



 本文深入探讨了线性回归的基本原理及其在预测数值型目标值的应用,通过实例展示了如何利用Python实现线性回归,并引入了局部加权线性回归(LWLR)以解决欠拟合问题,通过调整权重参数k来平衡模型复杂度,避免过拟合。
本文深入探讨了线性回归的基本原理及其在预测数值型目标值的应用,通过实例展示了如何利用Python实现线性回归,并引入了局部加权线性回归(LWLR)以解决欠拟合问题,通过调整权重参数k来平衡模型复杂度,避免过拟合。
一回归?
回归的目的是预测数值型的目标值。最直接的办法是依据输入写出一个目标值的计算公式。

现在的问题是,手里有数据矩阵X和对应的标签向量y,怎么才能找到w呢?一个常用的方法就是找出使误差最小的w。这里的误差是指预测u值和真实y值之间的差值,使用该误差的简单累加将使得正差值和负差值相互抵消,所以我们采用平方误差。

为啥能这么变化,记住一个前提:若x为向量,则默认x为列向量,x^T为行向量。将上述提到的数据矩阵X和标签向量y带进去,就知道为何这么变化了
在继续推导之前,我们要先明确一个目的:找到w,使平方误差和最小。因为我们认为平方误差和越小,说明线性回归拟合效果越好。

# -*- coding:utf-8 -*-
import matplotlib.pyplot as plt
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t')) - 1
xArr = []; yArr = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
xArr.append(lineArr)
yArr.append(float(curLine[-1]))
return xArr, yArr
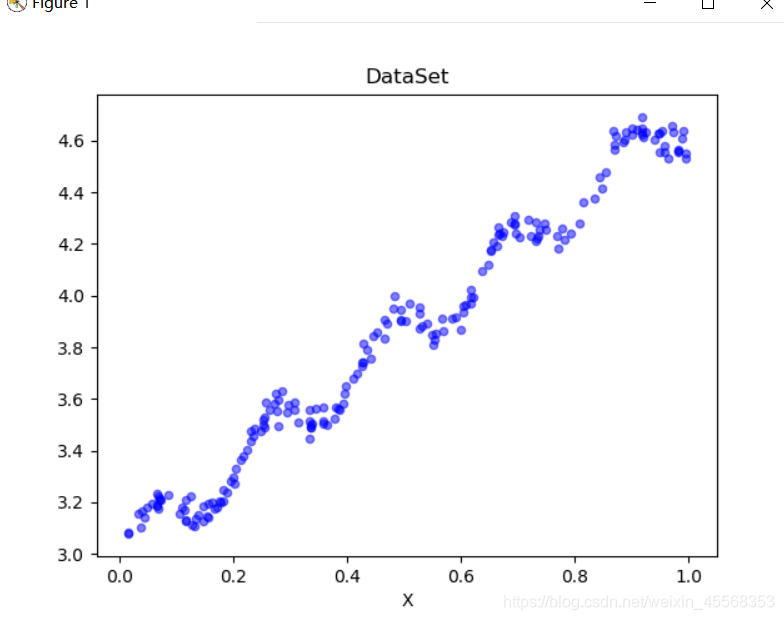
def plotDataSet():
xArr, yArr = loadDataSet('ex0.txt') #加载数据集
n = len(xArr) #数据个数
xcord = []; ycord = [] #样本点
for i in range(n):
xcord.append(xArr[i][1]); ycord.append(yArr[i]) #样本点
fig = plt.figure()
ax = fig.add_subplot(111) #添加subplot
ax.scatter(xcord, ycord, s = 20, c = 'blue',alpha = .5) #绘制样本点
plt.title('DataSet') #绘制title
plt.xlabel('X')
plt.show()
if __name__ == '__main__':
plotDataSet()
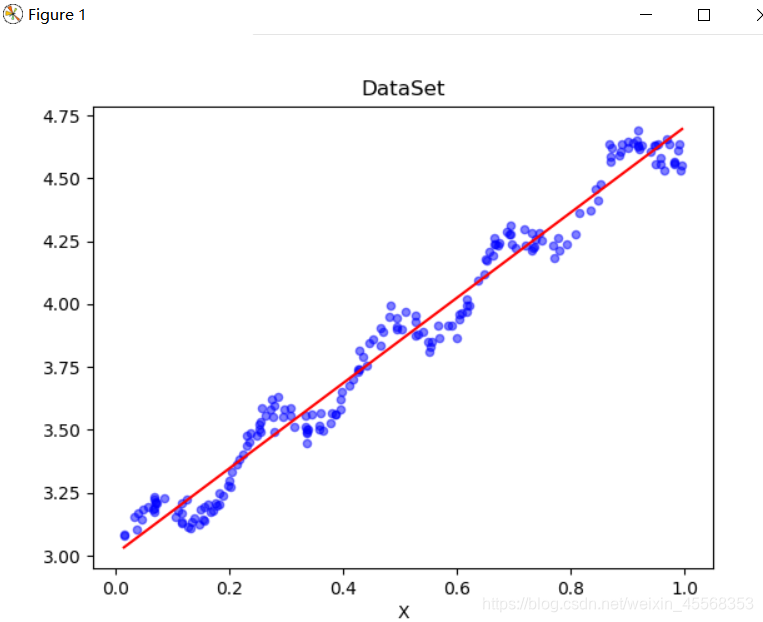
def plotRegression():
xArr, yArr = loadDataSet('ex0.txt') #加载数据集
ws = standRegres(xArr, yArr) #计算回归系数
xMat = np.mat(xArr) #创建xMat矩阵
yMat = np.mat(yArr) #创建yMat矩阵
xCopy = xMat.copy() #深拷贝xMat矩阵
xCopy.sort(0) #排序
yHat = xCopy * ws #计算对应的y值
fig = plt.figure()
ax = fig.add_subplot(111) #添加subplot
ax.plot(xCopy[:, 1], yHat, c = 'red') #绘制回归曲线
ax.scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0], s = 20, c = 'blue',alpha = .5) #绘制样本点
plt.title('DataSet') #绘制title
plt.xlabel('X')
plt.show()
def standRegres(xArr,yArr):
xMat = np.mat(xArr); yMat = np.mat(yArr).T
xTx = xMat.T * xMat #根据文中推导的公示计算回归系数
if np.linalg.det(xTx) == 0.0:
print("矩阵为奇异矩阵,不能求逆")
return
ws = xTx.I * (xMat.T*yMat)
return ws

