







🌱HDFS✧MapReduce具体流程
🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲
🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲
一、HDFS读写流程
1、宏观写流程
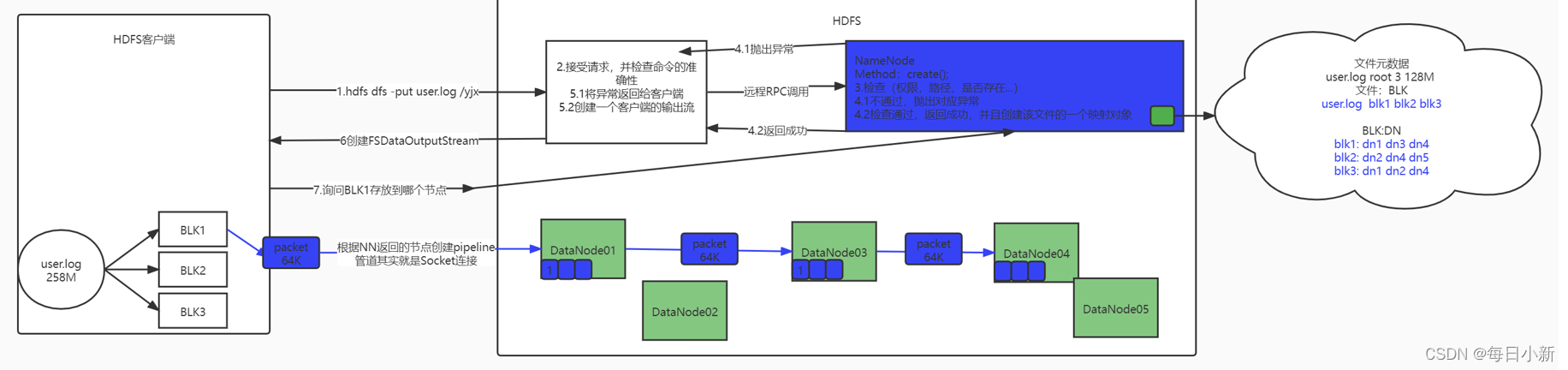
① 客户端提交数据hdfs dfs -put tomcat.tar.gz /xxx/
② 客户端提交数据,文件系统向rpc调用NN的create方法,创建之前会进行判断,判断是否已经存在,或者有权限,没问题则创建一个Entry对象,给客户端返回一个成功状态,会创建一个对象FSDataOutputStream的对象给客户端使用,否则抛出异常
③ 客户端获取通过机架感知策略获取数据存放数据块位置,建立一个Scoket链接管道,每次64Kpacket包传输至DN,每个节点相差一个64Kpacket包最后一个节点会返回一个成功状态信息。
2、微观写流程
