







用决策树预测天气-连续数据篇
前言
在机器学习和数据科学领域,决策树是一种非常强大且易于理解的预测模型。其工作原理类似于人类在面临复杂决策时所采用的逻辑思考过程,通过一系列的问题和条件判断,最终找到问题的答案或决策。由于其直观性和可解释性,决策树在各种应用中都有广泛的应用,从医疗诊断到金融风险评估,再到自然语言处理。
先看图
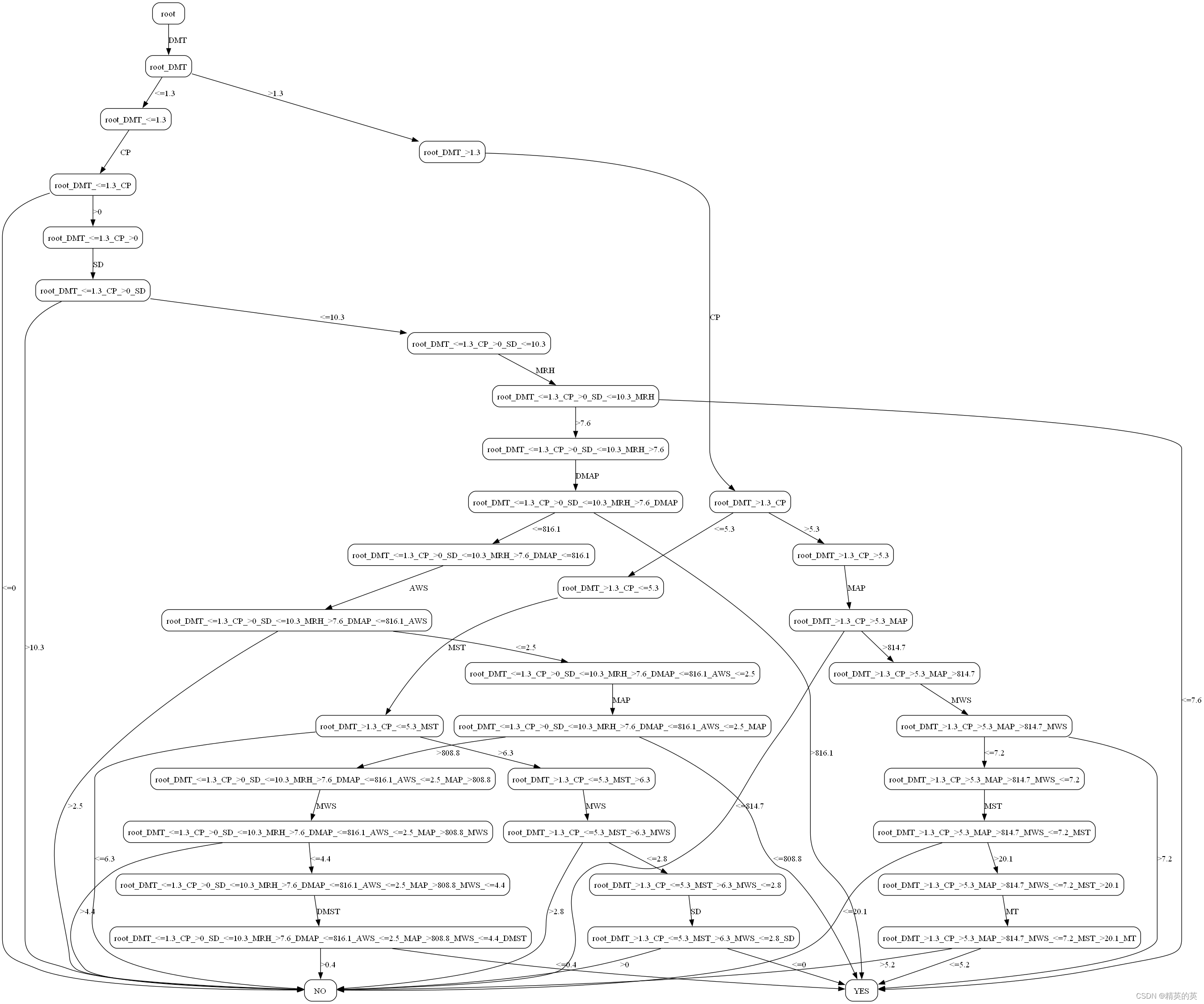
可能有小伙伴一脸懵,上面这一段乱七八糟的是什么,它是本文构建的决策树模型,通过包括 “温度,气压…” 等十几个参数预测在指定条件下,会不会下雪。
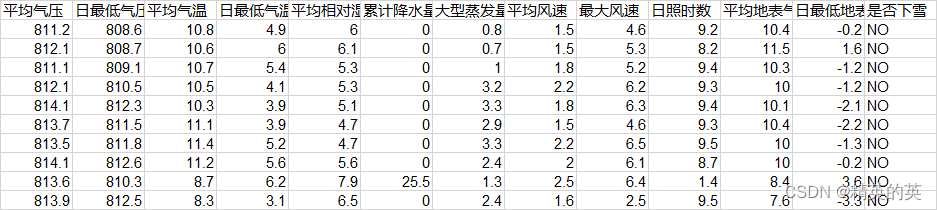
本实验数据集一共4870条数据,记录了十几年某地的天气情况,部分节选如下:
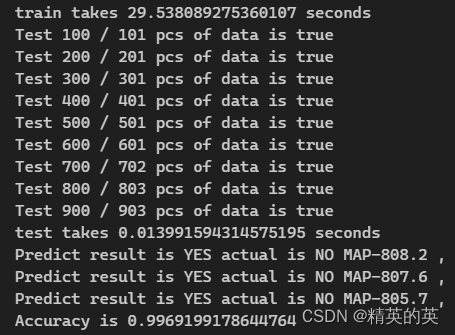
每次实验随机从数据集中挑选80%的数据做训练集,20%的数据做测试集,经过测试,预测准确率超过99%
决策树–连续型数据
在决策树模型中,对于连续性数据,通常的做法是使用二分法(binary split)来处理。具体来说,对于每一个特征,算法会尝试所有可能的二分点,选择信息增益(或者其他评价指标,如基尼指数)最大的那个点作为分割点。
以下是处理连续性数据的基本步骤:
-
排序特征值:首先,将该特征的所有值进行排序。
-
计算所有可能的分割点:然后,计算相邻特征值的中点作为可能的分割点。例如,如果特征值为[1, 2, 3, 4, 5],那么可能的分割点为[1.5, 2.5, 3.5, 4.5]。
-
计算每个分割点的信息增益:对于每一个分割点,将数据集分为两部分,然后计算信息增益(或者其他评价指标)。
-
选择信息增益最大的分割点:最后,选择信息增益最大的分割点作为该特征的分割点。
这样,决策树就可以处理连续性数据了。需要注意的是,这种方法可能会增加决策树构建的计算复杂性,因为需要计算所有可能的分割点。在实际应用中,可能需要使用一些策略来减少计算量,例如,只考虑一部分分割点,或者使用启发式方法来选择分割点。
定义数据集
import numpy as np
import csv
kunming_weather = "J:\\MachineLearning\\数据集\\kunming_weather_continus_data.txt"
def create_dataset(is_test = False):
dataset = []
# 打开CSV文件
with open(kunming_weather, 'r') as file:
reader = csv.reader(file)
# 初始化一个空数组来存储数据
dataset = []
# 遍历每一行数据
for row in reader:
# 将每一行数据转换为数组,并添加到data数组中
dataset.append(row)
np.random.shuffle(dataset) #将数据按行充分打乱
'''
labels = ["MeanAirPressure",
"DailyMinimumAirPressure",
"MeanTempe",
"DailyMinTempe",
"MeanRelativeHumidity",
"CumulativePrecipitation",
"LargeEvaporation",
"AverageWindSpd",
"MaximumWindSpd",
"SunshineDuration",
"MeanSurfaceTempe",
"DailyMinimumSurfaceTempe",
"WhetherItSnows"]
'''
features = ["MAP",
"DMAP",
"MT",
"DMT",
"MRH",
"CP",
"LE",
"AWS",
"MWS",
"SD",
"MST",
"DMST"]
train_count = int(len(dataset) * 0.8)
train_dataset = dataset[1 : train_count]
if (is_test):
test_dataset = dataset[train_count:]
test_source = []
for data in test_dataset:
row_data = {}
for feature_index in range(len(features)):
row_data[features[feature_index]] = data[feature_index]
row_data["result"] = data[-1]
test_source.append(row_data)
return test_source
return train_dataset, features
创建决策树
我们首先找到最佳的特征和对应的分割点,然后根据这个分割点将数据集分为两部分。然后,我们递归地对每一部分数据集调用 create_tree 函数。
注意,我们使用了字符串 f'<={best_split_point}' 和 f'>{best_split_point}' 来作为决策树的分支标签。这样,我们就可以在决策树中明确地表示出分割点。
def create_tree(dataset, feature_labels):
# 提取数据集中所有样本的类别标签
class_list = [example[-1] for example in dataset]
# 如果所有样本的类别标签都相同,那么返回这个类别标签
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
# 如果数据集中只剩下类别标签,那么返回出现次数最多的类别标签
if len(dataset[0]) == 1:
return majority_cnt(class_list)
