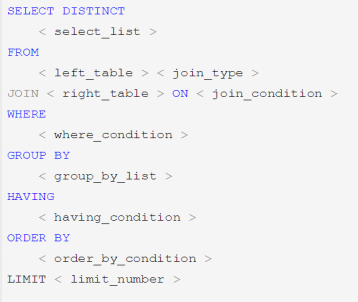
(3)机器读取顺序

FOJWGHSDOL(佛叫我干活速度上线(OL)):大型范围过滤,越靠前越好
5. 索引优化分析_预热_慢
(1).性能下降SQL慢 执行时间长 等待时间长
- 数据过多——分库分表 mycat
- 索引失效,没有充分利用到索引——索引建立
- 关联查询太多join(设计缺陷或不得已的需求)——SQL优化
- 服务器调优及各个参数设置(缓冲、线程数等)——调整my.cnf
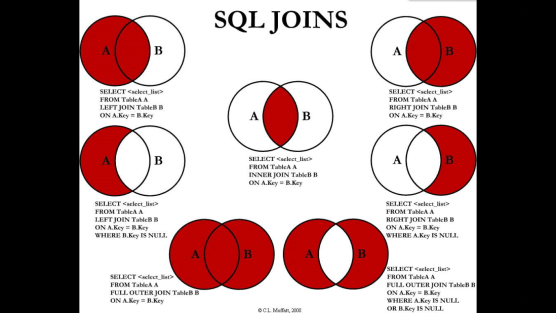
6. MySQL7种JOIN
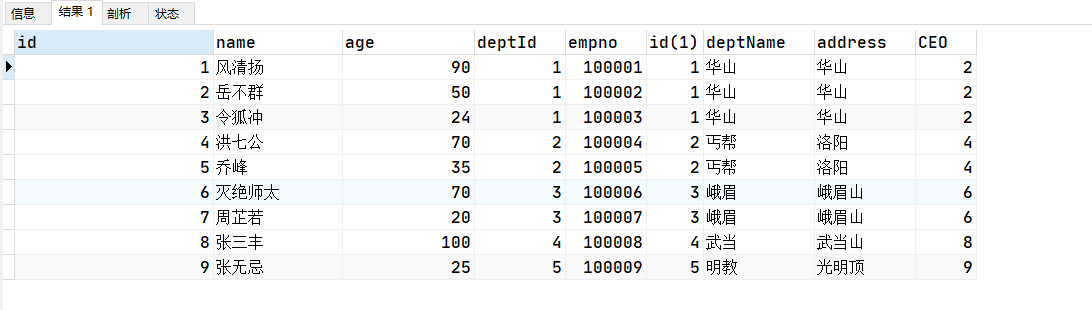
# t_emp表(以下称为A表)
CREATE TABLE `t_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
`empno` INT(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_dept_id` (`deptId`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
# t_dept表(一下称为B表)
CREATE TABLE `t_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
# 插入数据
INSERT INTO t_dept(id,deptName,address) VALUES(1,'华山','华山');
INSERT INTO t_dept(id,deptName,address) VALUES(2,'丐帮','洛阳');
INSERT INTO t_dept(id,deptName,address) VALUES(3,'峨眉','峨眉山');
INSERT INTO t_dept(id,deptName,address) VALUES(4,'武当','武当山');
INSERT INTO t_dept(id,deptName,address) VALUES(5,'明教','光明顶');
INSERT INTO t_dept(id,deptName,address) VALUES(6,'少林','少林寺');
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(1,'风清扬',90,1,100001);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(2,'岳不群',50,1,100002);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(3,'令狐冲',24,1,100003);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(4,'洪七公',70,2,100004);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