







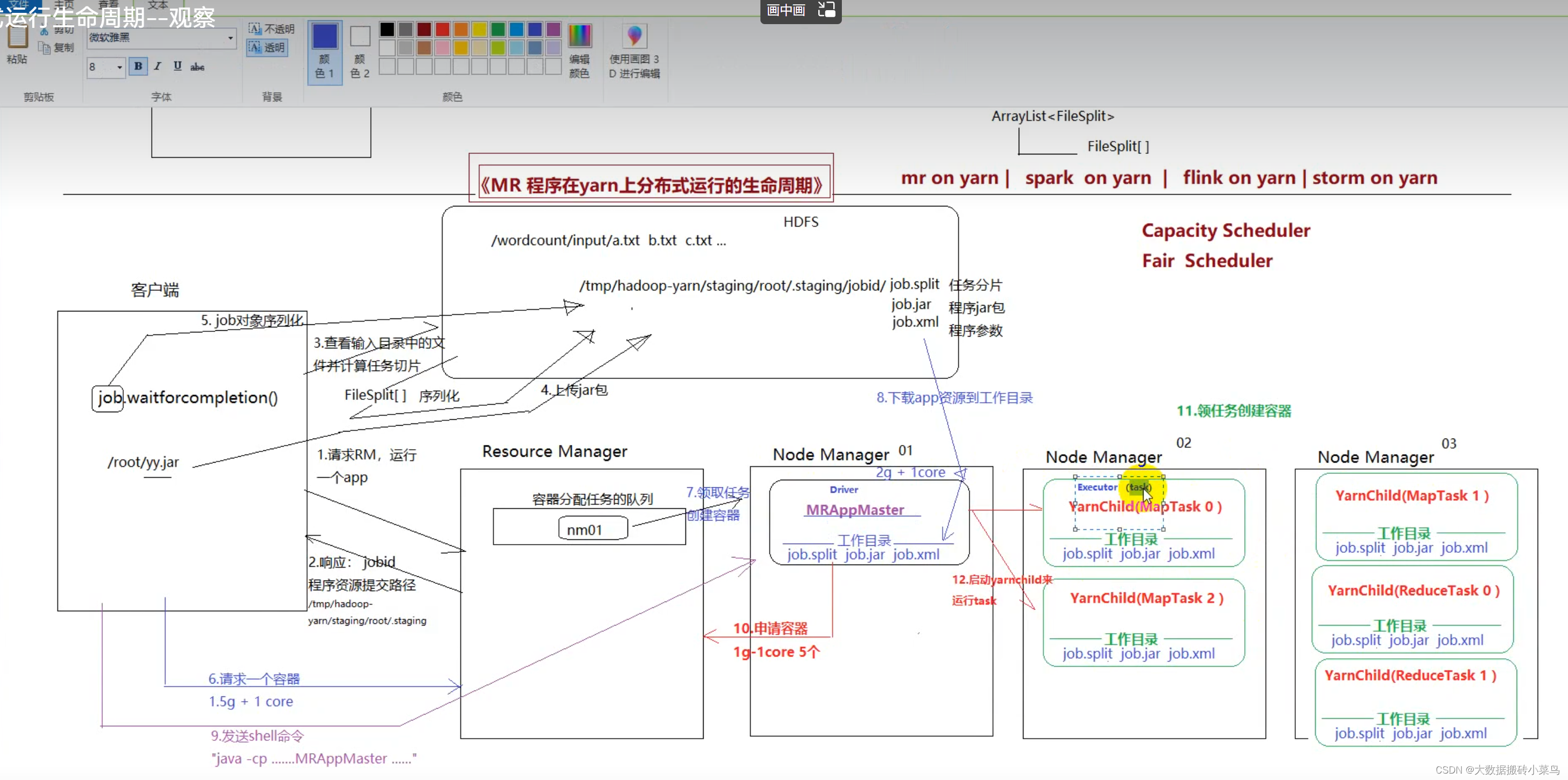
MapRecude运行流程
1.客户端提交代码 job.watiforcompletion()开始运行
2.请求到ResourceManager(经理)请求运行,ResourceManager返回jobId,和让客户端提交资源的路径
3.客户端读取Hdfs文件,进行切片,序列化得到FileSplit分片信息对象,然后把FileSplit(maptask读取文件),jar包(程序运行需要),xml(job对象序列化,包含设置的一些参数)提交到Hdfs上
4.客户端再次提交请求,让ResourceManager创建运行任务的容器(1.5G+1Core),ResourceManager将创建容器的任务放在任务队列中,排到任务时,在NodeManager上创建容器(2G+1core),并下载hdfs上的资源到工作目录等待,
5.客户端在监听容器创建完成后,发送shell…命令到对应NodeManager节点,容器内启动Appmaster(小组长)
6.Appmaster根据切片信息和xml中的参数分配maptask和reducetask个数,向ResourceManager请求容器,ResourceManager再次京任务放到队列中,等待有资源的NodeManage领取任务创建好容器,然后下载hdfs资源到工作目录,然后Appmaster控制NodeManage运行maptask和reducetask任务的完成
7.任务结束 容器和进程释放
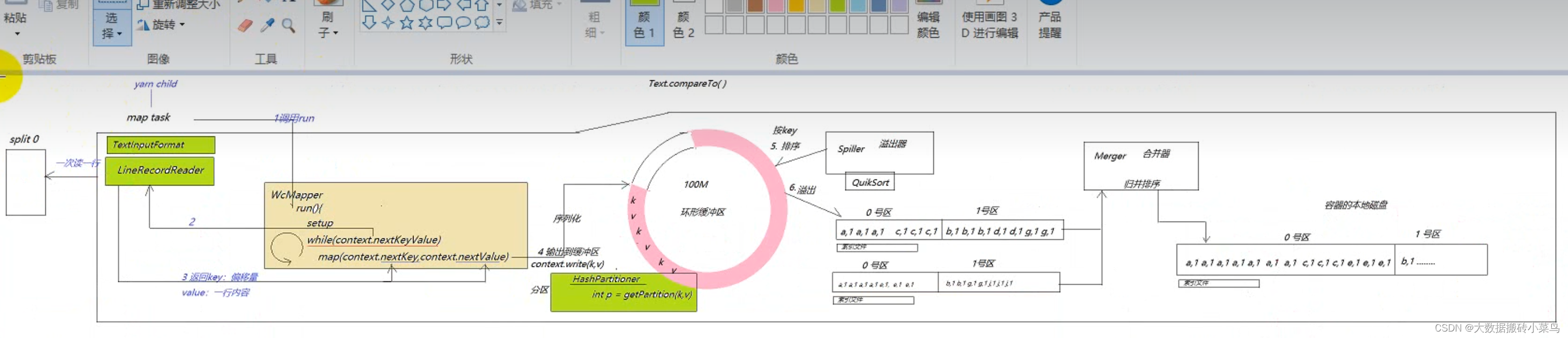
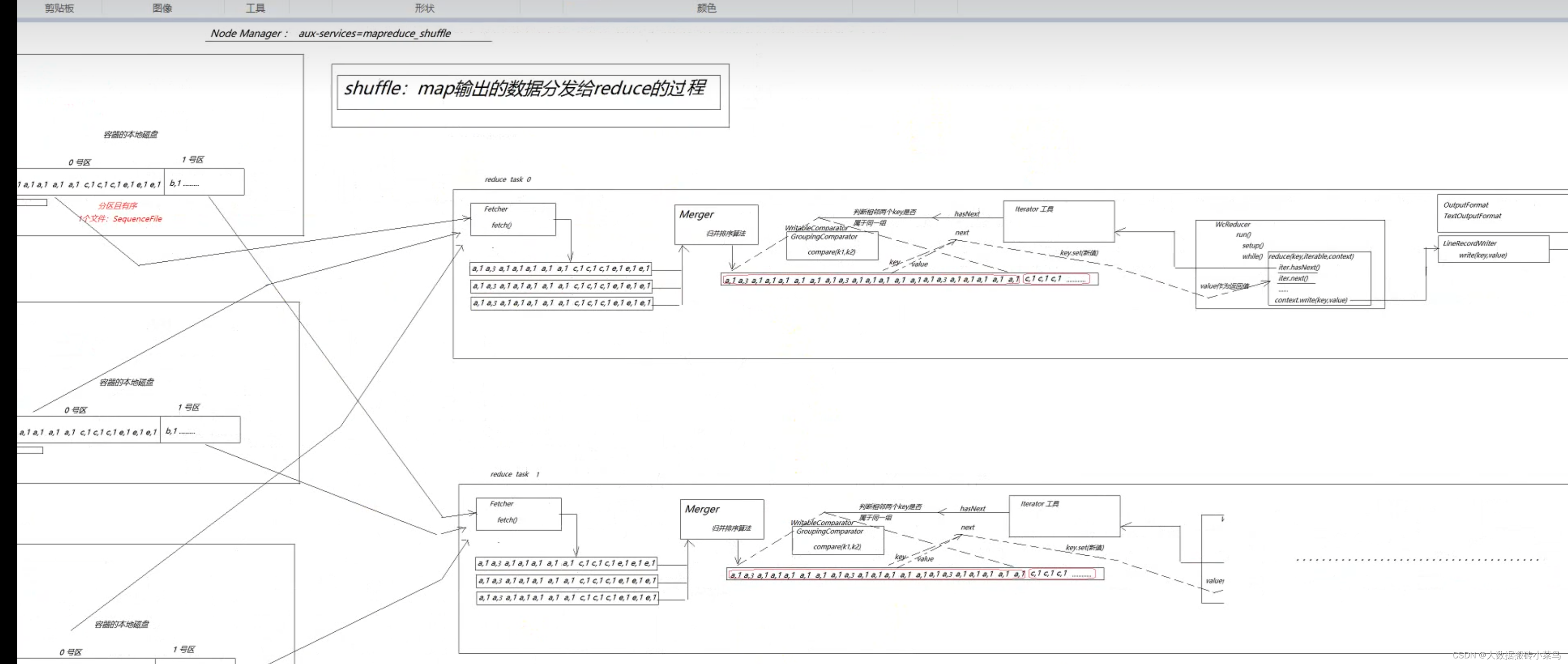
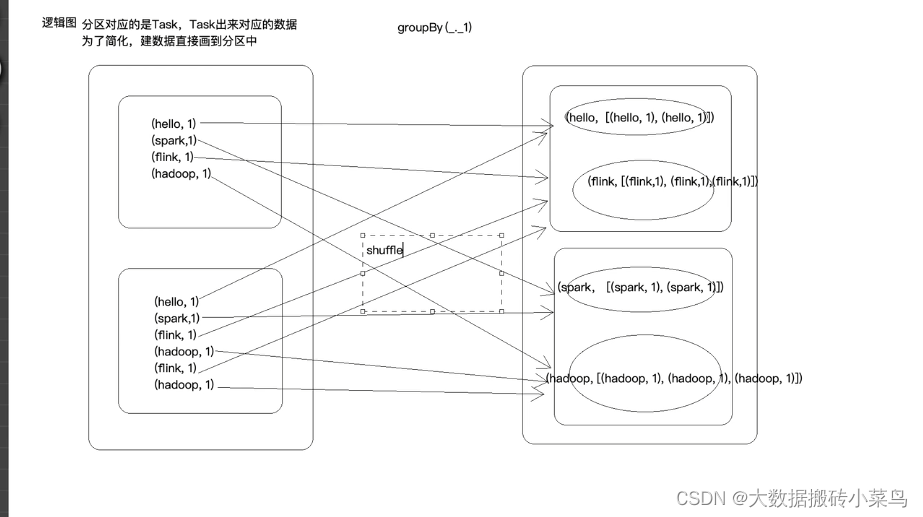
上图中mapreduce中的shuffle过程类比于spark groupby的算子产生的shuffle操作,都是key的hashcode值%(下游reducetask的个数/spark的task个数)














 5079
5079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