线性回归的一个问题是有可能出现欠拟合现象,因为它求的是具有小均方误差的无偏估 计。显而易见,如果模型欠拟合将不能取得好的预测效果。所以有些方法允许在估计中引入一 些偏差,从而降低预测的均方误差。
其中的一个方法是局部加权线性回归(Locally Weighted Linear Regression,LWLR)。在该方法中,我们给待预测点附近的每个点赋予一定的权重。与kNN一样,这种算法每次预测均需要事先选取出对应的数据子集。该算法解除回归系数W的形式如下:
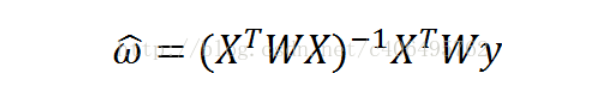
其中W是一个矩阵,这个公式跟我们上面推导的公式的区别就在于W,它用来给每个店赋予权重

def plotlwlrRegression():
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
xArr, yArr = loadDataSet('ex0.txt') #加载数据集
yHat_1 = lwlrTest(xArr, xArr, yArr, 1.0) #根据局部加权线性回归计算yHat
yHat_2 = lwlrTest(xArr, xArr, yArr, 0.01) #根据局部加权线性回归计算yHat
yHat_3 = lwlrTest(xArr, xArr, yArr, 0.003) #根据局部加权线性回归计算yHat
xMat = np.mat(xArr) #创建xMat矩阵
yMat = np.mat(yArr) #创建yMat矩阵
srtInd = xMat[:, 1].argsort(0) #排序,返回索引值
xSort = xMat[srtInd][:,0,:]
fig, axs = plt.subplots(nrows=3, ncols=1,sharex=False, sharey=False, figsize=(10,8))
axs[0].plot(xSort[:, 1], yHat_1[srtInd], c = 'red') #绘制回归曲线
axs[1].plot(xSort[:, 1], yHat_2[srtInd], c = 'red') #绘制回归曲线
axs[2].plot(xSort[:, 1], yHat_3[srtInd], c = 'red') #绘制回归曲线
axs[0].scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0], s = 20, c = 'blue', alpha = .5) #绘制样本点
axs[1].scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0], s = 20, c = 'blue', alpha = .5) #绘制样本点
axs[2].scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0], s = 20, c = 'blue', alpha = .5) #绘制样本点