(5,'乔峰',35,2,100005);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(6,'灭绝师太',70,3,100006);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(7,'周芷若',20,3,100007);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(8,'张三丰',100,4,100008);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(9,'张无忌',25,5,100009);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(10,'韦小宝',18,NULL,100010);
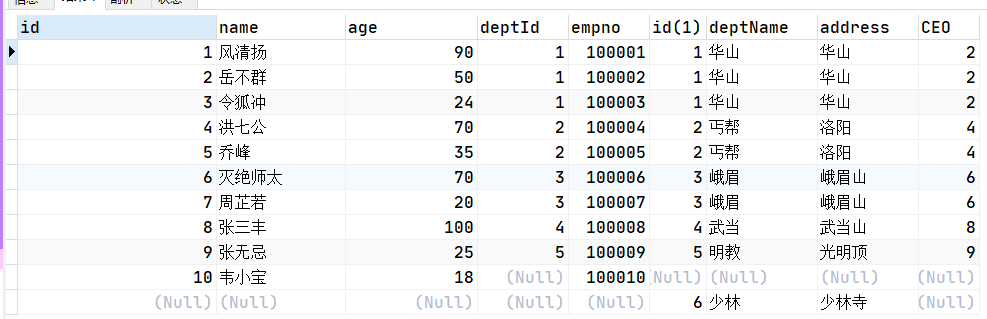
(1) A、B两表共有(查询所有有部门的员工->员工和部门之间必须存在关联的数据)
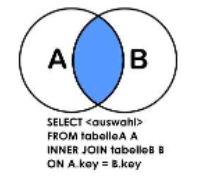
SELECT a.*,b.* FROM t_emp a INNER JOIN t_dept b ON a.deptId = b.id;
(2) A、B两表共有+A的独有(列出所有用户,并显示其机构信息)A的全集
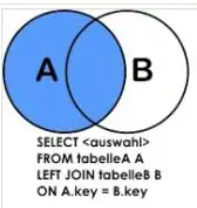
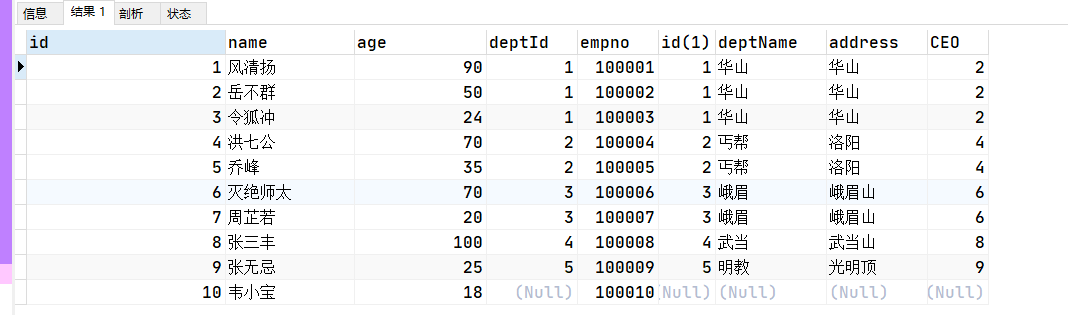
SELECT a.*,b.* FROM t_emp a LEFT JOIN t_dept b ON a.deptId = b.id;
(3) A、B两表共有+B的独有(列出所有部门,并显示其部门的员工信息 )B的全集
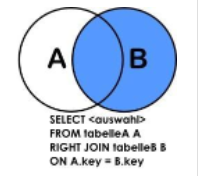
SELECT a.*,b.* FROM t_emp a RIGHT JOIN t_dept b ON a.deptId = b.id;
# 或者下面写法
SELECT a.*,b.* FROM t_dept b LEFT JOIN t_emp a ON b.id=a.deptId;
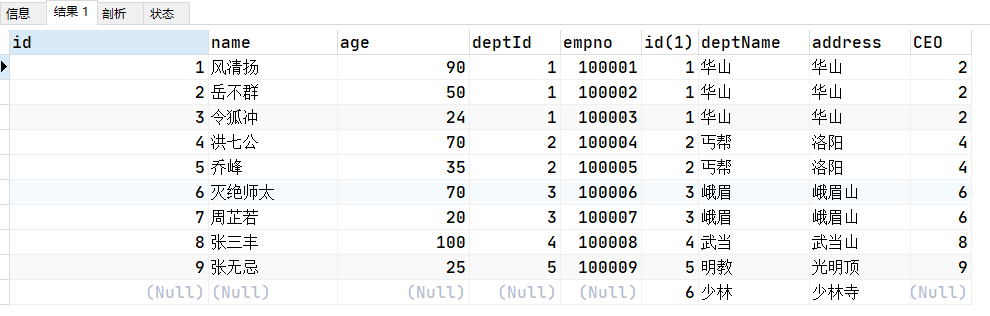
(4) A的独有 (查询没有加入任何部门的员工)
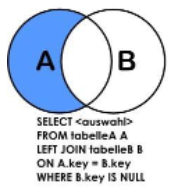
SELECT a.*,b.* FROM t_emp a LEFT JOIN t_dept b ON a.deptId=b.id WHERE b.id is null

(5) B的独有(查询没有任何员工的部门)
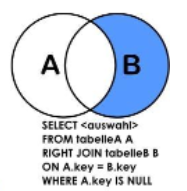
SELECT a.*,b.* FROM t_emp a RIGHT JOIN t_dept b ON a.deptId=b.id WHERE a.deptId is null

