







51、岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
示例 2:
输入:grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
输出:3
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
思路解答:
解法一:深度优先搜索(DFS):
- 遍历整个二维网格。
- 对于每个陆地(即值为’1’的格子),进行深度优先搜索,将与该陆地相连的所有陆地标记为已访问。
- 统计岛屿的数量,即进行上述搜索的次数。
def numIslands(self, grid: list[list[str]]) -> int:
def dfs(grid, i, j):
if i < 0 or i >= len(grid) or j < 0 or j >= len(grid[0]) or grid[i][j] == '0':
return
grid[i][j] = '0' # 标记当前陆地为已访问
# 递归访问当前陆地的上下左右四个方向
dfs(grid, i + 1, j)
dfs(grid, i - 1, j)
dfs(grid, i, j + 1)
dfs(grid, i, j - 1)
if not grid:
return 0
num_islands = 0
rows, cols = len(grid), len(grid[0])
for i in range(rows):
for j in range(cols):
if grid[i][j] == '1':
num_islands += 1
dfs(grid, i, j)
return num_islands
解法二:广度优先搜索(BFS):
- 使用队列来实现广度优先搜索。
- 遍历整个二维网格。
- 对于每个陆地(即值为’1’的格子),将其加入队列,并将其标记为已访问。
- 不断从队列中取出元素,探索其周围的陆地,并将未访问的陆地加入队列,直到队列为空。
def numIslands2(grid):
def bfs(grid, i, j):
queue = collections.deque([(i, j)])
grid[i][j] = '0' # 标记当前陆地为已访问
while queue:
x, y = queue.popleft()
directions = [(1, 0), (-1, 0), (0, 1), (0, -1)]
for dx, dy in directions:
new_x, new_y = x + dx, y + dy
if 0 <= new_x < len(grid) and 0 <= new_y < len(grid[0]) and grid[new_x][new_y] == '1':
queue.append((new_x, new_y))
grid[new_x][new_y] = '0' # 标记当前陆地为已访问
if not grid:
return 0
num_islands = 0
rows, cols = len(grid), len(grid[0])
for i in range(rows):
for j in range(cols):
if grid[i][j] == '1':
num_islands += 1
bfs(grid, i, j)
return num_islands
52、腐烂的橘子
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格; - 值
1代表新鲜橘子; - 值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。
示例 1:
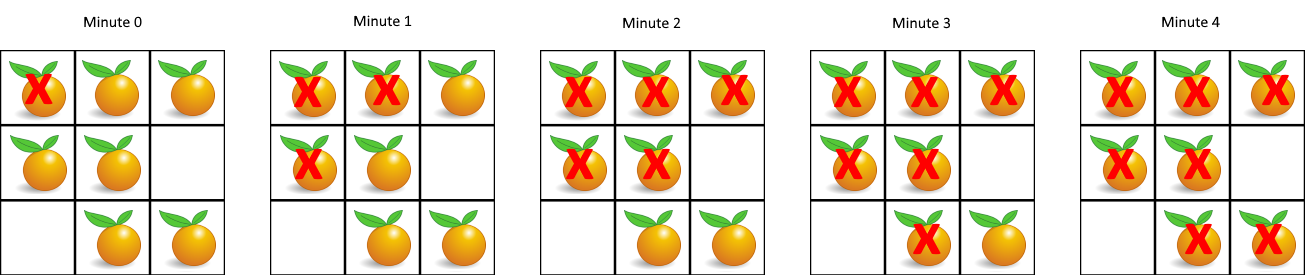
输入:grid = [[2,1,1],[1,1,0],[0,1,1]]
输出:4
示例 2:
输入:grid = [[2,1,1],[0,1,1],[1,0,1]]
输出:-1
解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个方向上。
示例 3:
输入:grid = [[0,2]]
输出:0
解释:因为 0 分钟时已经没有新鲜橘子了,所以答案就是 0 。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 10grid[i][j]仅为0、1或2
思路解答:
- 使用广度优先搜索(BFS)来模拟橘子腐烂的过程。
- 首先统计初始时刻新鲜橘子的数量,并将腐烂橘子的位置加入队列。
- 不断进行BFS,每一轮BFS表示经过一分钟,腐烂的橘子会影响周围的新鲜橘子腐烂。
- 在BFS过程中,更新新腐烂的橘子位置,同时减少新鲜橘子的数量,直到没有新鲜橘子或者无法继续腐烂为止。
def orangesRotting(self, grid: list[list[int]]) -> int:
if not grid:
return 0
rows, cols = len(grid), len(grid[0])
fresh_oranges = 0
rotten_oranges = collections.deque()
# 统计新鲜橘子的数量,并将腐烂橘子的位置加入队列
for i in range(rows):
for j in range(cols):
if grid[i][j] == 1:
fresh_oranges += 1
elif grid[i][j] == 2:
rotten_oranges.append((i, j))
directions = [(1, 0), (-1, 0), (0, 1), (0, -1)]
