






 文章介绍了企业中的数据删除策略,代码格式化快捷键,HTTP请求的设计,安全的登录信息存储,Spring拦截器的应用,ThreadLocal的使用,前缀树的原理与实现,AJAX异步请求,以及事务管理中的ACID特性与隔离级别。还对比了Bootstrap和Vue的区别,以及敏感词过滤和前端开发实践。
文章介绍了企业中的数据删除策略,代码格式化快捷键,HTTP请求的设计,安全的登录信息存储,Spring拦截器的应用,ThreadLocal的使用,前缀树的原理与实现,AJAX异步请求,以及事务管理中的ACID特性与隔离级别。还对比了Bootstrap和Vue的区别,以及敏感词过滤和前端开发实践。
1. 在企业中,删除一般是修改状态,不直接从数据库中物理删除。
2. Ctrl + Alt + L快捷键:格式化代码
3. 请求路径可以相同,但是它们的请求方法必须不同(例如:一个get,一个post)
4. 显示登录信息(不将user数据存在客户端,不安全,而是存在服务端)
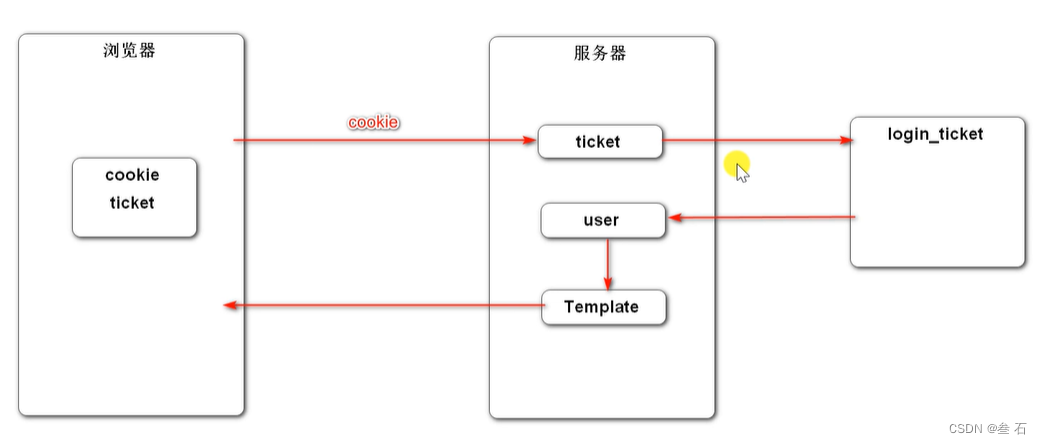
每个请求都会请求得到user的信息,所以配置一个拦截器,在每个请求之前(因为每个请求中都有可能会用到user数据)先加载user数据
ThreadLocal:只要这个请求还没结束,这个线程就一直存在,线程中setUser的user就一直存在(当请求处理完,服务器向浏览器返回响应后线程才销毁),并且和其他线程的user相互隔离。(类似于session的作用)
5. 拦截器解释和实现步骤:Spring 拦截器_spring lanjieqi_大新软件技术部的博客-CSDN博客 拦截器可以有多个,返回为true时继续执行下一个,链式
拦截器不一定都是拦截作用,还可以在preHandle、postHandle和afterCompletion中编写其他逻辑。

6. 前缀树(Trie)(用到了树的结构和算法,可以当做项目难点):空间换时间,
1)根节点没有字符,除了根节点,每个节点都有一个字符
2)从根节点到叶子结点,沿途节点的值拼在一起就是敏感词
3)每个节点的所有子节点中的字符都不相同。
到最末级的节点,才能算是一个敏感词。
因为每个节点的子节点个数不确定,所以用Map<Character, TrieNode>来存储子节点。
7. 新建sensitive-words.txt,点击run之后在target的classes中没有,要在maven中先clean一下再compile就有了。
8. AJAX 异步的JavaScript与XML,我们项目前端页面是由bootstrap做的,是基于jQuery的,所以每一个网页都引入了jQuery,用jQuery发送ajax请求肯定比原生js要好写。

9. 简单的类直接把函数写成static的,用CommunityUtil.md5();调用;复杂一点的类用Spring容器管理,@Component,@Bean
10. bootstrap和vue的区别是什么?