(6) AB全有(查询所有员工和所有部门),MySQL不支持全外连接,所以我们只能使用union(去重排序拼接,效率较低)|union all(无脑拼接,效率高) 进行SQL拼接了;(UNION在使用时,两张表的字段保证一致,如果不一致,请在slect后面列选字段,不要使用*)
注意:使用
union或者union all时,两张拼接的结果集必须要结构一模一样
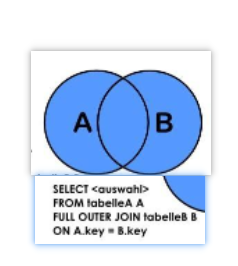
SELECT a.*,b.* FROM t_emp a LEFT JOIN t_dept b ON a.deptId = b.id
UNION
SELECT a.*,b.* FROM t_emp a RIGHT JOIN t_dept b ON a.deptId = b.id;
SELECT a.*,b.* FROM t_emp a LEFT JOIN t_dept b ON a.deptId = b.id
UNION ALL
SELECT a.*,b.* FROM t_emp a RIGHT JOIN t_dept b ON a.deptId = b.id;
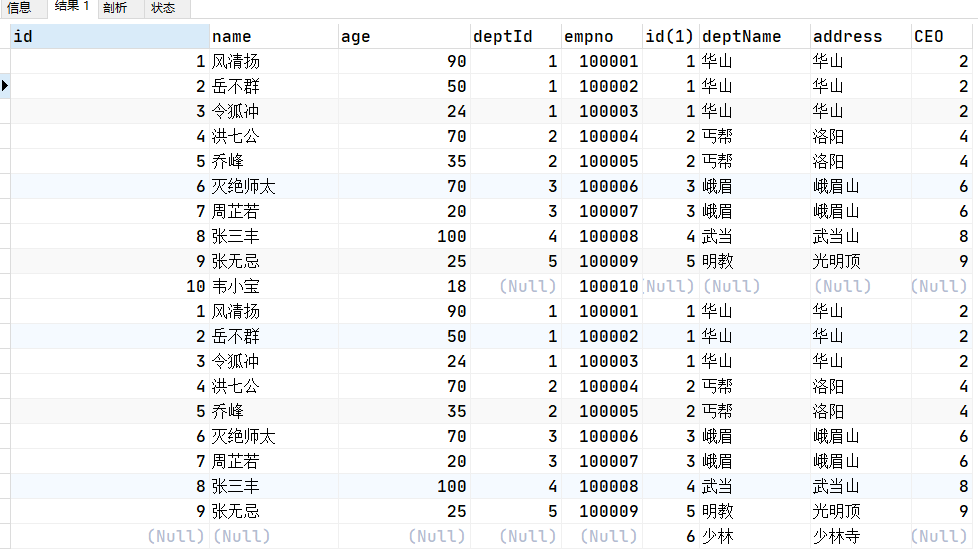
注意上图的
union和union all的区别(面试题喔~)
(7) A的独有+B的独有(查询没有加入任何部门的员工,以及查询出部门下没有任何员工的部门)
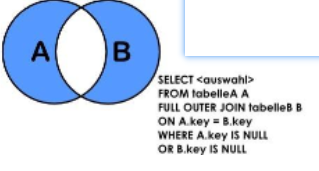
# A的独有 (查询没有加入任何部门的员工)
SELECT a.*,b.* FROM t_emp a LEFT JOIN t_dept b ON a.deptId=b.id WHERE b.id is null
union
# B的独有(查询没有任何员工的部门)
SELECT a.*,b.* FROM t_emp a RIGHT JOIN t_dept b ON a.deptId=b.id WHERE a.deptId is null

7. 索引优化分析
(1)是什么?
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
索引的本质:索引是数据结构。可以简单理解为“排好序的快速查找数据结构”。
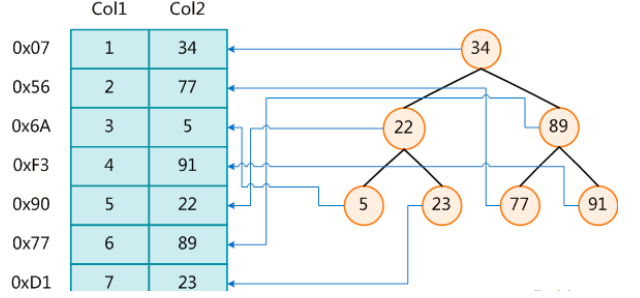
MySQL索引
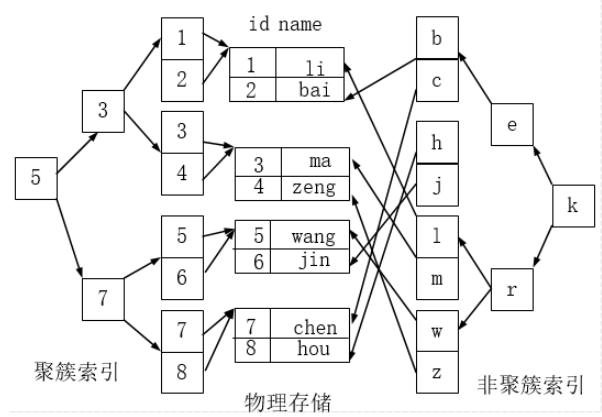
主键索引号就是聚簇索引,非主键索引就是非聚簇索引
- 聚簇索引的好处:
- 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据块中提取数据,所以节省了大量的io操作。
- 聚簇索引的限制:
- 对于MySQL数据库目前只有innodb数据引擎支持聚簇索引,而Myisam并不支持聚簇索引。
- 由于数据物理存储排序方式只能有一种,所以每个MySQL的表只能有一个聚簇索引。一般情况下就是该表的主键。
为了充分利用聚簇索引的聚簇的特性,所以innodb表的主键列尽量选用有序的顺序id,而不建议用无序的id,比如uuid这种。
(2)能干嘛?