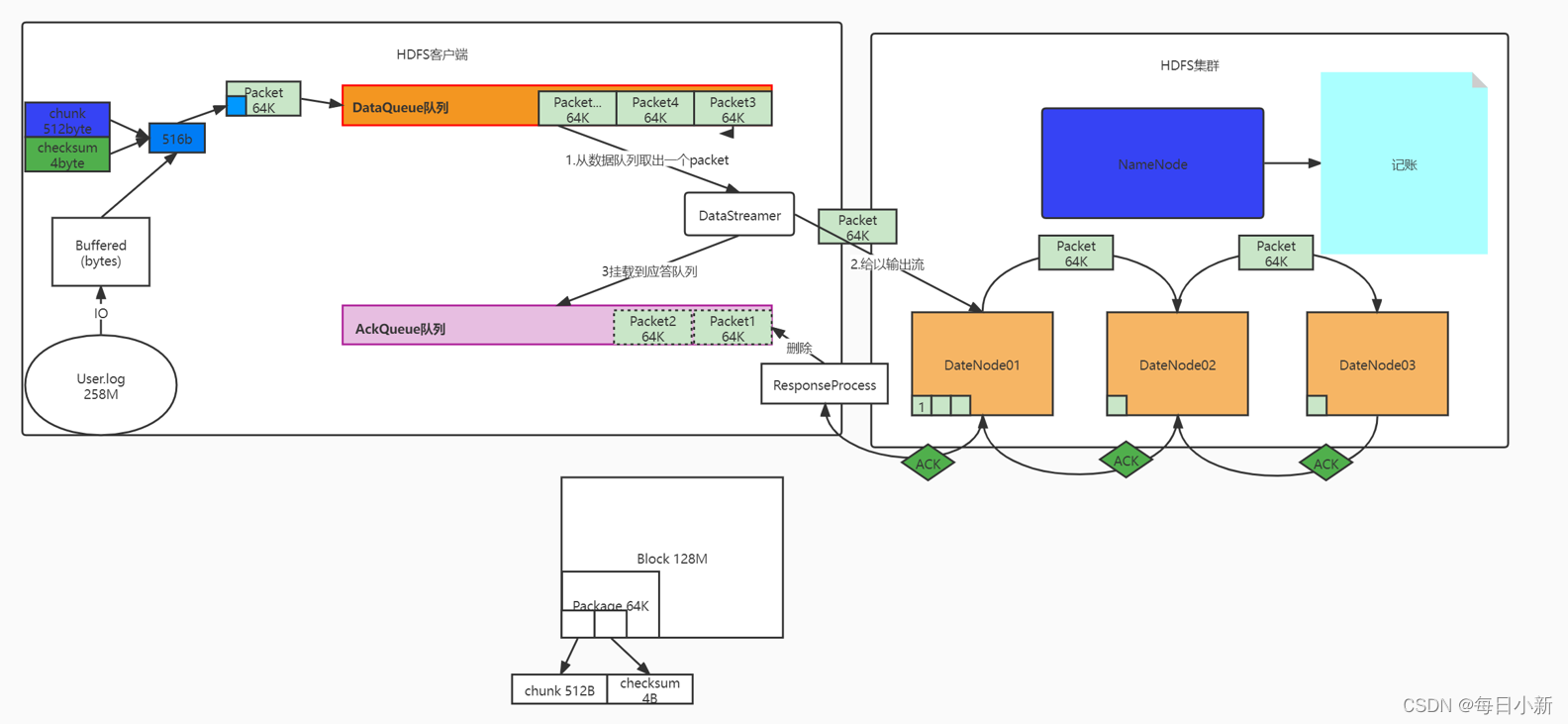
① 首先数据传输至内存将会划分为数据块,每个数据块由chunk数据+checksum校验组成516byte,再由多个这样的块组成一个Packet64k,通过管道将packet传至DQ队列中,再由DataStreamer取数据给DN,并将当前packet存一份到AQ队列中防止当前块传输失败,一旦失败,DataSteamer会将AQ块挂载到DQ队列重新发送
② 数据出错,在传输过程中,packet传输错误怎么办,所以需要DataSteamer做中间商将每次传输的packet挂载到另一个队列中作为备份,一旦出错备份数据提到队列中重新发送一份
③ 传输效率,丛客户端取数据快,但存数据慢,故引入队列作为缓存数据块
3、读数据流程
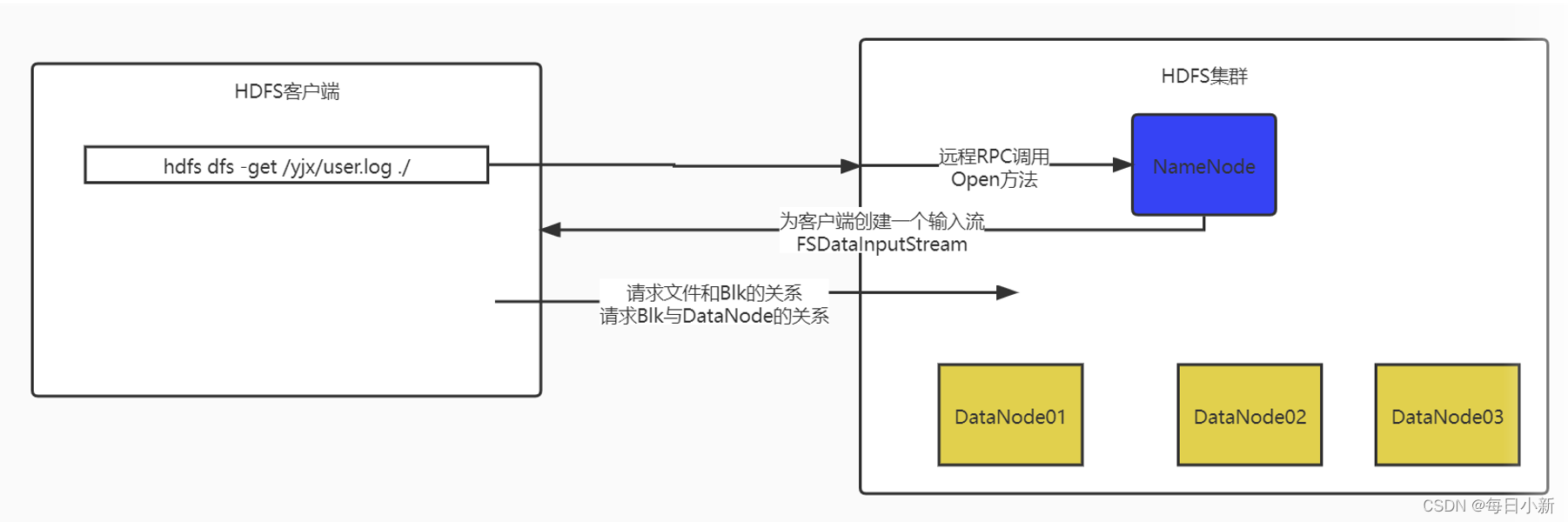
客户端发起读数据,通过rpc调用NameNode的open方法,为客户端创建一个FSDataInputSteam通道,客户端请求获取文件与块的映射块与DN的映射后,合并数据返回数据