minutes = 0
while fresh_oranges > 0 and rotten_oranges:
minutes += 1
new_rotten_oranges = collections.deque()
while rotten_oranges:
x, y = rotten_oranges.popleft()
for dx, dy in directions:
new_x, new_y = x + dx, y + dy
if 0 <= new_x < rows and 0 <= new_y < cols and grid[new_x][new_y] == 1:
grid[new_x][new_y] = 2
fresh_oranges -= 1
new_rotten_oranges.append((new_x, new_y))
rotten_oranges = new_rotten_oranges
return minutes if fresh_oranges == 0 else -1
53、课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
思路解答:
- 构建一个有向图,用邻接表或邻接矩阵表示课程之间的先修关系。
- 统计每门课程的入度,即指向该课程的边的数量。
- 将入度为0的课程加入一个队列中。
- 不断从队列中取出课程,减少其指向的课程的入度,如果减少后入度为0,则将该课程加入队列。
- 最终判断是否所有课程都被取出,如果是则说明可以完成所有课程学习,否则说明存在环无法完成所有课程学习。
def canFinish(self, numCourses: int, prerequisites: list[list[int]]) -> bool:
graph = collections.defaultdict(list)
indegree = [0] * numCourses
# 构建图和入度数组
for course, pre_course in prerequisites:
graph[pre_course].append(course)
indegree[course] += 1
# 拓扑排序
queue = [i for i in range(numCourses) if indegree[i] == 0]
while queue:
node = queue.pop(0)
numCourses -= 1
for neighbor in graph[node]:
indegree[neighbor] -= 1
if indegree[neighbor] == 0:
queue.append(neighbor)
return numCourses == 0
54、实现 Trie (前缀树)
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
示例:
输入
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
提示:
1 <= word.length, prefix.length <= 2000word和prefix仅由小写英文字母组成insert、search和startsWith调用次数 总计 不超过3 * 104次
思路解答:
- TrieNode 类的设计:设计一个 TrieNode 类,每个节点包含一个子节点字典和一个标志来表示是否是一个单词的结尾。
- Trie 类的设计:设计一个 Trie 类,包含插入、搜索和前缀搜索的方法。
- 插入操作:从根节点开始,逐个字符插入到 Trie 中,如果字符不存在于当前节点的子节点字典中,则创建一个新的 TrieNode。
- 搜索操作:从根节点开始,逐个字符搜索 Trie 中的单词,如果遇到字符不存在于当前节点的子节点字典中,则返回 False;如果搜索完所有字符后,当前节点的 is_end_of_word 标志为 True,则返回 True。
- 前缀搜索:与搜索操作类似,但不需要判断 is_end_of_word 标志,只需判断是否能够搜索到最后一个字符。
class TrieNode:
def __init__(self):
self.children = {}
self.is_end_of_word = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word: str) -> None:
node = self.root
for char in word:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_end_of_word = True
def search(self, word: str) -> bool:
node = self._search_prefix(word)
return node is not None and node.is_end_of_word
def startsWith(self, prefix: str) -> bool:
return self._search_prefix(prefix) is not None
def _search_prefix(self, prefix):
node = self.root
for char in prefix:
if char not in node.children:
return None
node = node.children[char]
return node














 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









