







1.元组和列表的原理和操作
计算创建元组和列表所需要的时间:ipython 中使用 timeit
1.1 元组和列表的区别:
在内存占用和运算时间方面,元组比列表都更有优势。
当内容不发生改变的情况下,优先选用元组;当内容需要改变的情况下,优先选用列表。
1.2 命名元组
collections模块中的namedtuple函数
namedtuple: 接收两个参数,第一个创建的类型名称,第二个列表
from collections import namedtuple
Fruits = namedtuple('Fruits', ['name', 'color', 'size'])
f = Fruits('watermelon', 'green', '3')
print(f.name)
# 输出结果为: watermelon1.3 Python的数据类型分为三类:
- 数值:23
- 序列:字符串,列表,元组
- 散列: 字典,集合
2.字典和集合的原理及应用

字典推导式
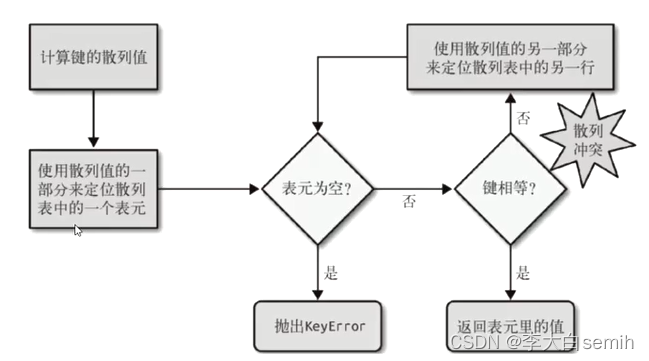
字典查找值的过程
性能分析:
从时间上比较:集合, 字典,元组,列表
从内存上比较:字典, 集合, 列表,元组
3. 推导式
3.1 列表推导式
将遍历到的值取到前面
lis_nu = [i for i in range(1,101)]
print(lis_nu)3.2 字典推导式
dit_nu = {i: i+1 for i in range(10)}
print(dit_nu)
> {0: 1, 1: 2, 2: 3, 3: 4, 4: 5, 5: 6, 6: 7, 7: 8, 8: 9, 9: 10}
3.3 生成器
3.3.1 ()
优势:节约内存,提高性能
ge = (i for i in range(100))
a = next(ge)
print(a)
> 03.3.2 yield
yield 通过next() 取值
3.4 迭代器
迭代器可以通过next()取值
可迭代对象:可以for循环遍历的都是可迭代对象
将可迭代对象转换为迭代器:iter(可迭代对象)
生成器是迭代器的一种

3.4.2 send() 函数
def s_d():
for i in range(6):
j = yield i
print(j)
# send: 与生成器进行交互
dd = s_d()
print(next(dd))
print(dd.send(10))
》输出结果为:
0
10
1
send(num)函数,相当于next()函数,并且send(num)函数传进去的num值等于 yield i
















 1326
1326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