- MySQL索引分类
- 单值索引:即一个索引只包含单个列,一个表可以有多个单列索引
- 唯一索引:索引列的值必须唯一,但允许有空值
- 主键索引:设定为主键后数据库会自动建立索引,innodb为聚簇索引
- 复合索引:即一个索引包含多个列
(3)怎么玩?
索引的基本语法
-
1.创建
- CREATE [UNIQUE ] INDEX indexName ON mytable(column name(length));
- length : 默认可以不用写
- 如果是CHAR,VARCHAR类型,length可以小于字段实际长度; 如果是BLOB和TEXT类型,必须指定length。
- ALTER mytable ADD [UNIQUE ] INDEX [indexName] ON (columnname(length));
在创建表的时候给字段增加索引
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE|FULLTEXT|SPATIAL] INDEX|KEY [索引名] (字段名[(长度)] [ASC |DESC])
); -
2.删除
- DROP INDEX [indexName] ON mytable;
-
3.查看
- SHOW INDEX FROM table_name
-
4.使用ALTER命令
- 有四种方式来添加数据表的索引:
- ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
- ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次) 。
- ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
- ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引
- 有四种方式来添加数据表的索引:
哪些情况需要创建索引
- 1)主键自动建立唯一索引
- 2)频繁作为查询条件的字段应该创建索引
- 3)查询中与其它表关联的字段,外键关系建立索引
- 4)单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
- 5)查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 6)查询中统计或者分组字段
思考:排序和分组哪个更伤性能? 1000以上建索引。
分组 = 排序 + 去重 ,也就是说,真正的分组其实就是先将数据排序,然后再看根据distinct进行去重. 所以分组比排序更消耗性能
哪些情况不要创建索引
- 1)表记录太少
300万数据时MySQL性能就开始下降了,这时就可以开始开始优化了 - 2)经常增删改的表
提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件 - 3)where条件里用不到的字段不创建索引
where 后面带的字段,一定考虑建索引:
t_order:对比业务思考,订单业务大量的where都是使用orderNum,为他建索引,偶尔的业务使用username,username不用建
大数据量表某(多)个字段经常被用来当做查询条件,就一定要建立索引
8.索引优化分析_explain查看执行计划
Explain
是什么?
- 一句话:查看执行计划
- 使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是 如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
- 官网介绍 https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
能干嘛?
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
怎么玩?
EXPLAIN SELECT * FROM t_emp;
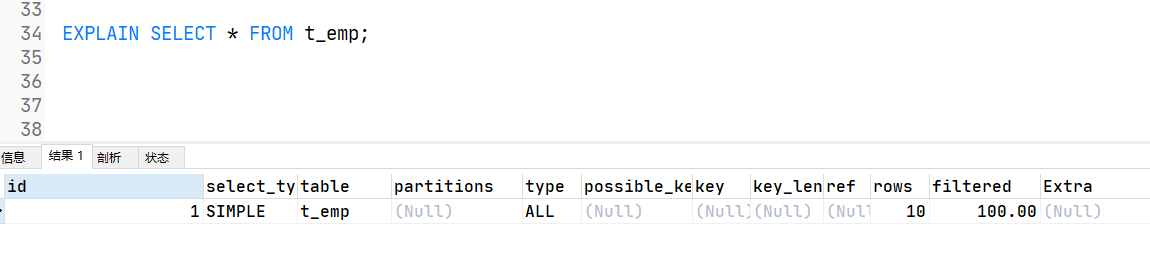
索引优化分析_explain_各字段解释
id★
-
1.select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
-
2.三种情况
-
1)id相同,执行顺序由上至下
Explain select * from t1,t2,t3; -
2)id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
explain select t1.id from t1 where t1.id = (select t2.id from t2 where t2.id = (select t3.id from t3 where t3.content=‘t3_897’));
-
-
id相同,不同,同时存在;
-
id如果相同,可以认为是一组,从上往下顺序执行;
-
在所有组中,id值越大,优先级越高,越先执行;
-
关注点:id号每个号码,表示一趟独立的查询。一个sql的查询趟数越少越好。
select_type
-
1.有哪些
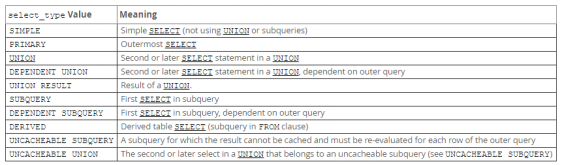
-
2.查询的类型,主要是用于区别 普通查询、联合查询、子查询等的复杂查询
-
1)SIMPLE
简单的 select 查询,查询中不包含子查询或者UNION
EXPLAIN SELECT * FROM t1; -
2)PRIMARY
查询中若包含任何复杂的子部分,最外层查询则被标记为primary
EXPLAIN select t1.id from t1 where t1.id = (select t2.id from t2 where t2.id = (select t3.id from t3 where t3.content=‘t3_897’)); -
3)SUBQUERY
在SELECT或WHERE列表中包含了子查询 -
4)DEPENDENT SUBQUERY
在SELECT或WHERE列表中包含了子查询,子查询基于外层
EXPLAIN SELECT * FROM t3 WHERE id = ( SELECT id FROM t2 WHERE content = t3.content); -
5)UNCACHEABLE SUBQUREY
表示这个subquery的查询要受到外部系统变量的影响
EXPLAIN SELECT * FROM t3 WHERE id = ( SELECT id FROM t2 WHERE content = @@character_set_server); -
6)UNION
若第二个SELECT出现在UNION之后,则被标记为UNION; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED
EXPLAIN SELECT * FROM (SELECT * FROM t1 UNION SELECT * FROM t2) aa; -
7)UNION RESULT
从UNION表获取结果的SELECT
-
table
显示这一行的数据是关于哪张表的
partitions
代表分区表中的命中情况,非分区表,该项为null
https://dev.mysql.com/doc/refman/5.7/en/alter-table-partition-operations.html
type★
- 1.访问类型排列
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。 - 2.类型介绍
1.system
表仅有一行记录,必须是系统表,这是const类型的特例,查询起来非常迅速。
explain SELECT * from mysql.proxies_priv WHERE User=‘root’;
2.const
explain select * from t1 where id = 1;
表示通过索引一次就找到了,const用于primary key或者unique索引。
因为只匹配一行数据,所以很快 如将主键置于where列表中,MySQL就能将该查询转换为一个常量
3.eq_ref
explain select * from t1,t2 where t1.id = t2.id;
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见主键或唯一索引扫描
4.ref *
create index idx_content on t1(content);
EXPLAIN SELECT * FROM t1, t2 WHERE t1.content = t2.content;
非唯一性索引扫描,返回匹配某个单独值的所有行. 本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而, 它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体
5.range *
explain select * from t2 where id >1 and id <5;
- 只检索给定范围的行,使用一个索引来选择行。
- key 列显示使用了哪个索引 一般就是在你的where语句中出现了between、<、>、in等的查询 这种范围索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。
6.Index
explain select id from t1;
- 出现index是sql使用了索引但是没用通过索引进行过滤,一般是使用了覆盖索引或者是利用索引进行了排序分组 Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。也就是说虽然all和Index都是读全表,但index是从索引中读取的,而all是从硬盘中读的
7.all
explain select * from t2;
Full Table Scan,将遍历全表以找到匹配的行
possible_keys
显示可能应用在这张表中的索引,一个或多个。 查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用
key
实际使用的索引。如果为NULL,则没有使用索引
key_len ★
okey_len表示索引使用的字节数,根据这个值可以判断索引的使用情况,特别是在组合索引的时候,判断该索引有多少部分被使用到非常重要。值越大越好。不损失精度情况下key_len越小 索引效果越好
EXPLAIN SELECT SQL_NO_CACHE * FROM t_emp WHERE t_emp.age=30 AND t_emp.name LIKE ‘ab%’;
create index idx_age_name on t_emp (age,name);
如何计算
- 第一组
key_len=age的字节长度+name的字节长度=(4+1) + ( 20*3+2+1) = 5+63 = 68 - 第二组
key_len=age的字节长度=4+1=5
key_len的长度计算公式:
varchr(10)变长字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchr(10)变长字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(10)固定字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)
ref
显示将哪些列或常量与键列中命名的索引进行比较,以从表中选择行。
explain select * from t1,t2 where t1.id = t2.id;
rows★
rows列显示MySQL认为它执行查询时必须检查的行数。值越小越好
filtered
这个字段表示存储引擎返回的数据在mysql server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数
Extra★
包含不适合在其他列中显示,但十分重要的额外信息
1.Using filesort *
出现filesort的情况:order by 没有用上索引。
优化后(给deptno和ename字段建立复合索引),去掉filesort
create index idx_deptno_ename on emp (deptno,ename);
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。 MySQL中无法利用索引完成的排序操作称为“文件排序”
2.Using temporary *
出现Using temporary情况:分组没有用上索引。产生临时表。注意:分组操作是需要先排序后分组的。所以,也会出现Using filesort。
优化前存在 using temporary 和 using filesort
优化后(给deptno和ename建立复合索引)去掉using temporary 和 using filesort,性能发生明显变化:
create index idx_deptno_ename on emp (deptno,ename);
使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by 和分组查询group by。
3.Using index *
表示使用了覆盖索引 [content是一个索引]
如果同时出现using where,表明索引被用来执行索引键值的查找;
如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。
4.Using where
o表明使用了where过滤!
