







文章目录
简单线性回归
学习基础
统计量
- 描述数据特征:
平均值:
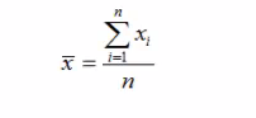
中位数:将数据从大到小排列,居于中间位置的变量
众数:数据中出现次数最多的数。
方差:

标准差:
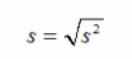
离散值越大,方差和标准差越大
回归问题
介绍
回归问题;y变量是连续数值型:如房价,下雨,降雨量
分类问题;y变量是类别型:如颜色类别,电脑版本,有无信誉
简单的线性回归
介绍
简单线性回归的自变量和应变量都只有一个,两个变量的变化可以用一条直线来描述。如果包含两个及以上自变量的话,就叫做多元回归分析。
回归模型
用来描述因变量和自变量关系以及偏差关系的方程叫做回归模型:
y = β0+β1*x+σ 其中β是参数,σ是偏差
关系
正向线性关系,反向线性关系,无关系
回归模型: y = β0+β1*x
y上面有个帽子叫估计值
分析的流程

首先,存在一个模型,然后根据模型来得到参数方程,得到参数值是关键。
然后,有一些例子,列出,通过现有的样本得出参数的的估计值。
简单的例子:

import numpy as np
#np.mean()求平均值
def fitslr(x,y):
n = len(x)
dinominator = 0
numerator = 0
for i in range(0,n):
numerator +=(x[i]-np.mean(x))*(y[i]-np.mean(y))
dinominator +=(x[i]-np.mean(x))**2
print("numerator:",numerator)
print("dinominator:", dinominator)
b0= numerator/float(dinominator)
b1=np.mean(y)/float(np.mean(x))
return b1,b0
def predict(x,b0,b1):
return b0+x*b1
x=[1,3,2,1,3]
y = [14,24,18,17,27]
b0,b1=fitslr(x,y)
print(b0,b1)
x_test = 6
y_test = predict(x_test,b0,b1)
print(y_test)
多元回归模型
区别:不仅仅只有一个变量,有多个变量。
多元回归模型:

多元回归方程
对多元模型两边求期望,常数的期望是零得到多元回归方程。
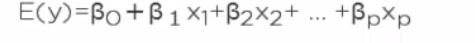
估计流程

估计方法
使估计值最小:
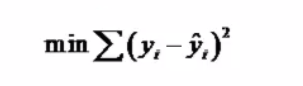
运算和简单的线性回归相似。
例子

import numpy as np
# 机器学习的库,运用其数据集建模,预测
from sklearn import datasets,linear_model
# 创建一个数据集,将数据导入进去(r表示对待后面的所有路径为字符串。)
dataPath = r"D:\python\pythonProject1\Delivery.csv"
# genfromtxt()文本文件,第一个参数是文件路径,第二个是分隔符的 csv文档的分隔符是逗号,将其转化为矩阵的格式。
deliverData = genfromtxt(dataPath,delimiter=",")
print("data")
print("deliverData")
#将数据拆成两部分,[:,:-1]从最开始到倒数第二列,[:,-1]所有行,最后一列
X = deliverData[:,:-1]
Y = deliverData[:,-1]
print(X)
print("*****************")
print(Y)
# 线性回归模型,调用线性回归模型,然后用。fit()函数进行建模。
regr = linear_model.LinearRegression()
regr.fit(X,Y)
print("cofficients")
# 打印属性coef_,算出的模型的参数的预测 b0,b1,,,,
print(regr.coef_)
print("intercept")
print(regr.intercept_)
xPred = np.array([102,6]).reshape(-2, 2)
yPred = regr.predict(xPred)
print(yPred)
结果展示:
多元回归中还有分类关系
将每一类型用零一处理,进行转码的分析。
#将导入的数据变成numpy
from numpy import genfromtxt
# 运用numpy函数 矩阵变换的包,
import numpy as np
# 机器学习的库,运用其数据集建模,预测
from sklearn import datasets,linear_model
# 创建一个数据集,将数据导入进去(r表示对待后面的所有路径为字符串。)
dataPath = r"D:\python\pythonProject1\Delivery.csv"
# genfromtxt()文本文件,第一个参数是文件路径,第二个是分隔符的 csv文档的分隔符是逗号,将其转化为矩阵的格式。
deliverData = genfromtxt(dataPath,delimiter=",")
print("data")
print("deliverData")
#将数据拆成两部分,[:,:-1]从最开始到倒数第二列,[:,-1]所有行,最后一列
X = deliverData[:,:-1]
Y = deliverData[:,-1]
print(X)
print("*****************")
print(Y)
# 线性回归模型,调用线性回归模型,然后用。fit()函数进行建模。
regr = linear_model.LinearRegression()
regr.fit(X,Y)
print("cofficients")
# 打印属性coef_,算出的模型的参数的预测 b0,b1,,,,
print(regr.coef_)
# 打印截面值
print("intercept")
print(regr.intercept_)
xPred = np.array([102,1,0,0,6]).reshape(-5, 5)
yPred = regr.predict(xPred)
print("结果:")
print(yPred)
结果展示