1)Bootstrap是基于HTML、CSS、JS的简洁、直观、强悍的前端开发框架;而Vue是一套用于构建用户界面的渐进式JavaScript框架。
2)bootstrap用于快速开发响应式页面;而vue用于把前端开发组件化。
bootstrap和vue的区别是什么-前端问答-PHP中文网
11. // 转义Html标记
post.setTitle(HtmlUtils.htmlEscape(post.getTitle()));
post.setContent(HtmlUtils.htmlEscape(post.getContent()));
12. ajax异步请求示例:
$.post(
"/community/alpha/ajax",
{"name": "wangwu", "age": 23},
// 浏览器接收到服务器的返回信息后的响应
function (data) {
data = $.parseJSON(data)
console.log(typeof (data))
console.log(data)
console.log(data.code)
console.log(data.msg)
}
)
局部刷新这样的事情同步请求实现不了,只能依靠异步请求
13. 事务管理(特性:ACID)

永久存储器:比如硬盘,内存不可以
其中隔离性值得一聊,隔离性是针对并发而来的
每一个浏览器访问系统部署的服务器使,都会创建一个线程,每个线程又都可能访问数据库而产生自己的事务,因此服务器是一个多线程、多事务的环境。
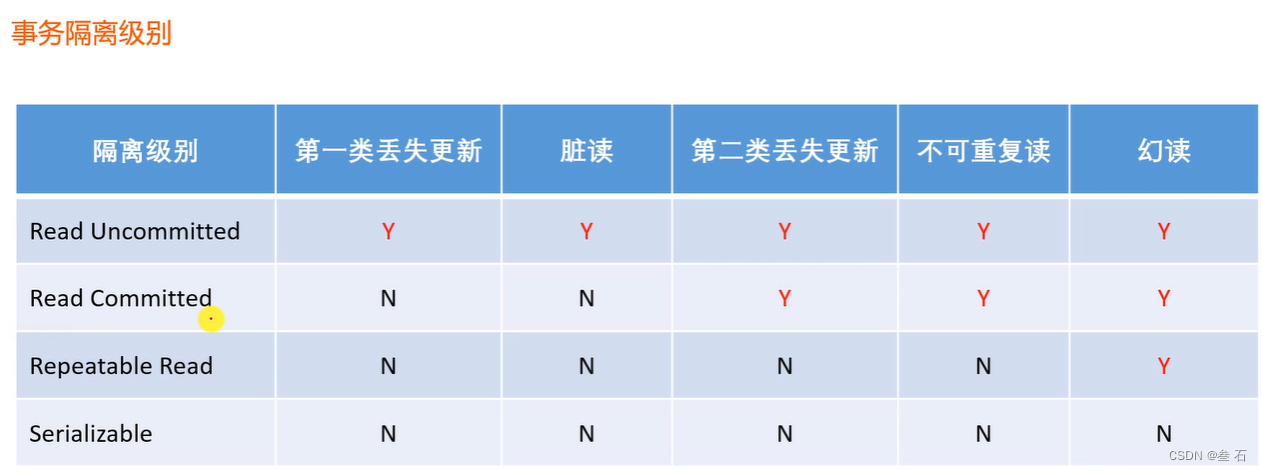
串行化隔离等级可以解决所有常见的的并发异常(第一类丢失更新、、第二类丢失更新、脏读、不可重复读、幻读),但是要给数据库加锁,会使数据库的性能下降的很快。因此企业需要在处理并发异常和处理效率之间进行权衡。

重点注意T1 ~ T6的间隔很短
业务比较复杂,我们只想管理中间某一小部分的事务,可以用编程式事务(通过TransactionTemplate管理事务,并通过它执行数据库操作),否则为了简单,可以使用声明式事务(XML配置 / 注解@Transactional(isolation = Isolation.READ_COMMITED, propagation = “Propagation.REQUIRED”))
Spring对任何数据库的事务管理,使用的api都是相同的。
企业开发中一般选择读已提交和可重复读两种隔离等级,既能满足需要(接近100%保证业务安全性)也能保证性能
1)第一类丢失更新:某一个事务的回滚,导致另一个事务已更新的数据丢失了。(T1-T6时间非常短,T1事务1抢到了CPU时钟……)
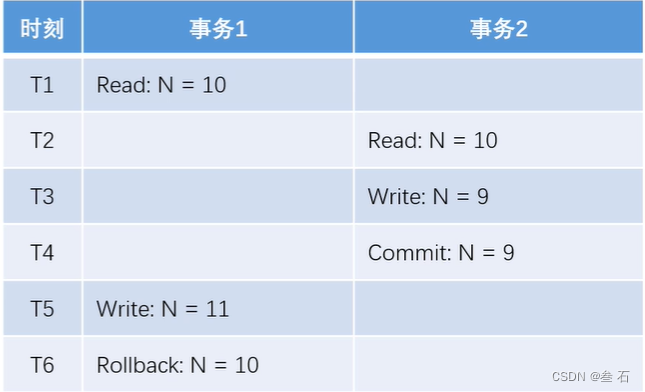
但看事务1和事务2都执行成功了。对于1来说,没什么问题;但对于2来说,因为浏览器的响应速度受网络影响,要远比事务运行时间长,所以在2浏览器上显示的数据是N=10,这就造成了2的事务执行成功了,但是数据仍为修改的情况。
2)第二类丢失更新:某一个事务的提交,导致另外一个事务已更新的数据丢失了。
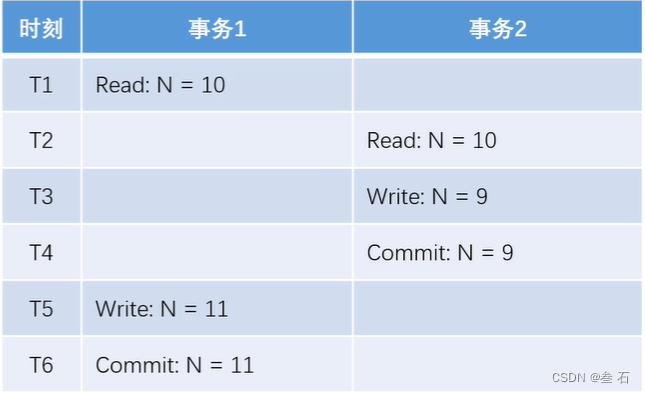
对于1没问题,但对于2,将N改为9的事务执行成功了,但浏览器上显示N=11。
3)脏读:某一个事务,读取了另一个事务还没有提交的数据。