# 选择最佳的特征和对应的分割点
best_feature, best_split_point = choose_best_feature_to_split(dataset)
# 获取最佳特征的标签
best_feature_label = feature_labels[best_feature]
# 创建一个字典来表示决策树
my_tree = {best_feature_label: {}}
# 从标签列表中删除已经使用的特征标签
feature_labels.pop(best_feature)
# 根据最佳特征的分割点将数据集分为两部分,并从数据集中删除已经使用的特征
sub_dataset1 = [example[:best_feature] + example[best_feature+1:] for example in dataset if example[best_feature] <= best_split_point]
sub_dataset2 = [example[:best_feature] + example[best_feature+1:] for example in dataset if example[best_feature] > best_split_point]
# 递归地对每一部分数据集调用 create_tree 函数
my_tree[best_feature_label][f'<={best_split_point}'] = create_tree(sub_dataset1, feature_labels[:])
my_tree[best_feature_label][f'>{best_split_point}'] = create_tree(sub_dataset2, feature_labels[:])
# 返回决策树
return my_tree
当特征时最后一个,且子节点分类并不唯一,选取数量较多的那一类返回
选取当前特征对应的样本中,出现次数最多的可能
import operator
def majority_cnt(class_list):
class_count = {}
for vote in class_list:
if vote not in class_count.keys():
class_count[vote] = 0 #创建节点,值置为0
class_count[vote] += 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
计算当前决策树的熵值
信息增益比是决策树算法中的一个重要概念,它是用来选择最优划分属性的一种方法。信息增益比的计算流程可以分为以下几个步骤:
-
计算数据集的原始信息熵:信息熵是度量数据集混乱程度的一个指标。在决策树中,我们首先需要计算出整个数据集的信息熵。这个过程通常是通过统计数据集中每个类别的样本数量,然后计算出每个类别的概率,最后将这些概率代入信息熵的公式进行计算。
-
计算每个属性划分后的信息熵:接下来,我们需要计算出每个属性划分后的信息熵。这个过程通常是通过将数据集按照每个属性的不同取值进行划分,然后分别计算出每个子集的信息熵,最后将这些信息熵按照每个子集的样本数量权重进行加权平均。
-
计算每个属性的信息增益:信息增益是指数据集在某个属性划分后的信息熵减去原始信息熵。我们需要计算出每个属性的信息增益,这个过程通常是通过将每个属性划分后的信息熵减去原始信息熵进行计算。
-
计算每个属性的分裂信息值:分裂信息值是度量属性划分样本集合的一个指标。我们需要计算出每个属性的分裂信息值,这个过程通常是通过统计每个属性的不同取值的样本数量,然后计算出每个取值的概率,最后将这些概率代入分裂信息值的公式进行计算。
-
计算每个属性的信息增益比:信息增益比是指信息增益除以分裂信息值。我们需要计算出每个属性的信息增益比,这个过程通常是通过将每个属性的信息增益除以其分裂信息值进行计算。
-
选择信息增益比最大的属性作为最优划分属性:最后,我们需要选择出信息增益比最大的属性作为最优划分属性。这个过程通常是通过比较所有属性的信息增益比,然后选择出信息增益比最大的属性。
信息增益比 (Gain Ratio):
Gain Ratio = Information Gain Split Information \text{Gain Ratio} = \frac{\text{Information Gain}}{\text{Split Information}} Gain Ratio=Split InformationInformation Gain
其中,
信息增益 (Information Gain):
Information Gain = Entropy(Parent) − ∑ ( Number of samples in child Number of samples in parent ∗ Entropy(Child) ) \text{Information Gain} = \text{Entropy(Parent)} - \sum \left(\frac{\text{Number of samples in child}}{\text{Number of samples in parent}} * \text{Entropy(Child)}\right) Information Gain=Entropy(Parent)−∑(Number of samples in parentNumber of samples in child∗Entropy(Child))
分裂信息 (Split Information):
