







顺序容器
1.vector
1.1 vector的遍历
定义一个str_record 将原有一个str的数组通过‘ ’(空格)分割开来
vector<string> str_record;
string str = "dog cat cat dog";
int pos = 0;
string str_temp = str;
cout << "size:" << str.size() ;
for (int i = 0; i <= str.size(); i++)
{
if (str[i] == ' '|| i == str.size() )
{
str_temp = str.substr(pos, i - pos); // pos表示要截取的字符串的开始的位置,i-pos代表要截取的字符串的长度
str_record.push_back(str_temp);
str_size++;
pos = i + 1;
}
}
(1) 使用for_each (#include< algorithm >)
void MyPrint_Vector(string str)
{
cout << str << ' ';
}
for_each(str_record.begin(), str_record.end(), MyPrint_Vector);
(2) 使用for(auto)
for (auto ele : str_record)
cout << ele << ' ';
(3)迭代器遍历
定义迭代器的起始位置
vector<string>::iterator pBegin = str_record.begin();
【1】for遍历
for (vector<string>::iterator it = str_record.begin(); it != str_record.end(); it++) {
cout << *it << endl;
}
【2】while遍历
while (pBegin != pEnd) {
cout << *pBegin << endl;
pBegin++;
}
(4)迭代器反向遍历
利用crbegin和crend迭代器,实现反向遍历迭代器。
vector<int> record;
record.push_back(5);
record.push_back(2);
record.push_back(4);
record.push_back(1);
auto iter = record.crbegin();
while( iter != record.crend())
{
cout << *iter << ' ';
iter++;
}
cout << endl;
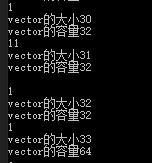
1.2 vector空间的增长
容器的size是指它已经保存元素的个数,
capacity指的是不分配新的内存空间的前提下它最多可以保存的元素
#include<iostream>
#include<fstream>
#include<sstream>
#include<string>
#include<vector>
#include<forward_list>
using namespace std;
int main(int argc, char**argv)
{
vector<int> vec1;
int a;
while (cin>>a)
{
vec1.push_back(a);
cout<<"vector的大小"<<vec1.size()<<endl;;
cout<<"vector的容量"<<vec1.capacity()<<endl;
}
return 0;
}
1.3 vector的扩容
(1)reverse(n)函数:分配能容纳n个元素的内存。
(2)capacity():返回容器的容量。
(3)resize(n):改变size但不改变capacity 没法释放vector的内存
c.resize(5); //初始化5个0
cresize(5,1); //初始化5个1
(4)shrink_to_fit():将capacity减少为与size相同大小
reserve改变capacity 但只保证扩大会成功
1.4 vector创建二维数组
二维数组的创建以及如何获取二维数组的行与列的大小。
二维vector初始化大小的方法:
大小为rows*cols,初始值为0的二维vector。
vector<vector<int> > vec(rows, vector<int>(cols, 0));
int raw = vec.size();//行
int col = vec[0].size();//列
行和列的迭代器:
//行的迭代器
for(vector<vector<int>>::iterator it=vec.begin();it!=vec.end();it++)
{
//列的迭代器
for(vector<int>::iterator vit=(*it).begin();vit!=(*it).end();vit++)
{
if(target==*vit)
return true;
}
}
1-5 vector的翻转
剑指offer第6题
通过algorithm中的reverse,放入首尾迭代器即可。
reverse(result.begin(),result.end());
1-6 vector的头部插入数据
剑指offer第6题
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
vector<int> result;
while( head != NULL)
{
result.insert(result.begin(),head->val);
head = head->next;
}
return result;
}
};
1-7 vector元素的排序
(1)从大到小
使用sort输入迭代器是默认从大到小排序
sort(result.begin(),result.end());
(2)从小到大
sort中输入反向迭代器就可以实现从小到大排序
sort(result.crbegin(),result.crend());
2.pair的遍历
2-1 对pair指定元素的排序函数
bool cmp(pair< int,char > pair1, pair< int,char > pair2)
{
return pair1.first > pair2.first;
}
pair<int,char> freq[256];
2-2 pair的插入
2-3 对pair指定位置的元素进行排序
sort(freq, freq+256,cmp);
2-4 pair遍历:
for (auto ele : freq)
cout << ele.first << ' ' << ele.second;
cout << endl;
3.使用unique
对对于一个vector我们对他排序后,如果想要去重使用unique可以帮助我们得到去重后的数组,返回一个指向不重复值范围末尾的迭代器,即1345678后面的数据。
通过erase可以把不重复范围后面到原来nums的末尾进行清除。
vector<int> nums = {1, 3, 3,4,5,6,7,7,8};
sort(nums.begin(), nums.end());
vector<int>::iterator iter = unique(nums.begin(), nums.end());
nums.erase(iter, nums.end());
4.string
4-1 string的find与npos
1.string类中的find()函数,它是一个查找函数,功能还是很强大的,通常和string::npos具有关系。
2.string::find()函数:是一个字符或字符串查找函数,该函数有唯一的返回类型,即string::size_type,即一个无符号整形类型,可能是整数也可能是长整数。如果查找成功,返回按照查找规则找到的第一个字符或者子串的位置;如果查找失败,返回string::npos,即-1(当然打印出的结果不是-1,而是一个很大的数值,那是因为它是无符号的。
3.string::npos静态成员常量:是对类型为size_t的元素具有最大可能的值。当这个值在字符串成员函数中的长度或者子长度被使用时,该值表示“直到字符串结尾”。作为返回值他通常被用作表明没有匹配。
string::npos是这样定义的:static const size_type npos = -1;
剑指offer中的第五题:
string s = “We are happy.”;
int pos=0;
//s.npos换成-1也可以
while( ( pos = s.find(' ') ) != s.npos )
{
s.replace(pos, 1 , "%20");
}
return s;
5.数组array
5-1.数组的遍历
因为数组没有首尾迭代器,但是可以用STL库中的begin和end函数(iterator头文件中)来获取首尾的指针,通过指针来遍历
begin指向首元素的指针
end返回的尾元素的下一位元素的指针
int array[] = {1,3,5,7};
int *array_begin = begin(array);
int *array_end = end(array);
while(array_begin!=array_end)
{
cout << *array_begin << endl;
array_begin++;
}
关联容器
1、关联容器和顺序容器的本质区别:关联容器是通过键存取和读取元素、顺序容器通过元素在容器中的位置顺序存储和访问元素。
因此,关联容器不提供front、push_front、pop_front、back、push_back以及pop_back,此外对于关联容器不能通过容器大小来定义,因为这样的话将无法知道键所对应的值什么。
2、两个主要的关联容器类型是map和set。map的元素以键-值对的形式组织:键用作元素在map的索引,而值则表示所存储和读取的数据。
set仅包含一个键,并有效地支持关于某个键是否存在的查询。
set和map类型的对象不允许为同一个键添加第二个元素。
如果一个键必须对应多个实例,则需使用multimap或mutiset类型,这两种类型允许多个元素拥有相同的键。
1.map
1-1. map的定义
1、定义一个map,必须指定关键字和值的类型;
2、从map中提取一个元素时,会得到一个pair类型的对象;
3、map中使用的pair用first成员保存关键字,用second成员保存对应的值;
1-2. map的插入
如果是map
map<int,int> mymap;
//下标直接创建
mymap[5] = 9;
mymap[8] = 3;
//或者以下4种方式创建
mymap.insert(make_pair(2,4));
mymap.insert(pair<int,int>(11,7));
mymap.insert(map<int,int>::value_type(4,20) );
mymap.insert({5,6});//无法覆盖前面的值,如果已经在map中,则什么都不做。 还是5,9
//遍历
auto iter_map = mymap.begin();
cout << "mymap_size:" << mymap.size() << endl;
while( iter_map != mymap.end() )
{
cout << iter_map->first << ' ' << iter_map->second << endl;;
iter_map++;
}
结果为:可以看到关键字按照顺序排列。

