







一、Kafka文件存储机制
1. 存储结构
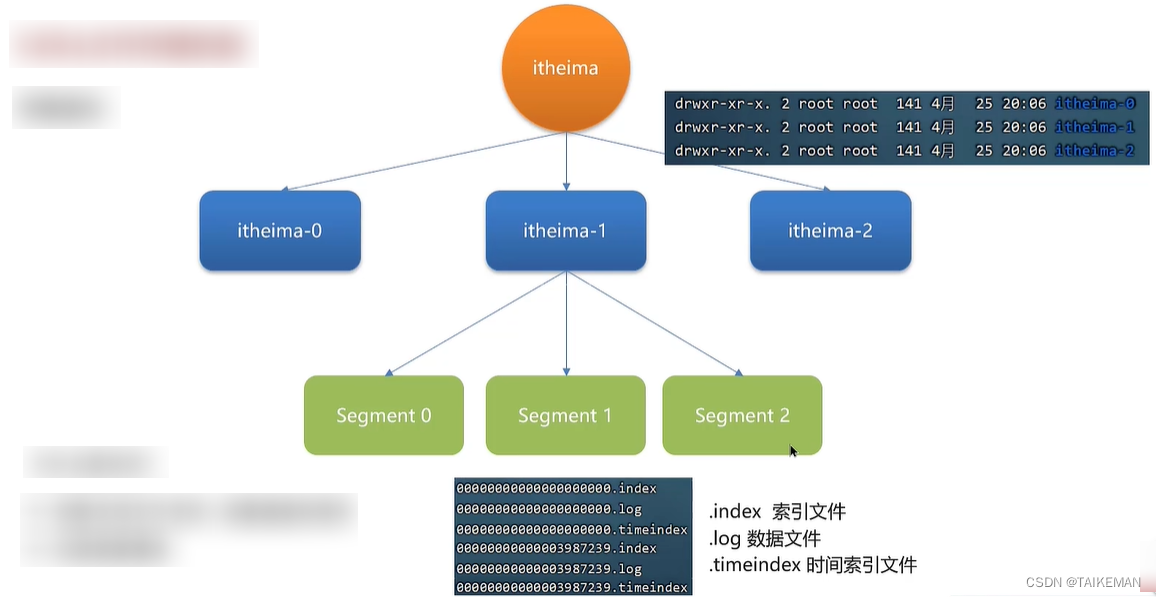
- Kafka生产者通过topic发送数据,topic只是一个逻辑概念,真正存储数据的位置是分区,分区在broker机器上对应的是文件夹(topic名称-分区号)
- 分区内部存储了数据文件,也是分段存储的。在一个分区下可能存在多个日志分区段(segment)
- 每个段都对应了3个文件:.index索引文件、.log真正的数据文件、.timeindex时间索引文件
2. 为什么要分段?
- 删除无用文件(已经被消费过很长时间的文件)更方便,提高磁盘利用率
- 查找数据更便捷:如果消息量很大,全都存储在一个文件中,那么查找速度肯定会受限
- 文件命名都是以偏移量进行命名的:查找数据时,肯定是知道需要查找的偏移量的,此时可以快速定位到某个文件,通过.index索引文件,再去从.log文件中找出具体的数据
二、数据清理机制
1. 根据消息的保留时间

- 根据消息的保留时间,当消息在Kafka中保存的时间超过了指定的时间,就会触发清理过程
- 指定时间可以再broker的配置文件中配置,默认168小时(7天)
- 根据业务情况可以适当调整,一般消息都不会保留超过7天的
2. 根据topic存储的数据大小

- 根据topic存储的数据大小(该topic下所有分区数据的总和),当topic所占的日志文件大小大于一定阈值(1TB),则开始删除最久的消息
- 在broker的配置文件中默认是关闭的,需手动开启
三、小结

四、模拟面试
















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