Split Information = − ∑ ( Number of samples in child Number of samples in parent ∗ log 2 ( Number of samples in child Number of samples in parent ) ) \text{Split Information} = - \sum \left(\frac{\text{Number of samples in child}}{\text{Number of samples in parent}} * \log_2 \left(\frac{\text{Number of samples in child}}{\text{Number of samples in parent}}\right)\right) Split Information=−∑(Number of samples in parentNumber of samples in child∗log2(Number of samples in parentNumber of samples in child))
熵 (Entropy):
Entropy = − ∑ ( P i ∗ log 2 ( P i ) ) \text{Entropy} = - \sum (P_i * \log_2(P_i)) Entropy=−∑(Pi∗log2(Pi))
其中, P i P_i Pi 是第 i i i 类样本在总样本中的比例。
from math import log
def calcEnt(dataset):
num_examples = len(dataset) # 计算数据集中的样本数量
label_counts = {} # 创建一个字典,用来存储每个标签的数量
# 遍历数据集中的每个样本
for feature in dataset:
current_label = feature[-1] # 获取样本的标签,假设标签是样本的最后一个特征
# 如果当前标签不在字典中,就在字典中添加这个标签,并设置数量为0
if (current_label not in label_counts.keys()):
label_counts[current_label] = 0
# 将当前标签的数量加1
label_counts[current_label] += 1
ret_ent = 0 # 初始化熵为0
# 遍历每个标签
for key in label_counts:
prop = float(label_counts[key] / num_examples) # 计算当前标签的概率
# 根据熵的公式,计算并累加每个标签的熵
ret_ent += - (prop * log(prop, 2))
return ret_ent # 返回数据集的熵
删掉已经被选作特征的数据集部分
def remove_feature_from_dataset(dataset, axis, val):
ret_dataset = []
for feature in dataset:
if (feature[axis] == val):
reduced_feature = feature[:axis] #取当前列前面的列
#np.concatenate((reduced_feature, feature[axis+1:]), axis=0)
reduced_feature.extend(feature[axis+1:]) #连接当前列后面的列
ret_dataset.append(reduced_feature)
return ret_dataset
选取最佳特征
def choose_best_feature_to_split(dataset):
num_features = len(dataset[0]) - 1 #特征数量(减去标签列)
base_entropy = calcEnt(dataset) #数据集的初始熵
best_info_gain = 0 #初始信息增益比为0
best_feature = -1
best_split_point = None
for i in range(num_features):
feature_list = [example[i] for example in dataset] #取当前特征对应的所有的样本值
unique_vals = set(feature_list) #取当前特征对应的所有可能样本
for split_point in unique_vals:
new_entropy = 0
sub_dataset1 = [example for example in dataset if example[i] <= split_point]
sub_dataset2 = [example for example in dataset if example[i] > split_point]
prob1 = len(sub_dataset1) / float(len(dataset))
new_entropy += prob1 * calcEnt(sub_dataset1)
prob2 = len(sub_dataset2) / float(len(dataset))
new_entropy += prob2 * calcEnt(sub_dataset2)
info_gain = base_entropy - new_entropy #信息增益
if (info_gain > best_info_gain): # base_entropy - new_entropy > base_entropy
best_info_gain = info_gain
best_feature = i
best_split_point = split_point
return best_feature, best_split_point
可视化展示
from graphviz import Digraph