#设置标题,x轴label,y轴label
axs0_title_text = axs[0].set_title(u'局部加权回归曲线,k=1.0',FontProperties=font)
axs1_title_text = axs[1].set_title(u'局部加权回归曲线,k=0.01',FontProperties=font)
axs2_title_text = axs[2].set_title(u'局部加权回归曲线,k=0.003',FontProperties=font)
plt.setp(axs0_title_text, size=8, weight='bold', color='red')
plt.setp(axs1_title_text, size=8, weight='bold', color='red')
plt.setp(axs2_title_text, size=8, weight='bold', color='red')
plt.xlabel('X')
plt.show()
def lwlr(testPoint, xArr, yArr, k = 1.0):
xMat = np.mat(xArr); yMat = np.mat(yArr).T
m = np.shape(xMat)[0]
weights = np.mat(np.eye((m))) #创建权重对角矩阵
for j in range(m): #遍历数据集计算每个样本的权重
diffMat = testPoint - xMat[j, :]
weights[j, j] = np.exp(diffMat * diffMat.T/(-2.0 * k**2))
xTx = xMat.T * (weights * xMat)
if np.linalg.det(xTx) == 0.0:
print("矩阵为奇异矩阵,不能求逆")
return
ws = xTx.I * (xMat.T * (weights * yMat)) #计算回归系数
return testPoint * ws
def lwlrTest(testArr, xArr, yArr, k=1.0):
m = np.shape(testArr)[0] #计算测试数据集大小
yHat = np.zeros(m)
for i in range(m): #对每个样本点进行预测
yHat[i] = lwlr(testArr[i],xArr,yArr,k)
return yHat
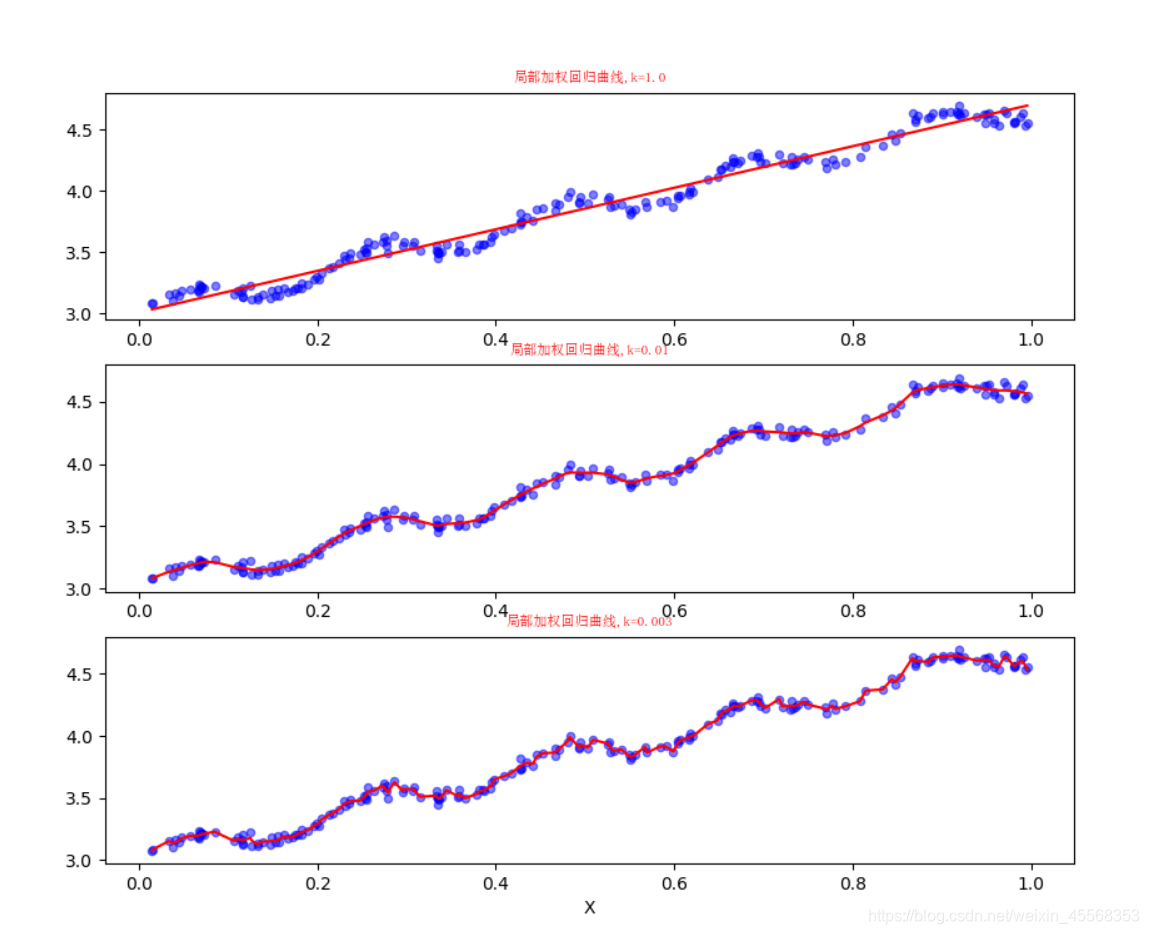
1 在局部加权线性回归中,过小的核可能导致过拟合现象,即测试集表现良好,训练集表现就渣渣了。
2 训练的模型要在测试集比较它们的效果,而不是在训练集上。

















 2631
2631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









