







决策树
决策树是基于树结构来进行决策的,一棵决策树包含一个根节点,若干个内部节点和若干个叶子节点。叶子节点对应于决策结果,其他节点则对应于一个属性测试;每个节点包含的样本集合根据属性测试的结果被划分到子结点中;根节点包含样本全集。从根节点到每个叶子结点的路劲对应了一个判定测试序列。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。
基本流程:

情形一:当前节点包含的样本全属于同一个类别,无需进行划分
情形二:当前属性集为空,或是所有的样本在所有属性上取值相同,无需划分 (将当前节点标记为叶节点,并将其类别设置为该节点所含样本最多的类别)
情形三:当前结点包含的样本集合为空,不能划分 (将当前节点标记为叶节点,并将其类别设置为其父节点所含样本最多的类别)
划分
关于 纯度:即分支节点中所包含的样本尽可能的属于同一个类别
信息增益
1、信息熵:
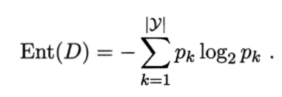
p k p_k pk表示在当前样本集合D中第k类样本所占的比例 约定:若p等于0 则 p l o g 2 p = 0 plog_2p = 0 plog2p=0
Ent(D)的值越小,则D的纯度越高。推导:



信息增益:对数据集D使用属性a进行划分得到
D
v
D^v
Dv 计算得到
E
n
t
(
D
v
)
Ent(D^v)
Ent(Dv) ,再根据不同的分支节点所包含的样本数的不同,给每个分支节点赋予一定权重
∣
D
v
∣
/
∣
D
∣
|D^v|/|D|
∣Dv∣/∣D∣ 表示样本数越多的分支结点所产生的影响越大 。信息增益的公式入下:

结论:信息增益越大,则意味着使用属性a进行划分所获得的“纯度”越高
可以简单理解为 D v D^v Dv对D的影响程度,使用总的信息熵减去属性a对应的信息熵,如果得到的值越大,说明使用属性a进行划分对总信息熵的影响越小,说明在知道取值后样本集的不确定性减小的程度越大。
增益率:
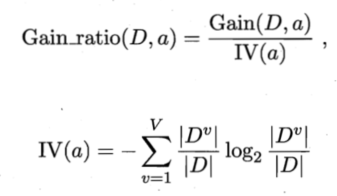
注意:增益律准则对可取值数目较少的属性有所偏好
基尼指数:(CRAT决策树 可用于分类和回归)

基尼指数反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,基尼指数越小,数据集D的纯度越高
属性a对应的基尼指数定义:

在候选属性集合A中,选择基尼指数最小的属性作为划分属性 a ∗ = a r g m i n G i n i _ i n d e x ( D , a ) a ∈ A a_* = argmin Gini\_index(D,a) a \in A a∗=argminGini_index(D,a)a∈A
CART分类树的构造:
1、首先,对每个属性 a的每个可能取值 v,将数据集 D分为 a = v和 a ̸= v两部分来计算基尼指数,
即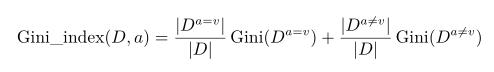
2、然后,选择基尼指数最小的属性及其对应取值作为最优划分属性和最优划分点;
3、最后,重复以上两步,直至满足停止条件。
剪枝处理
预剪枝:在决策树生成过程中,对每个结点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能的提升,则停止划分并将当前节点标记为叶节点
预剪枝不仅降低了过拟合的风险,还显著减少了决策树的训练时间的开销和测试时间开销,但是预剪枝是基于“贪心”策略,有欠拟合的风险
后剪枝:先从训练集生成一棵决策树,然后自底向上地对非叶结点进行考察,若将该节点对应的子数替换为叶节点能带来决策树泛化性能的提升,则将该子树替换为叶节点
后剪枝的欠拟合的风险很小,泛化性能往往优于预剪枝决策树,但后剪枝过程是在生成完全决策树之后进行的,并且需要自底向上地对树中的所有非叶结点进行逐一考察,因此训练时间比未剪枝的决策树和预剪枝决策树都要大很多
连续与缺失值
连续值处理
连续离散化技术,最简单的就是二分法
例如给定样本集D和连续属性a,假定 a 在D上出现了n个不同的取值,将其从小到大排序后,记为 { a 1 , a 2 , . . . , a n } \{a^1,a^2,...,a^n\} {a1,a2,...,an} 基于划分点t可将D划分为子集 D t − , D t + D_t^- , D_t^+ Dt−,Dt+ 其中 D t − D_t^- Dt− 包含那些在属性a上取值不大于t的样本 , D t + D_t^+ Dt+ 表示在属性a上大于t的样本。取划分点集合: T a = { a i + a i + 1 2 ∣ 1 < = i < = n − 1 } T_a = \{\frac{a^i+a^{i+1}}{2} | 1<=i<=n-1\} Ta={2ai+ai+1∣1<=i<=n−1}
得到基于最有划分点的信息增益:

缺失值处理
定义训练集D和属性a 令 D ~ \widetilde{D} D 表示D中在属性a 上没有缺失值的样本子集
设属性a 有V个可取值 { a 1 , a 2 , . . . , a V } \{a^1,a^2,...,a^V\} {a1,a2,...,aV} ,
令 D v ~ \widetilde{D^v} Dv 表示 D ~ \widetilde{D} D 中在属性a上取值为 a v a^v av 的样本子集 ,
D k ~ \widetilde{D_k} Dk 表示 D ~ \widetilde{D} D 中属于第k类 ( k = 1 , 2 , . . . , ∣ y ∣ ) (k = 1,2,...,|y|) (k=1,2,...,∣y∣)的样本子集
D ~ = ⋃ k = 1 ∣ y ∣ D k ~ \widetilde{D} = \bigcup_{k=1}^{|y|} \widetilde{D_k} D =⋃k=1∣y∣Dk D ~ = ⋃ v = 1 V D v ~ \widetilde{D} = \bigcup_{v=1}^V \widetilde{D^v} D =⋃v=1VDv 假定为每一个样本x赋予一个权重 w x w_x wx 并定义:

故对于属性a, ρ \rho ρ 表示无缺失值样本所占的比例 ,
p k ~ \tilde{p_k} pk~ 表示无缺失值样本中第k类所占的比例,
r ~ v \tilde{r}_v r~v 表示无缺失值样本中在属性a上取值为 a v a^v av 的样本所占的比例
∑ k = 1 ∣ y ∣ p ~ k = 1 \sum_{k=1}^{|y|} \tilde{p}_k = 1 ∑k=1∣y∣p~k=1 ∑ v = 1 V r ~ v = 1 \sum_{v=1}^V \tilde{r}_v = 1 ∑v=1Vr~v=1
此时的信息增益推导式:
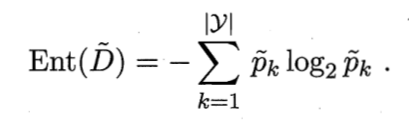