def visualize_decision_tree(tree, name="DecisionTree"):
def add_edges(graph, subtree, parent_node):
for key, value in subtree.items():
if isinstance(value, dict):
sub_node = f"{parent_node}_{str(key)}" # 将key转换为字符串
graph.edge(parent_node, sub_node, label=str(key)) # 将label转换为字符串
add_edges(graph, value, sub_node)
else:
graph.edge(parent_node, str(value), label=str(key)) # 将value和label转换为字符串
graph = Digraph(name=name, format="png")
graph.attr('node', shape='Mrecord')
add_edges(graph, tree, "root")
return graph
预测
def predict(input_tree, test_vec, feature_labels):
# 获取决策树的第一个节点
first_str = list(input_tree.keys())[0]
# 获取第一个节点的子树
second_dict = input_tree[first_str]
# 获取第一个节点对应的特征在特征标签列表中的索引
feature_index = feature_labels.index(first_str)
# 遍历第一个节点的所有子节点
for key in second_dict.keys():
# 如果子节点的标签表示的是一个“<=”的条件
if key[0] == '<':
# 获取条件中的值
value = float(key[2:])
# 如果测试向量中对应的特征值满足这个条件
if test_vec[feature_index] <= value:
# 如果子节点是一个字典,那么递归地调用 predict 函数
if type(second_dict[key]).__name__ == 'dict':
class_label = predict(second_dict[key], test_vec, feature_labels)
# 否则,子节点就是一个类别标签,直接返回这个标签
else:
class_label = second_dict[key]
# 如果子节点的标签表示的是一个“>”的条件
if key[0] == '>':
# 获取条件中的值
value = float(key[1:])
# 如果测试向量中对应的特征值满足这个条件
if test_vec[feature_index] > value:
# 如果子节点是一个字典,那么递归地调用 predict 函数
if type(second_dict[key]).__name__ == 'dict':
class_label = predict(second_dict[key], test_vec, feature_labels)
# 否则,子节点就是一个类别标签,直接返回这个标签
else:
class_label = second_dict[key]
# 返回预测的类别标签
return class_label
训练和验证
import json
if (__name__ == "__main__"):
dataset, label = create_dataset()
test_source = create_dataset(True)
feature_labels = label.copy()
my_tree = create_tree(dataset, label)
test_tree = my_tree
predict_true_count = 0
predict_count = 0
fail_info_array = []
for test_item in test_source:
predict_count += 1
predict_result = predict(test_tree, test_item, feature_labels)
if (predict_result == test_item["result"]):
predict_true_count += 1
if (predict_true_count % 100 == 0):
print("Test {} / {} pcs of data is true".format(predict_true_count, predict_count))
else:
fail_info = ""
for key, value in test_item.items():
fail_info += "{} : {} , ".format(key, value)
fail_info = "Predict result is {} actual is {} ".format(predict_result, test_item["result"]) + fail_info
fail_info_array.append(fail_info)
print(fail_info_array)
print("Accuracy is {}".format(predict_true_count / len(test_source)))
with open('data.json', 'w') as file:
json.dump(my_tree, file)
# 可视化决策树
graph = visualize_decision_tree(my_tree)