5.using join buffer *
如果有它则表明关联字段没有使用索引!
使用了连接缓存
6.impossible where
where 后面筛选条件有错误!
9.查询优化建议口诀:
| 口 | 诀 |
|---|---|
| 全值匹配我最爱 | 最左前缀要遵守 |
| 带头大哥不能死 | 中间兄弟不能断 |
| 索引列上少计算 | 范围之后全失效 |
| LIKE百分写最右 | 覆盖索引不写* |
| 不等空值还有OR | 索引影响要注意 |
| VAR引号不可丢 | SQL优化有诀窍 |
单表查询一般性建议
- 对于单键索引,尽量选择过滤性更好的索引(例如:手机号,邮件,身份证)
- 在选择组合索引的时候,过滤性最好的字段在索引字段顺序中,位置越靠前越好。
- 选择组合索引时,尽量包含where中更多字段的索引
- 组合索引出现范围查询时,尽量把这个字段放在索引次序的最后面
- 尽量避免造成索引失效的情况
连表查询一般性建议
- 保证被驱动表的join字段被索引
- left join 时,选择小表作为驱动表,大表作为被驱动表
- 1.驱动表用小表
- inner join 时,mysql会自动将小结果集的表选为驱动表。选择相信mysql优化策略。
- 能够直接多表关联的尽量直接关联,不用子查询
- 总结: 驱动表选小表,索引建在被驱动
查询优化_子查询优化一般性建议
- NOT IN -->LEFT JOIN xxx ON xx WHERE xx IS NULL
- 尽量不要使用not in 或者 not exists
查询优化_排序、分组优化一般性建议
| 口 | 诀 |
|---|---|
| 无过滤 | 不索引 |
| 顺序错 | 必排序 |
| 方向反 | 必排序 |
| LIKE百分写最右 | 覆盖索引不写* |
| 不等空值还有OR | 索引影响要注意 |
| VAR引号不可丢 | SQL优化有诀窍 |
- 当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
GROUP BY关键字优化
- group by 先排序再分组,遵照索引建的最佳左前缀法则
- 当无法使用索引列,增大max_length_for_sort_data和sort_buffer_size参数的设置
- where高于having,能写在where限定的条件就不要写在having中了
- group by没有过滤条件,也可以用上索引。Order By 必须有过滤条件才能使用上索引。
查询优化_覆盖索引优化
- 简单说就是,select 到 from 之间查询的列使用了索引!
- select * from tName 不建议使用*
- 未使用覆盖索引之前:
- explain select sql_no_cache * from emp where name like ‘%abc’;
- 减少回表次数
- 禁止使用select *
- 禁止查询与业务无关字段
- 尽量使用覆盖索引
10.查询截取分析_慢查询日志
是什么?
- MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中
怎么玩?
- 默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。
- 当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件
查看
SHOW VARIABLES LIKE '%slow_query_log%';默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的

开启
set global slow_query_log=1; 只对窗口生效,重启服务失效
慢查询日志记录long_query_time时间
SHOW VARIABLES LIKE '%long_query_time%';
SHOW GLOBAL VARIABLES LIKE 'long_query_time';
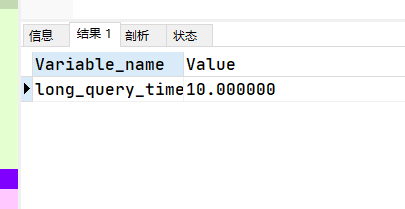
设置临时的sql慢查询时间
SET SESSION long_query_time=0.1;
创建一个数据库,给数据库添加10w行数据
# 建一张表
CREATE TABLE `dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`ceo` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
# 创建二个函数
DELIMITER $$
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END$$
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
# 编写一个存储过程
DELIMITER $$
CREATE PROCEDURE `insert_dept`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO dept ( deptname,address,ceo ) VALUES (rand_string(8),rand_string(10),rand_num(1,500000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END$$
# 调用存储过程添加数据
日志分析工具mysqldumpslow
2.查看mysqldumpslow的帮助信息
a)mysqldumpslow --help
- -a: 将数字抽象成N,字符串抽象成S
- -s: 是表示按照何种方式排序;
- c: 访问次数
- l: 锁定时间
- r: 返回记录
- t: 查询时间
- al:平均锁定时间
- ar:平均返回记录数
- at:平均查询时间
- -t: 即为返回前面多少条的数据;
- -g: 后边搭配一个正则匹配模式,大小写不敏感的;
得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/localhost-slow.log
得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/localhost-slow.log
得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/localhost-slow.log
另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/localhost-slow.log | more
11.View视图
是什么
- 将一段查询sql封装为一个虚拟的表。
- 这个虚拟表只保存了sql逻辑,不会保存任何查询结果。
作用
- 封装复杂sql语句,提高复用性
- 逻辑放在数据库上面,更新不需要发布程序,面对频繁的需求变更更灵活
适用场景
- 共用查询结果
- 报表
语法
- 创建
CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition - 使用
- 查询
select * from view_name - 更新
CREATE OR REPLACE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition - 删除
drop view view_name;
- 查询
mysql 视图会随着表中的数据变化而动态变化!
