






MySQL所有版本:
CREATE TABLE `sample` (
`x` float NOT NULL,
`y` float NOT NULL,
`user_name` varchar(255)
) ;
INSERT INTO `sample` VALUES (1, 10, 'zs');
INSERT INTO `sample` VALUES (2, 4, 'zs');
INSERT INTO `sample` VALUES (3, 5, 'zs');
INSERT INTO `sample` VALUES (6, 17, 'zs');
INSERT INTO `sample` VALUES (56, 32, 'ls');
INSERT INTO `sample` VALUES (45, 21, 'ls');
INSERT INTO `sample` VALUES (33, 11, 'ls');
INSERT INTO `sample` VALUES (27, 1, 'ls');
select a.user_name,sum((a.x - b.ax) * (a.y - b.ay))/((count(a.x) -1) * b.diva) corr from sample a
join
(select user_name,
avg(x) ax,
avg(y) ay,
(stddev_samp(x) * stddev_samp(y)) diva
from sample group by user_name) b
on a.user_name = b.user_name
group by user_name;
结果:
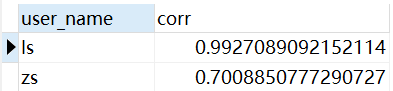
Oracle版本:
select user_name,corr(x,y) corr from (
select 1 as x,10 as y,'zs' as user_name from dual
union all
select 2 as x,4 as y,'zs' as user_name from dual
union all
select 3 as x,5 as y,'zs' as user_name from dual
union all
select 6 as x,17 as y,'zs' as user_name from dual
union all
select 56 as x,32 as y,'ls' as user_name from dual
union all
select 45 as x,21 as y,'ls' as user_name from dual
union all
select 33 as x,11 as y,'ls' as user_name from dual
union all
select 27 as x,1 as y,'ls' as user_name from dual)
group by user_name
结果:

Hive版本:和oracle差不多
select a.user_name,corr(a.x,a.y) corr from (
select 1 as x,10 as y,'zs' as user_name
union all
select 2 as x,4 as y,'zs' as user_name
union all
select 3 as x,5 as y,'zs' as user_name
union all
select 6 as x,17 as y,'zs' as user_name
union all
select 56 as x,32 as y,'ls' as user_name
union all
select 45 as x,21 as y,'ls' as user_name
union all
select 33 as x,11 as y,'ls' as user_name
union all
select 27 as x,1 as y,'ls' as user_name) a
group by a.user_name
结果:















 63
63











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