graph.view() # 这将在默认的图片查看器中显示决策树图像
完整代码(数据集在绑定的资源里,想尝试的去下载吧)
import numpy as np
import csv
import time
kunming_weather = "J:\\MachineLearning\\数据集\\kunming_weather_continus_data.txt"
def create_dataset(is_test = False):
dataset = []
# 打开CSV文件
with open(kunming_weather, 'r') as file:
reader = csv.reader(file)
# 初始化一个空数组来存储数据
dataset = []
# 遍历每一行数据
for row in reader:
# 将每一行数据转换为数组,并添加到data数组中
dataset.append(row)
np.random.shuffle(dataset) #将数据按行充分打乱
'''
labels = ["MeanAirPressure",
"DailyMinimumAirPressure",
"MeanTempe",
"DailyMinTempe",
"MeanRelativeHumidity",
"CumulativePrecipitation",
"LargeEvaporation",
"AverageWindSpd",
"MaximumWindSpd",
"SunshineDuration",
"MeanSurfaceTempe",
"DailyMinimumSurfaceTempe",
"WhetherItSnows"]
'''
features = ["MAP",
"DMAP",
"MT",
"DMT",
"MRH",
"CP",
"LE",
"AWS",
"MWS",
"SD",
"MST",
"DMST"]
train_count = int(len(dataset) * 0.8)
train_dataset = dataset[1 : train_count]
if (is_test):
test_dataset = dataset[train_count:]
test_source = []
for data in test_dataset:
row_data = {}
for feature_index in range(len(features)):
row_data[features[feature_index]] = data[feature_index]
row_data["result"] = data[-1]
test_source.append(row_data)
return test_source
return train_dataset, features
import operator
def majority_cnt(class_list):
class_count = {}
for vote in class_list:
if vote not in class_count.keys():
class_count[vote] = 0 #创建节点,值置为0
class_count[vote] += 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
from math import log
def calcEnt(dataset):
num_examples = len(dataset) # 计算数据集中的样本数量
label_counts = {} # 创建一个字典,用来存储每个标签的数量
# 遍历数据集中的每个样本
for feature in dataset:
current_label = feature[-1] # 获取样本的标签,假设标签是样本的最后一个特征
# 如果当前标签不在字典中,就在字典中添加这个标签,并设置数量为0
if (current_label not in label_counts.keys()):
label_counts[current_label] = 0
# 将当前标签的数量加1
label_counts[current_label] += 1
ret_ent = 0 # 初始化熵为0
# 遍历每个标签
for key in label_counts:
prop = float(label_counts[key] / num_examples) # 计算当前标签的概率
# 根据熵的公式,计算并累加每个标签的熵
ret_ent += - (prop * log(prop, 2))
return ret_ent # 返回数据集的熵
def remove_feature_from_dataset(dataset, axis, val):
ret_dataset = []
for feature in dataset:
if (feature[axis] == val):
reduced_feature = feature[:axis] #取当前列前面的列
#np.concatenate((reduced_feature, feature[axis+1:]), axis=0)
reduced_feature.extend(feature[axis+1:]) #连接当前列后面的列
ret_dataset.append(reduced_feature)
return ret_dataset
def choose_best_feature_to_split(dataset):
num_features = len(dataset[0]) - 1 #特征数量(减去标签列)
base_entropy = calcEnt(dataset) #数据集的初始熵
best_info_gain = 0 #初始信息增益比为0
best_feature = -1