12.主从复制
复制的基本原理
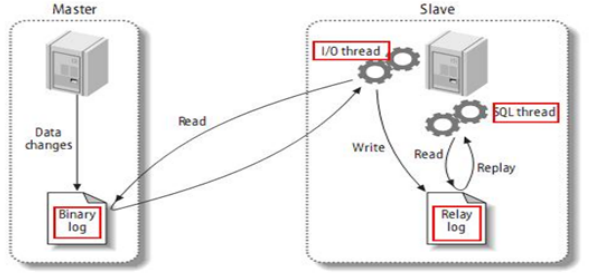
- MySQL复制三步骤:
- 1 master将写操作记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events;
- 2 slave将master的binary log events拷贝到它的中继日志(relay log);从服务器I/O线程将主服务器的二进制日志读取过来记录到从服务器本地文件,然后SQL线程会读取relay-log日志的内容并应用到从服务器,从而使从服务器和主服务器的数据保持一致!
- 3 slave重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的,而且重启后从接入点开始复制。
复制的最大问题(延时)
主从的集群搭建
1.我这里使用的是VMware虚拟机进行搭建,并且使用docker容器化技术搭建
docker pull mysql:5.7 先下载mysql镜像文件
2. 启动master和连个slave

docker run -d -p 3307:3306 \
-v /mysql01/data:/var/lib/mysql \
-v /mysql01/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql01 --restart=always --privileged=true \
mysql:5.7
docker run -d -p 3308:3306 \
-v /mysql02/data:/var/lib/mysql \
-v /mysql02/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql02 --restart=always --privileged=true \
mysql:5.7
docker run -d -p 3309:3306 \
-v /mysql03/data:/var/lib/mysql \
-v /mysql03/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql03 --restart=always --privileged=true \
