







什么是索引?
索引用于快速找出在某个列中的有某一个特定值的行,不适用索引,mysql必须从第一条数据开始检索数据库,直至找到符合条件的行;如果表中拥有一个索引,mysql可以快速到达一个位置去搜索数据库文件,而不必查看所有数据,那么会节省很多时间

索引分类
- 单值索引:一个索引只包含当个列,一个表可以有多个单列索引
- 唯一索引:索引列的值必须唯一,允许有空值
- 复合索引:一个索引包含多个列
- 全文索引:只有在MyISAM引擎可用,只能在字符串类型字段上使用全文索引
- 空间索引:空间索引是对空间数据类型的字段建立的索引
索引操作
在表上定义了主键时,会自动创建一个对应的唯一索引;
在表上定义了外键时,会自动创建一个普通索引
# 创建索引
CREATE INDEX index_name ON table_name(字段);
# 删除索引
DROP INDEX index_name ON table_name;
# 查看索引
SHOW INDEX FROM table_name;
唯一索引
# 创建表millons
CREATE TABLE millons(
id INT,
text VARCHAR(10),
number INT
);
# 定义存储过程
'''
使用autocommit=0的好处:
等待所有sql语句生成后再执行,而不必生成一条执行一条
'''
delimiter //
CREATE PROCEDURE insert_millon(IN start_index INT,in end_index INT)
BEGIN
DECLARE i INT DEFAULT 0; # 计数i
SET autocommit=0; # 修改默认提交,取消自动提交
REPEAT
set i=i+1;
# 插入数据
# 使用的rand_s可以查看<https://blog.csdn.net/weixin_45564816/article/details/118548404>
INSERT INTO millons VALUES(start_index+i,rand_s(4),FLOOR(1+RAND()*100));
UNTIL i=end_index
END REPEAT;
commit;
END //
delimiter ;
生成数据
运行时间比较久
CALL insert_millon(1,10000000);

查询id=1000的数据
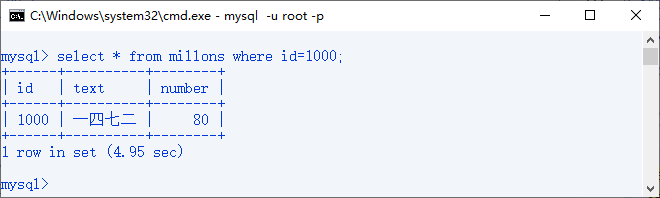
使用explain分析SQL语句
可以看到 key:NULL,也就是实际选用的索引为NULL

这时候我们将id字段设为主键
保存过程有点慢是因为正在生成索引表

再次查询id=1000的所有数据
可以看出时间减少了很多
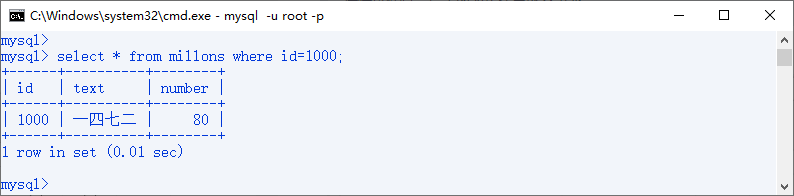
再次使用explain分析SQL语句
key:PRIMARY,也就是实际选用的索引为主键
key_len:4是因为主键的类型为int,占4个字节

普通索引
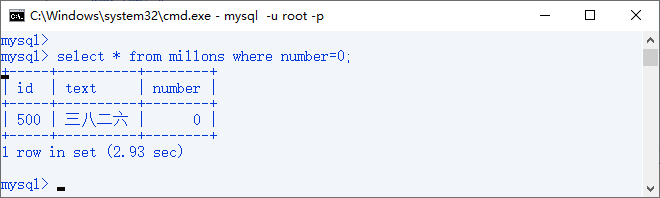
手动将id=500的number字段值改为0;查找number=0
添加索引
CREATE INDEX index_number ON millons(number);
查找语句
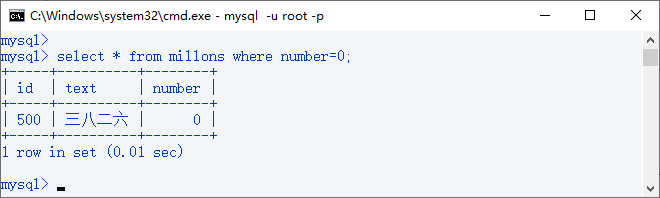
查看索引结构

索引结构
索引结构一共分为两种:
- btree索引
- hash索引
btree索引(B+树索引):
B+树是一个平衡的多叉树,从根节点到每一个叶节点的高度差值不超过1,而且同层级的节点间有指针相互连接;如图所示:
假设拥有一组数据,100,200,300,400,500,600,700,生成一个B+树;如果要找到500所在的位置
1、首先在根节点400进行判断 500>400 检索右叶子结点
2、在子节点600进行判断 500<600 检索左叶子结点
3、最后找出500所在的位置

Hash索引
哈希索引采用特定的hash算法,将键值转换为哈希值,检索时不需要像B+树一样从根节点到叶子节点逐级查找,只需一次就可以查找到对应位置,Hash索引的查询效率远高于B+树索引。
InnoDB引擎的数据库不支持Hash索引
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