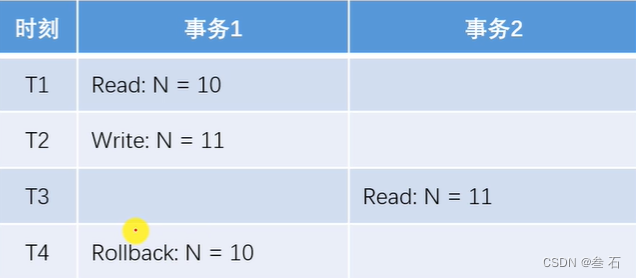
事务1将N变为了10,但事务2读到的是11,是一个错误的数据。
4)不可重复读:某一个事务,对同一个数据前后读取的结果不一致。
(而且是在极短的时间内)(查询结果是同一个数据)
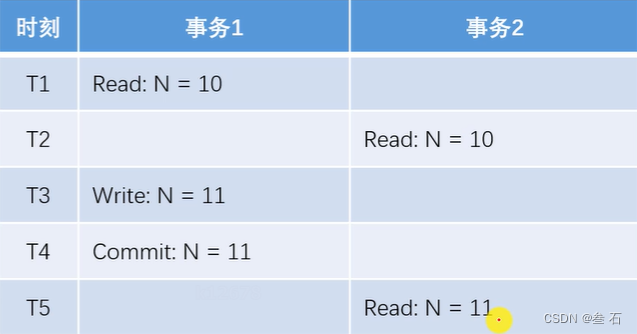
5)幻读:某一个事务,对同一个表前后查询到的行数不一致。(查询结果是数据库表的行数)


14. 评论显示逻辑很复杂,可以看做本项目业务逻辑上的难点之一
(所有的Vo都是Map,其他都是entity)
commentList评论列表, commentVoList评论显示列表
comment:commentList
commentVo存comment, user, replys, replyCount(在comment中已冗余)
replyList
reply:replyList
replyVo存reply, user, target
日报:
2023.07.10:
1. 开发登录、退出功能,借助cookie和session以及kaptcha验证码实现;用注解实现sql语句(包括动态sql)(重点是登陆凭证表LoginTicket,根据status字段确定失效还是有效)
2. 封装从request中读取cookie的方法(implements的方法不能更改参数,所以无法使用!CookieValue("ticket")注解)
3. 用拦截器实现登录信息显示,preHandle在进行controller请求之前执行,其中先根据request得到cookie中的ticket,再根据ticket查表得到loginTicket,再查到user信息,将user用ThreadLocal(线程隔离)存储(setUser)。在postHandle(TemplateEngine之前,正好可以给view提供user信息以供展示)中getUser,并写入到ModelAndView中,最后afterCompletion中clearUser.(拦截器Interceptor要放在WebMvcConfig(实现了WebMvcConfigurer)中配置和使用)
4. 实现部分账号设置(用户头像上传)
2023.07.11:
1. 头像上传到本地一个目录下,调用一个请求(如/community/user/header/{fileName})时,会从这个目录中读取文件,并写入到response的输出流中。
2. 实现修改密码功能(自己独自走了一遍springMVC开发流程,包括用model传值)
3. 自定义注解(一定要有@Tartget()和@Retention()),实现部分接口的登录校验(使用拦截器处理带有自定义注解的方法)
4. 使用前缀树实现敏感词过滤的功能(项目难点)
2023.07.12:
1. 定义前缀树、初始化前缀树(从txt中读取敏感词)、处理文章过滤敏感词(三指针 核心算法)
2. 使用fastjson2封装后端接口的返回信息(code, msg ,map)
3. 使用异步Ajax发送请求,并用jQuery实现发布帖子功能(html转义+过滤敏感词)
4. 完成帖子详情功能开发
2023.07.13:
1. 事务管理,事务ACID特性、五种并发异常、四种隔离等级之间的对应关系。写代码测试Spring中的事务管理(声明式事务,编程式事务)