best_split_point = None
for i in range(num_features):
feature_list = [example[i] for example in dataset] #取当前特征对应的所有的样本值
#feature_list = np.array([float(example[i]) for example in dataset]) #取当前特征对应的所有的样本值
unique_vals = set(feature_list) #取当前特征对应的所有可能样本
#unique_vals = np.quantile(feature_list, [0.25, 0.5, 0.75])
for split_point in unique_vals:
new_entropy = 0
sub_dataset1 = [example for example in dataset if example[i] <= split_point]
sub_dataset2 = [example for example in dataset if example[i] > split_point]
prob1 = len(sub_dataset1) / float(len(dataset))
new_entropy += prob1 * calcEnt(sub_dataset1)
prob2 = len(sub_dataset2) / float(len(dataset))
new_entropy += prob2 * calcEnt(sub_dataset2)
info_gain = base_entropy - new_entropy #信息增益
if (info_gain > best_info_gain): # base_entropy - new_entropy > base_entropy
best_info_gain = info_gain
best_feature = i
best_split_point = split_point
return best_feature, best_split_point
def create_tree(dataset, feature_labels):
# 提取数据集中所有样本的类别标签
class_list = [example[-1] for example in dataset]
# 如果所有样本的类别标签都相同,那么返回这个类别标签
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
# 如果数据集中只剩下类别标签,那么返回出现次数最多的类别标签
if len(dataset[0]) == 1:
return majority_cnt(class_list)
# 选择最佳的特征和对应的分割点
best_feature, best_split_point = choose_best_feature_to_split(dataset)
# 获取最佳特征的标签
best_feature_label = feature_labels[best_feature]
# 创建一个字典来表示决策树
my_tree = {best_feature_label: {}}
# 从标签列表中删除已经使用的特征标签
feature_labels.pop(best_feature)
# 根据最佳特征的分割点将数据集分为两部分,并从数据集中删除已经使用的特征
sub_dataset1 = [example[:best_feature] + example[best_feature+1:] for example in dataset if example[best_feature] <= best_split_point]
sub_dataset2 = [example[:best_feature] + example[best_feature+1:] for example in dataset if example[best_feature] > best_split_point]
# 递归地对每一部分数据集调用 create_tree 函数
my_tree[best_feature_label][f'<={best_split_point}'] = create_tree(sub_dataset1, feature_labels[:])
my_tree[best_feature_label][f'>{best_split_point}'] = create_tree(sub_dataset2, feature_labels[:])
# 返回决策树
return my_tree
from graphviz import Digraph
def visualize_decision_tree(tree, name="DecisionTree"):
def add_edges(graph, subtree, parent_node):
for key, value in subtree.items():
if isinstance(value, dict):
sub_node = f"{parent_node}_{str(key)}" # 将key转换为字符串
graph.edge(parent_node, sub_node, label=str(key)) # 将label转换为字符串
add_edges(graph, value, sub_node)
else:
graph.edge(parent_node, str(value), label=str(key)) # 将value和label转换为字符串
graph = Digraph(name=name, format="png")
graph.attr('node', shape='Mrecord')
