







searchAfter简单来说就是将from。。。size中的from用searchAfter的sort字段表示,通过不断更新此sort字段实现向下滚动效果。但是和from不同的是对数据更新不敏感。
search after官网介绍
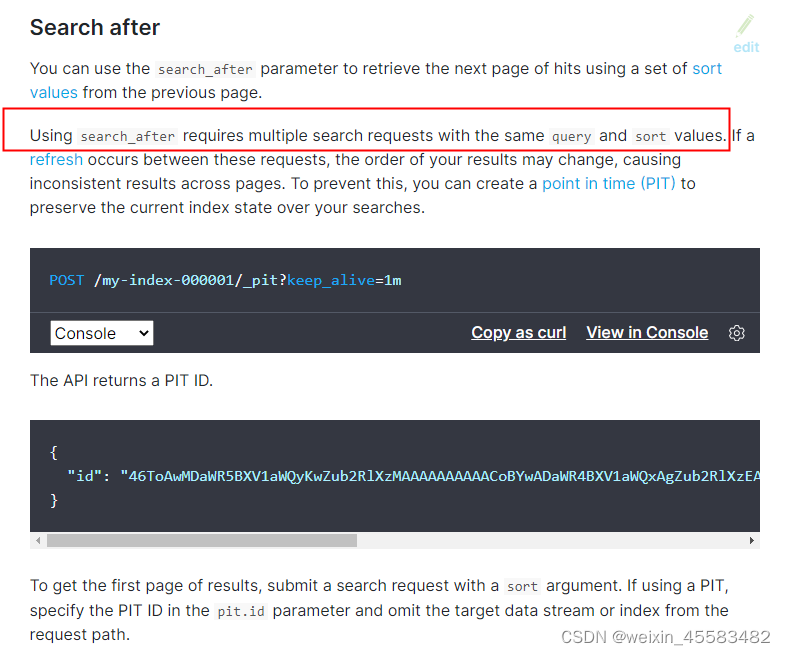
使用search_after时要求你的query值和sort值相同。更具体点是要求你的字段相同,你可以修改它的逻辑,比如你可以查时间为a的数据,那么你将逻辑改为比a大或者比a小都可以,但是你的逻辑必须是时间。sort同理,你可以升序也可以降序但你用来排序的字段不要变。
search-after使用需知:
1 使用search-after时不要修改你的query和sort字段
2 排序后的每条数据都是含有自己的sort值的,且他们都可以作为你接下来的search-after的值
3 请确保你的sort中最后得到的值是唯一的,比如有些数据你用时间排序,你的时间精确度不高导致sort有可能重复,那么你使用search-after后得到的值可能不符合你的预期。有可能有丢失,官方提供的思路是将_doc等元数据也放入排序字段中,因为_doc等数据一般是唯一的,将其加入一般可以保证你的sort字段唯一。
我写了这样个实例,使用@timestamp和_doc来排序,并且将每条数据和它的sort值打印出来。
public static void main(String[] args) {
RestHighLevelClient restHighLevelClient = TestEsCreate.getEsClient("**.**.***.***:*****");//这里是创建RestHighLevelClient的实例,具体实现可以看我之前的代码
SearchRequest searchRequest = new SearchRequest("logstash-applog-*");
searchRequest.source(new SearchSourceBuilder().query(new BoolQueryBuilder()
.filter(QueryBuilders.termQuery("projectName", "*******"))
)
.size(10)
.sort("@timestamp", SortOrder.ASC)
.sort("_doc", SortOrder.ASC)
);
try{
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Object[] arrays = new Object[1];
for(SearchHit hit : searchResponse.getHits().getHits()) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