mysql:5.7
3.创建三个客户端连接
4.修改主节点的配置
# 创建一个base.cnf配置文件
vim base.cnf
[client]
default-character-set=utf8
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
5.修改从节点
[mysqld]
server-id=2
relay-log=mysql-relay
6.重启三个mysql
docker restart mysql01 mysql02 mysql03
7.在master主机上给两个slave分配两个账号密码,用户连接master进行主从同步数据
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123456';
flush privileges;
#查看master状态
show master status;
8.两个从机执行命令,使用分配的账号密码进行数据同步
CHANGE MASTER TO MASTER_HOST='192.168.137.72',
MASTER_USER='slave',MASTER_PASSWORD='123456',MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=0;
START SLAVE;
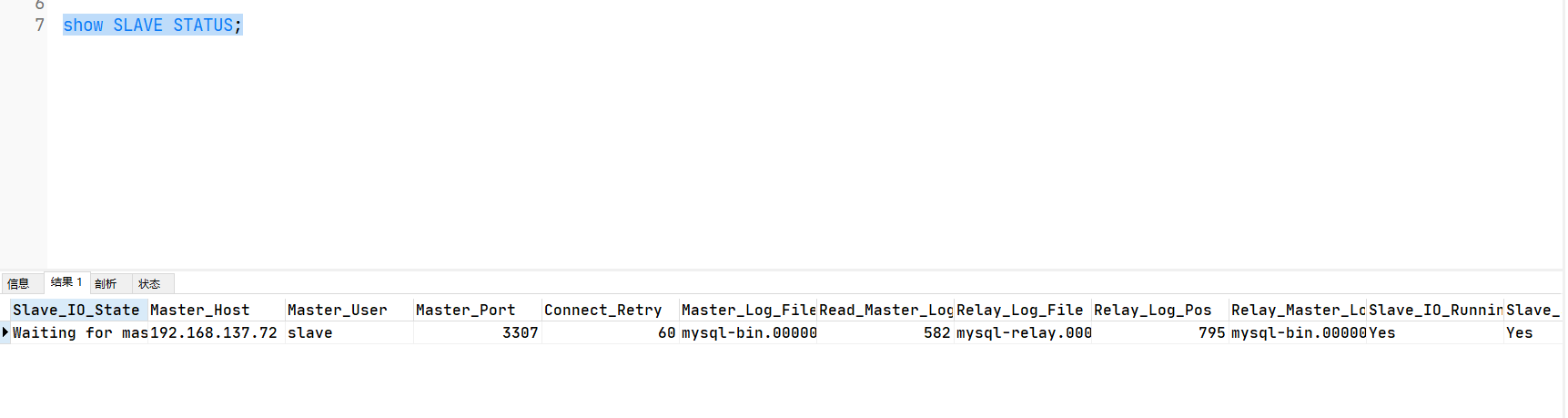
9.查看状态
show slave status;
10.测试
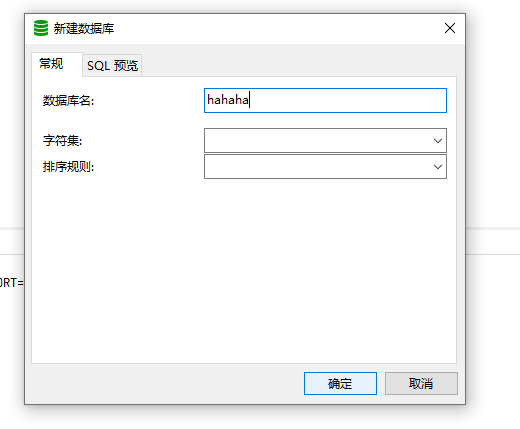
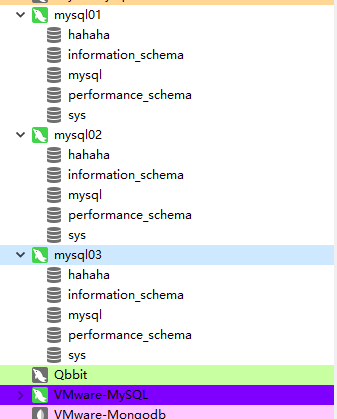
主机创建一个数据库,刷新从机会发现从机也有了
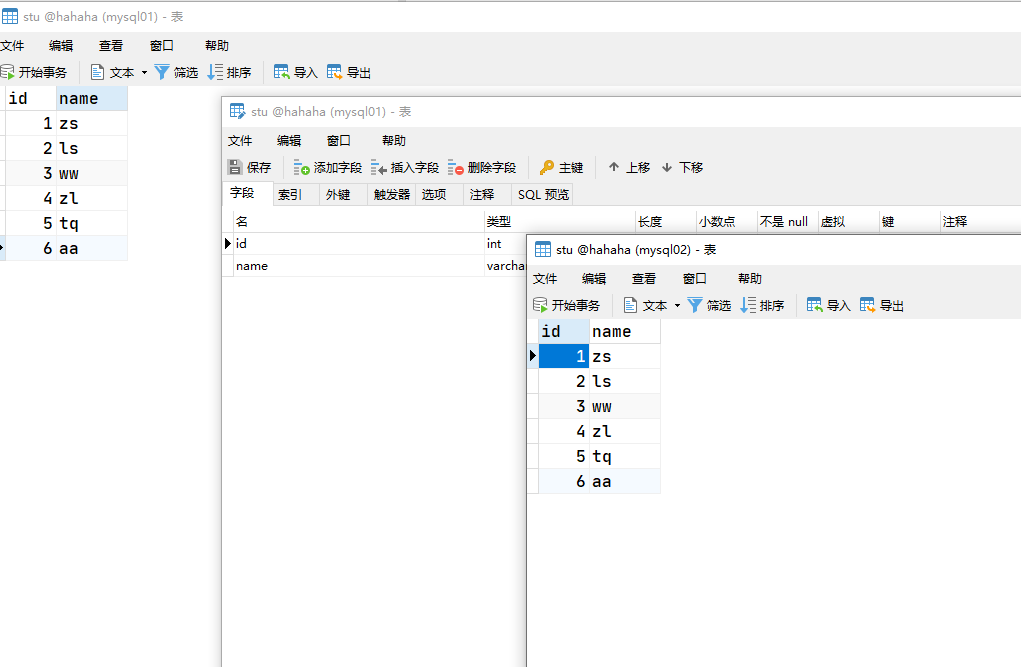
创建表,添加记录,会发现从机也会立马同步过去的















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