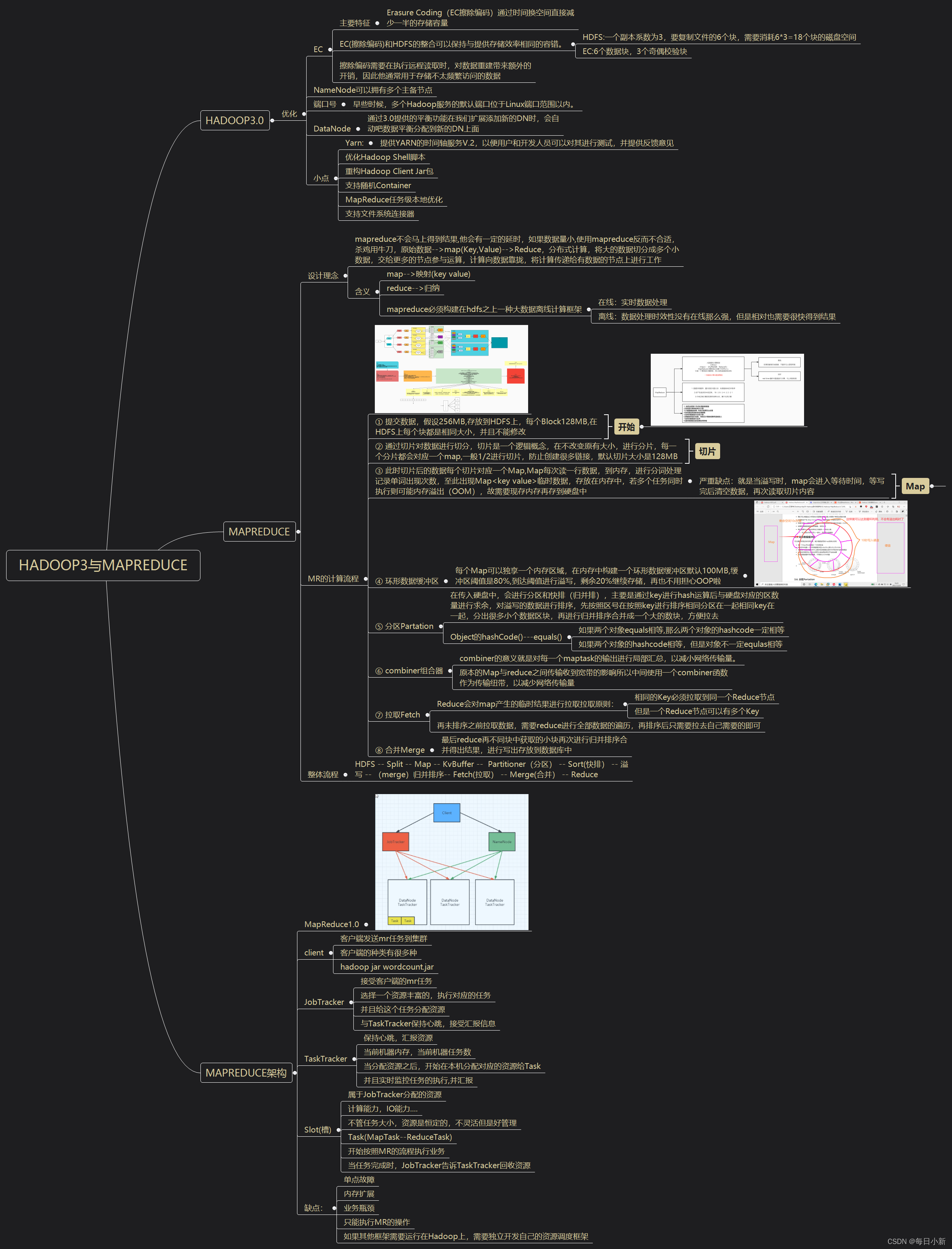
二、MapReduce计算流程
总体流程如图
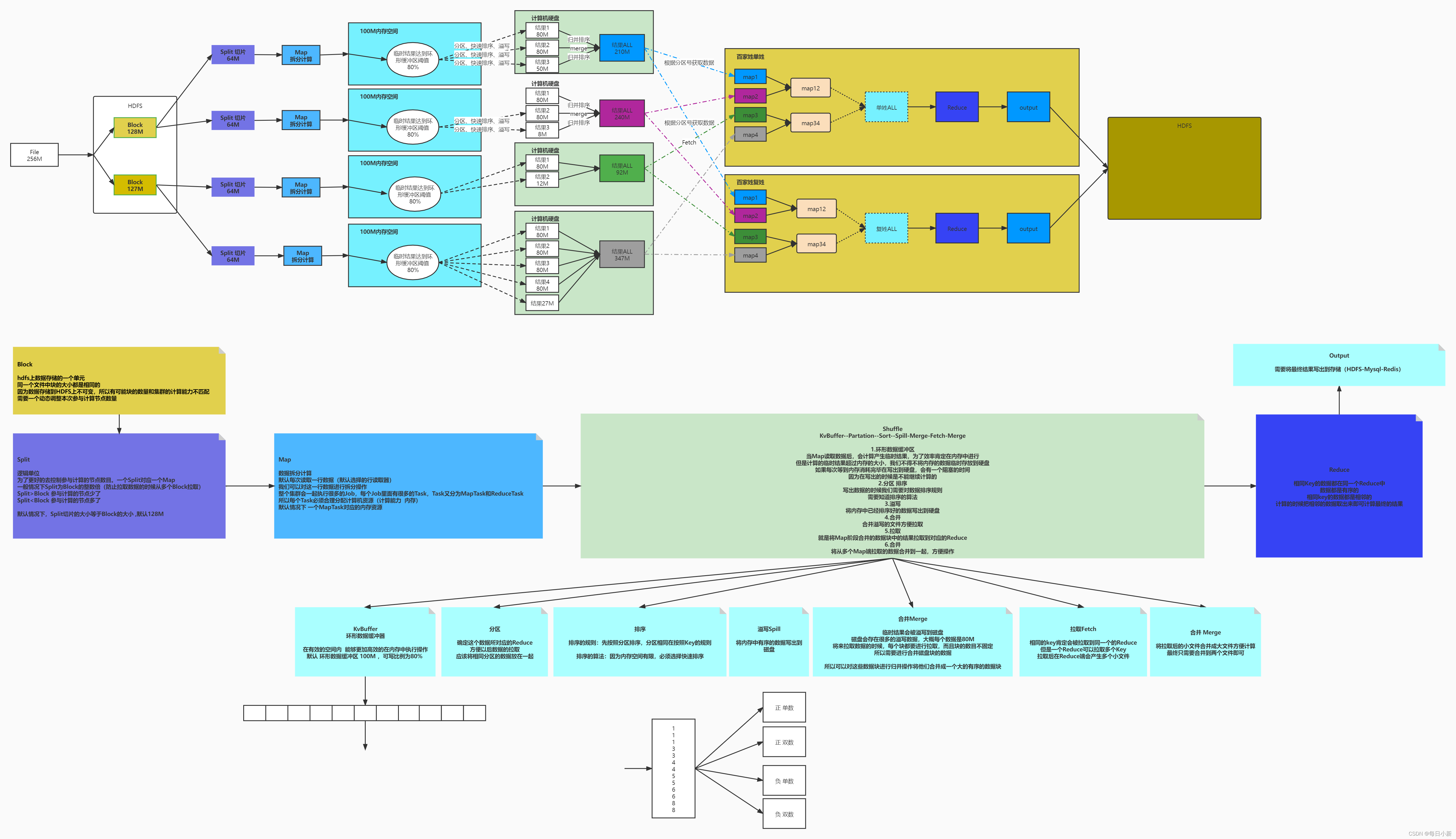
① 提交数据,假设256MB,存放到HDFS上,每个Block128MB,在HDFS上每个块都是相同大小,并且不能修改
② 通过切片对数据进行切分,切片是一个逻辑概念,在不改变原有大小,进行分片,每一个分片都会对应一个map,一般1/2进行切片,防止创建很多链接,默认切片大小是128MB
③ 此时切片后的数据每个切片对应一个Map,Map每次读一行数据,到内存,进行分词处理记录单词出现次数,至此出现Map临时数据,存放在内存中,若多个任务同时执行则可能内存溢出(OOM),故需要现存内存再存到硬盘中。(严重缺点:就是当溢写时,map会进入等待时间,等写完后清空数据,再次读取切片内容Map)
④ 环形数据缓冲区
每个Map可以独享一个内存区域,在内存中构建一个环形数据缓冲区默认100MB,缓冲区阈值是80%,到达阈值进行溢写,剩余20%继续存储,再也不用担心OOP啦。