若样本x 在划分属性a上的取值已知,则将x 划入预期值对应的子节点,且样本权值在子节点中保持为 w x w_x wx
若样本x 在划分属性a上的取值未知,则将x 同时划入所有子节点,且样本均值在在与属性值 a v a^v av 对应的子结点中调整为 r ~ v ∗ w x \tilde{r}_v * w_x r~v∗wx
多变量决策树
样本分类:将d个属性描述的样本对应到d维空间中的一个数据点,样本分类就是在这个d维空间中寻找不同类样本之间的分类边界
在多变量决策树中,非叶节点不再是仅对某个属性,而是对属性的线性组合进行测试
每个非叶节点是一个形如: ∑ i = 1 d w i a i = t \sum_{i=1}^d w_i a_i =t ∑i=1dwiai=t 的线性分类器,其中 w i w_i wi 是属性 a i a_i ai的权重, w i w_i wi 和t可在改结点所含的样本集和属性集上学得。
主要算法:OC1 先贪婪的寻找每个属性的最有权值,在局部优化的基础上再对分类边界进行随机扰动以试图找到更好的边界
决策树实现代码
import operator
from math import log
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
def createDataSet():
dataSet = [['青绿','蜷缩','浊响','清晰','凹陷','硬滑','是'],
['乌黑','蜷缩','沉闷','清晰','凹陷','硬滑','是'],
['乌黑','蜷缩','浊响','清晰','凹陷','硬滑','是'],
['青绿','蜷缩','沉闷','清晰','凹陷','硬滑','是'],
['浅白','蜷缩','浊响','清晰','凹陷','硬滑','是'],
['青绿','稍蜷','浊响','清晰','稍凹','软粘','是'],
['乌黑','稍蜷','浊响','稍糊','稍凹','软粘','是'],
['乌黑','稍蜷','浊响','清晰','稍凹','硬滑','是'],
['乌黑','稍蜷','沉闷','稍糊','稍凹','硬滑','否'],
['青绿','硬挺','清脆','清晰','平坦','软粘','否'],
['浅白','硬挺','清脆','模糊','平坦','硬滑','否'],
['浅白','蜷缩','浊响','模糊','平坦','软粘','否'],
['青绿','稍蜷','浊响','稍糊','凹陷','硬滑','否'],
['浅白','稍蜷','沉闷','稍糊','凹陷','硬滑','否'],
['乌黑','稍蜷','浊响','清晰','稍凹','软粘','否'],
['浅白','蜷缩','浊响','模糊','平坦','硬滑','否'],
['青绿','蜷缩','沉闷','稍糊','稍凹','硬滑','否']]
labels = ['色泽','根蒂','敲声','纹理','脐部','触感',] #特征标签
return dataSet, labels
#计算信息熵
def computer_Ent(dataSet):
row_num = len(dataSet)
labelCounts = {}
for row in dataSet:
current_label= row[-1]
if current_label not in labelCounts.keys():
labelCounts[current_label] = 0
labelCounts[current_label]+=1
Ent = 0.0
for key in labelCounts:
p = float(labelCounts[key])/row_num
Ent -= p * log(p,2)
return Ent
# 划分数据集 即在选定特征后将特征列删除
def split_dataSet(dataSet, axis, value):
final_dataSet = []
for row in dataSet:
if row[axis] == value:
reduced_row = row[:axis]
reduced_row.extend(row[axis + 1:])
final_dataSet.append(reduced_row)
return final_dataSet
##选择最优特征
def choose_Best_Feature_To_split(dataSet):
feature_num = len(dataSet[0])-1 ##特征数量
Ent = computer_Ent(dataSet) ##计算数据集的信息熵
Gain = 0.0 #信息增益
best_feature_index = -1
for i in range(feature_num):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = split_dataSet(dataSet,i,value)
prob =len(subDataSet) / float(len(dataSet))
newEntropy +=prob * computer_Ent(subDataSet)
infoGain = Ent - newEntropy
if infoGain > Gain:
Gain = infoGain
best_feature_index = i
return best_feature_index
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] +=1
sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels,featLabels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat = choose_Best_Feature_To_split(dataSet)
bestFeatLabel = labels[bestFeat]
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}}
subBiaoqian = labels.copy()
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVales = set(featValues)
for value in uniqueVales:
myTree[bestFeatLabel][value] = createTree(split_dataSet(dataSet,bestFeat,value),subBiaoqian,featLabels)
return myTree
if __name__ == '__main__':
dataSet, labels = createDataSet()
featLabels = []
myTree = createTree(dataSet, labels, featLabels)
print(myTree)
使用sklearn中的决策树
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn import tree
from six import StringIO
import pandas as pd
import numpy as np
import pydotplus
def createDataSet():
dataSet = [['青绿','蜷缩','浊响','清晰','凹陷','硬滑','yes'],
['乌黑','蜷缩','沉闷','清晰','凹陷','硬滑','yes'],
['乌黑','蜷缩','浊响','清晰','凹陷','硬滑','yes'],
['青绿','蜷缩','沉闷','清晰','凹陷','硬滑','yes'],
['浅白','蜷缩','浊响','清晰','凹陷','硬滑','yes'],
['青绿','稍蜷','浊响','清晰','稍凹','软粘','yes'],
['乌黑','稍蜷','浊响','稍糊','稍凹','软粘','yes'],
['乌黑','稍蜷','浊响','清晰','稍凹','硬滑','yes'],
['乌黑','稍蜷','沉闷','稍糊','稍凹','硬滑','no'],
['青绿','硬挺','清脆','清晰','平坦','软粘','no'],
['浅白','硬挺','清脆','模糊','平坦','硬滑','no'],
['浅白','蜷缩','浊响','模糊','平坦','软粘','no'],
['青绿','稍蜷','浊响','稍糊','凹陷','硬滑','no'],
['浅白','稍蜷','沉闷','稍糊','凹陷','硬滑','no'],
['乌黑','稍蜷','浊响','清晰','稍凹','软粘','no'],
['浅白','蜷缩','浊响','模糊','平坦','硬滑','no'],
['青绿','蜷缩','沉闷','稍糊','稍凹','硬滑','no']]
labels = ['seze','gendi','qiaosheng','wenli','qibu','chugan',] #特征标签
return dataSet, labels
if __name__ == '__main__':
lenses,lensesLabels = createDataSet();
lenses_target = [] #提取每组数据的类别,保存在列表里
for each in lenses:
lenses_target.append(each[-1])
print(lenses_target)
lenses_list = [] #保存lenses数据的临时列表
lenses_dict = {} #保存lenses数据的字典,用于生成pandas
for each_label in lensesLabels: #提取信息,生成字典
for each in lenses:
lenses_list.append(each[lensesLabels.index(each_label)])
lenses_dict[each_label] = lenses_list
lenses_list = []
# print(lenses_dict) #打印字典信息
lenses_pd = pd.DataFrame(lenses_dict) #生成pandas.DataFrame
# print(lenses_pd) #打印pandas.DataFrame
le = LabelEncoder() #创建LabelEncoder()对象,用于序列化
for col in lenses_pd.columns: #序列化
lenses_pd[col] = le.fit_transform(lenses_pd[col])
print(lenses_pd) #打印编码信息
clf = tree.DecisionTreeClassifier(max_depth = 4) #创建DecisionTreeClassifier()类
clf = clf.fit(lenses_pd.values.tolist(), lenses_target) #使用数据,构建决策树
dot_data = StringIO()
tree.export_graphviz(clf, out_file = dot_data, #绘制决策树
feature_names = lenses_pd.keys(),
class_names = clf.classes_,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf")
最后结果:

使用决策树预测结果:
print(clf.predict([[1,1,1,1,1,0]]))















 2298
2298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