1-3. map的遍历
auto iter_map = mymap.begin();
cout << "mymap_size:" << mymap.size() << endl;
while( iter_map != mymap.end() )
{
cout << iter_map->first << ' ' << iter_map->second << endl;;
iter_map++;
}
1-4. map的查找
if (map.find(3) != map.end()) {
cout << "find key=" << map.find(3)->first << ", value=" << map.find(3)->second << endl;
}
if (map.count(5) > 0) {
cout << "find 5: " << map.count(5) << endl;
}
1-5. map与unordered_map的区别及优缺点
如果把1-2节中的map替换成unordered_map,则后insert的在前面打印出来。

区别:
因为:
map内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而AVL是严格平衡二叉搜索树),红黑树具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照二叉搜索树(又名二叉查找树、二叉排序树,特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值)存储的,使用中序遍历可将键值按照从小到大遍历出来。
unordered_map内部实现了一个哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。
优缺点以及适用处
map:
优点:
有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高
缺点:
空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
适用处:对于那些有顺序要求的问题,用map会更高效一些
unordered_map:
优点: 因为内部实现了哈希表,因此其查找速度非常的快
缺点: 哈希表的建立比较耗费时间
适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
总结:
内存占有率的问题就转化成红黑树 VS hash表 , 还是unorder_map占用的内存要高。
但是unordered_map执行效率要比map高很多
对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相同,因为遍历是按照哈希表从前往后依次遍历的
2.set
2-1.set的定义
set就是关键字的简单集合。当想知道一个值是否存在时,set是最有用的。
定义一个map时,必须即指明关键字类型又指明值类型;
而定义一个set时,只需指明关键字类型。
set中的key_type和value_type是一样的;
set中保存的值就是关键字
2-2.set的插入
set的插入insert两种方法:
1.接受一对迭代器
2.初始化列表
vector<int> ivec = { 2,4,6,8,2,4,6,8};
set<int> set2;
//1.接受一对迭代器
set2.insert(ivec.cbegin(),ivec.cend());
//2.初始化列表
set2.insert({1,3,5,7,1,3,5,7});
2-3.set的遍历
set<int> set_v;
set_v.insert( {1,7,8,5,6} );
set_v.insert(5);
set<int>::iterator s_iter = set_v.begin();
while( s_iter != set_v.end() )
{
cout << *s_iter << endl;
s_iter++;
}
2-5. unordered_set
unordered_set 是基于hash表的,因此并不是顺序存储。















 1927
1927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