⑤ 分区Partation
在传入硬盘中,会进行分区和快排(归并排),主要是通过key进行hash运算后与硬盘对应的区数量进行求余,对溢写的数据进行排序,先按照区号在按照key进行排序相同分区在一起相同key在一起,分出很多小个数据区块,再进行归并排序合并成一个大的数块,方便拉去
Object的hashCode()—equals()
如果两个对象equals相等,那么两个对象的hashcode一定相等
如果两个对象的hashcode相等,但是对象不一定equlas相等
⑥ combiner组合器
combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量。
原本的Map与reduce之间传输收到宽带的影响所以中间使用一个combiner函数作为传输纽带,以减少网络传输量。
⑦ 拉取Fetch
Reduce会对map产生的临时结果进行拉取拉取原则:
相同的Key必须拉取到同一个Reduce节点。
但是一个Reduce节点可以有多个Key。
在未排序之前拉取数据,需要reduce进行全部数据的遍历,再排序后只需要拉去自己需要的即可。
⑧ 合并Merge
最后reduce再不同块中获取的小块再次进行归并排序合并得出结果,进行写出存放到数据库中
------------------------------------------------------------------------------------------------------------------------------------
整体流程
HDFS – Split – Map – KvBuffer – Partitioner(分区) – Sort(快排) – 溢写 – (merge)归并排序-- Fetch(拉取) – Merge(合并) – Reduce
🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎🌲🍎















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