2. 完成显示评论的代码(业务逻辑较为复杂,可以当做项目难点之一):(所有的Vo都是Map,其他都是entity)
commentList评论列表, commentVoList评论显示列表
comment:commentList
commentVo存comment, user, replys, replyCount(在comment中已冗余)
replyList
reply:replyList
replyVo存reply, user, target
3. 完成添加评论功能
2023.07.14:
请假
1. message表用于存储两个用户之间的私信(会话),from_id, to_id, 还有一个冗余字段conversation_id(将from_id和to_id拼接而成的,规定from_id小的在前, eg:111_112)。有这个conversation_id便于查两个用户之间会话的所有消息。虽然占用了数据库的空间,但能提高查询效率。
2. Redis
键值对形式存储,key都是String, value可以有以下五种常见类型
Redis的所有数据都存放在内存中,所以读写性能较好。内存中的数据可以以快照(从硬盘恢复数据较快,缺点是存储到硬盘时耗时,会产生阻塞,所以不能实时存储,只能几个小时快照一次)和日志(AOF:每执行一次redis命令,就会把命令存下来,所以可以实时,而且是以追加的形式的。从硬盘导入内存中时,需要把所有命令都跑一遍)的方式存储在硬盘中
使用场景:缓存、排行榜、计数器(操作频繁,不能直接访问mysql)、社交网络(点赞、关注)、消息队列
变量名一般用:连接
String: set test:count 1 get test:count incr test:count decr test:count(减1)
Hash: hset test:user id 1; hset test:user username “张三”; hget test:user id; hget test:user username;
List: lpush test:ids 101 102 103; lindex test:ids 0 (103); lrange test:ids 0 2 (103 102 101); rpop test:ids (101); (左右都可以push和pop,因此可以实现栈和队列的功能)
Set: sadd test:teachers a b c d e; scard test:teachers(元素数量 5);spop test:teachers (随机弹出一个元素,可用作抽奖); smembers test:teachers(展示所有元素)
Zset: zadd test:s 10 a 20 b 30 c 40 d 50 e(先分数再value); zcard test:s (5); zrank test:s a (0,从小到大排,包含0); zrange test:s 1 2(b c); zscore test:s e (50) (有序集合,比Set多了分数,可以做排行榜)
全局命令:keys *; keys test*; type test:ids(查看变量类型); exists test:ids;
del test:ids; exprire test:teachers 10(10秒有效期)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