非线性回归
逻辑回归
肿瘤的大小和肿瘤的恶心和良性的关系,他们不是线性关系。用线性回归模型不合适,所以看逻辑回归基本模型。
逻辑回归基本模型
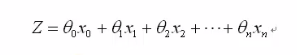
激活函数:
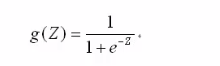
预测函数:
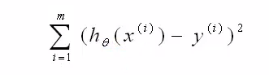
目标结果是求:最小
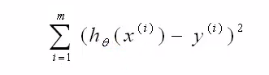
cost函数:
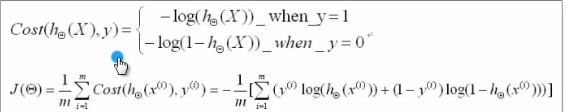
梯度下降:
从梯度上的某点出发,求偏导,找到某个梯度最大的方向,找到梯度的最大点。
最后得到更新法则:
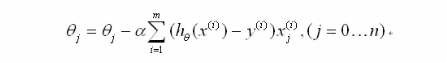
如何实现
# 包的导入
import numpy as np
import random
# 梯度下降函数(x,y)传入的数据值,theta 参数值,alpha学习率;m就是一共多少个实例,numIterations重复更新的次数;梯度下降算法的次数。
def gradientDescent(x,y,theta,alpha,m,numIterations):
# 将数据转置
xTrans = x.transpose()
# 循环次数,
for i in range(0,numIterations):
# x*theta相乘,
hypothesis = np.dot(x,theta)
# 损失值,是预测值减去实际值
loss = hypothesis- y
# 计算cost函数 ,最简单的cost值
cost = np.sum(loss**2)/(2*m)
print("Iteration %d ,cost: %f"%(i,cost))
#求平均值
gradient = np.dot(xTrans,loss)/m
# 迭代更新
theta = theta - alpha*gradient
# 返回值
return theta
# 定义函数创建数据,
# 首先传入三个函数numPoints多少个实例,bias传入偏好,加减 variance方差值
def genData(numPoints,bias,variance):
#声明两个变量,np.zeros生成全是零的矩阵,shape是表示形状,shape=(numPoints,2)numPoint 行数,2,列数
x = np.zeros(shape=(numPoints,2))
y = np.zeros(shape=numPoints)
#创建数据值,对行数进行循环。
for i in range(0,numPoints):
x[i][0] = 1
x[i][1] = i
#random.uniform()随机在()中产生数。
y[i] = (i +bias) +random.uniform(0,1)*variance
return x,y
x,y = genData(100,25,10)
print(x)
print(y)
m,n = np.shape(x)
numIterations = 100000
alpha = 0.0005
# 初始化theta
theta = np.ones(n)
theta = gradientDescent(x,y,theta,alpha,m,numIterations)
print(theta)
回归中的相关度和决定数
皮尔逊相关系数:
衡量两个值的线性相关强度的量,取值在【-1,1】之间,正相关大于零,负相关小于零,无关等于零,
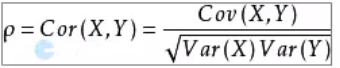
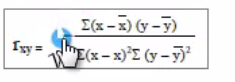
var(x)表示方差,cov(x,y)表示两者的方差。
R平方值
定义:决定系数,反应因变量的全部变异通过回归关系被自变量解释的比例
解释:如果R的平方为0.8,则表示回归关系可以解释为因变量80%的变异。换句话来说,如果能控制自变量不变,则因变量的变异程度会减少80%
简单线性回归
R^2=r*r
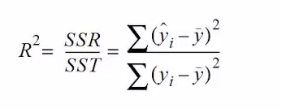















 6008
6008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