add_edges(graph, tree, "root")
return graph
def predict(input_tree, test_vec, feature_labels):
# 获取决策树的第一个节点
first_str = list(input_tree.keys())[0]
# 获取第一个节点的子树
second_dict = input_tree[first_str]
# 获取第一个节点对应的特征在特征标签列表中的索引
#feature_index = feature_labels.index(first_str)
feature_index = first_str
# 遍历第一个节点的所有子节点
for key in second_dict.keys():
# 如果子节点的标签表示的是一个“<=”的条件
if key[0] == '<':
# 获取条件中的值
value = float(key[2:])
# 如果测试向量中对应的特征值满足这个条件
if float(test_vec[feature_index]) <= value:
# 如果子节点是一个字典,那么递归地调用 predict 函数
if type(second_dict[key]).__name__ == 'dict':
class_label = predict(second_dict[key], test_vec, feature_labels)
# 否则,子节点就是一个类别标签,直接返回这个标签
else:
class_label = second_dict[key]
# 如果子节点的标签表示的是一个“>”的条件
if key[0] == '>':
# 获取条件中的值
value = float(key[1:])
# 如果测试向量中对应的特征值满足这个条件
if float(test_vec[feature_index]) > value:
# 如果子节点是一个字典,那么递归地调用 predict 函数
if type(second_dict[key]).__name__ == 'dict':
class_label = predict(second_dict[key], test_vec, feature_labels)
# 否则,子节点就是一个类别标签,直接返回这个标签
else:
class_label = second_dict[key]
# 返回预测的类别标签
return class_label
import json
if (__name__ == "__main__"):
dataset, label = create_dataset()
test_source = create_dataset(True)
feature_labels = label.copy()
train_start_time = time.time()
my_tree = create_tree(dataset, label)
train_end_time = time.time()
elapsed_time = train_end_time - train_start_time
print ("train takes {} seconds".format(elapsed_time))
test_tree = my_tree
predict_true_count = 0
predict_count = 0
fail_info_array = []
test_start_time = time.time()
for test_item in test_source:
predict_count += 1
predict_result = predict(test_tree, test_item, feature_labels)
fail_info = ''
if (predict_result == test_item["result"]):
predict_true_count += 1
if (predict_true_count % 100 == 0):
print("Test {} / {} pcs of data is true".format(predict_true_count, predict_count))
else:
for key, value in test_item.items():
fail_info += "{}-{} , ".format(key, value)
fail_info_array.append( "Predict result is {} actual is {} ".format(predict_result, test_item["result"]) + fail_info)
test_end_time = time.time()
elapsed_test_time = test_end_time - test_start_time
print ("test takes {} seconds".format(elapsed_test_time))
for info in fail_info_array:
print(info)
print("Accuracy is {}".format(predict_true_count / len(test_source)))
with open('data.json', 'w') as file:
json.dump(my_tree, file)
# 可视化决策树
graph = visualize_decision_tree(my_tree)
graph.view() # 这将在默认的图片查看器中显示决策树图像


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









