






1 什么是决策树
决策树(Decision Tree)是一种基本的分类与回归方法,本文主要讨论分类决策树。决策树模型呈树形结构,在分类问题中,表示基于特征对数据进行分类的过程。它可以认为是if-then规则的集合。每个内部节点表示在属性上的一个测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
决策树的优点:
1)可以自学习。在学习过程中不需要使用者了解过多的背景知识,只需要对训练数据进行较好的标注,就能进行学习。
2)决策树模型可读性好,具有描述性,有助于人工分析;
3)效率高,决策树只需要一次构建,就可以反复使用,每一次预测的最大计算次数不超过决策树的深度。
2.构建决策树的基本步骤
决策树构建的基本步骤如下:
-
开始,所有记录看作一个节点
-
遍历每个特征的每一种分裂方式,找到最好的分裂特征(分裂点)
-
分裂成两个或多个节点
-
对分裂后的节点分别继续执行2-3步,直到每个节点足够“纯”为止
如何评估分裂点的好坏?如果一个分裂点可以将当前的所有节点分为两类,使得每一类都很“纯”,也就是同一类的记录较多,那么就是一个好分裂点。
具体实践中,到底选择哪个特征作为当前分裂特征,常用的有下面三种算法:
ID3:使用信息增益g(D,A)进行特征选择
C4.5:信息增益率 =g(D,A)/H(A)
CART:基尼系数
一个特征的信息增益(或信息增益率,或基尼系数)越大,表明特征对样本的熵的减少能力更强,这个特征使得数据由不确定性到确定性的能力越强。
3.代码引例包括构造
import operator
from math import log
#计算信息熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob*log(prob, 2)
return shannonEnt
#按照给定特征划分数据集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
#构造决策树
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), \
key=lambda item:item[1], reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del labels[bestFeat]
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree4最优特征选择方法在ID3算法中使用了信息增益来选择特征,信息增益大的优先选择。
在C4.5算法中采用了信息增益比来选择特征,以减少信息增益容易选择特征值多的特征的问题。但是无论ID3还是C4.5,都是基于信息论的熵模型的,这里面会涉及大量的对数运算,
CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益(比)是相反的。在分类问题中,假设有K个类别,第k个类别的概率为pk, 则基尼系数的表达式为:
4最优特征选择方法在ID3算法中使用了信息增益来选择特征,信息增益大的优先选择。
在C4.5算法中采用了信息增益比来选择特征,以减少信息增益容易选择特征值多的特征的问题。但是无论ID3还是C4.5,都是基于信息论的熵模型的,这里面会涉及大量的对数运算,
CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益(比)是相反的。在分类问题中,假设有K个类别,第k个类别的概率为pk, 则基尼系数的表达式为:
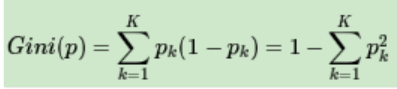
若是二类分类问题,计算就更简单了,如果属于第一个样本输出的概率是p,则基尼系数的表达式为:
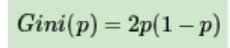
对于给定样本D,假设有K个类别, 第k个类别的数量为Ck,则样本D的基尼系数表达式为:

5. 剪枝
通过剪枝,可以有效防止决策树模型过拟合的问题。主要有一下两种剪枝方法:
预剪枝
后剪枝
1 预剪枝
在决策树生成过程中,对每个节点先进行估计,若当前及诶单的划分不能使决策树的泛化性能提升,则停止划分。
.2 后剪枝
对一个完整的决策树,从底向上对非叶子节点进行分析,若将该子树替换为叶子结点能够提升决策树的泛化能力,则将该子树替换为叶子节点。















 4782
4782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









