







MySQL基本使用&分析思路与优化方向
MySQL
MySQL是一种开源的关系型数据库管理系统,它是最流行的数据库之一。
一、基本使用
1.基本的数据库操作命令
1)修改密码
update user set password=password('123456')where user='root';
2)刷新数据库
flush privileges;
3)显示所有数据库
show databases;
4)打开某个数据库
use dbname;
5)显示数据库mysql中所有的表
show tables;
6)显示表mysql数据库中user表的列信息
describe user;
7)创建数据库
create database name;
8)选择数据库
use databasename;
2.sql 基本语句
1)手写 sql 万能公式:
SELECT DISTINCT <select_list> FROM <left_table> <join_type>
JOIN <right_table> ON
<join_condition> [ 可 以 继 续 left 或 rightJOIN]
WHERE <where_condition>
GROUP BY <group_by_list> HAVING <having_condition>
ORDER BY < order_by_condition> LIMIT <limit_number>
Eg:
select * from t1
left join t2 on condition1 left join t3 on condition2 ...
where condition3
group by col having condition
order by col limit n
2)join的sql写法
①inner join
select <list> from tableA A inner join tableB B on A.key = B.key;
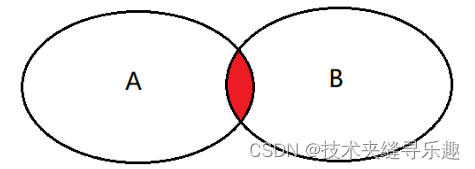
②left join
select <list> from tableA A left join tableB B on A.key = B.key
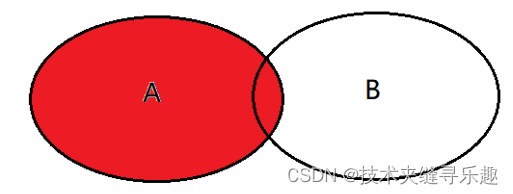
select <list> from tableA A left join tableB B on A.key = B.key where B.key is null
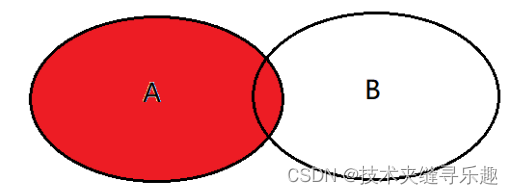
③right join
select <list> from tableA A right join tableB B on A.key = B.key
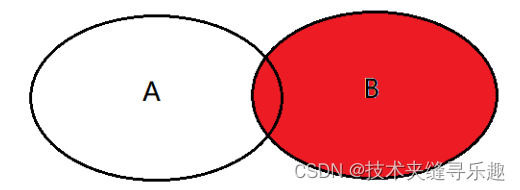
select <list> from tableA A right join tableB B on A.key = B.key where A.key is null
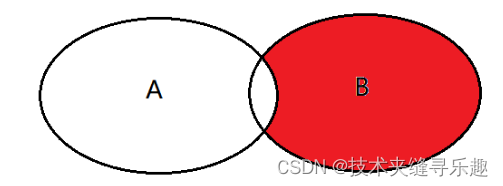
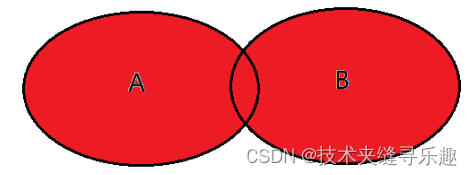
④union合并后去重
用union表示A与B的并集
select <list> from tableA A left join tableB B on A.key = B.key
union
select <list> from tableA A right join tableB B on A.key = B.key
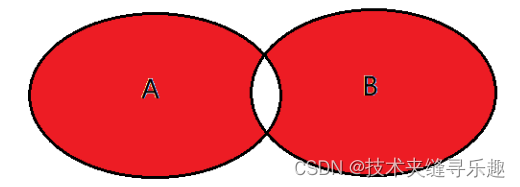
用union表示A与B的并集且不包含交集
select <list> from tableA A left join tableB B on A.key = B.key where B.id is null
union
select <list> from tableA A right join tableB B on A.key = B.key where A.id is null
3)union
用来合并两个或者多个 select 集,这些 select 集必须必须由相同数量的列并且列的类型相同或者相似union:多个结果集合并去重
union All :显示所有,不去重
4)exists 与 in
a.如果两个表中一个较小,一个是大表,则子查询表大的用 exists,子查询表小的用 in:
b.不管 A、B 表大小如何,not exists 都比not in 快
二、数据处理几个实用语句
1.修改、删除前打开修改模式
SET SQL_SAFE_UPDATES = 0;
2.批量导出数据
(1)concat()避免导出时数字太长自动变成了科学计数法
select concat(column1, '\t' ) as 不是科学计数法 from myTable
(2)group_concat()分组后拼接
select column1,group_concat(distinct column2) from myTable group by column1
(3)导出某个库表的数据字典
select
column_comment 名称,column_name 代码,column_comment 注释,column_type 数据类型
from
information_schema.columns
where
-- 数据库名称
table_schema = 'mySchema '
-- 表名
and table_name = 'myTable '
三、Mysql推荐优化方向
1.数据库设计
满足三大范式、按照设计规范、合理的字段类型等
2.业务逻辑
结合业务场景与逻辑结构设计规范做综合考虑,结构与逻辑尽可能清晰、减少冗余,合理建立主键、索引、中间表,同时避免库表字段过多的情况。
3.分析sql语句
通过对Explain、慢查询、死锁、索引选择的合理性进行分析后选择优化方案。
(1)Explain介绍
在select语句之前增加explain关键字,可返回执行计划的信息
Explain中的列:
①id列
id列的编号是select的序列号,有几个select就有几个id,并且id是按照select出现的顺序增长的,id列的值越大优先级越高,id相同则是按照执行计划列从上往下执行,id为空则是最后执行。
②select_type列表示对应行是简单查询还是复杂查询。
1)simple:不包含子查询和union的简单查询
2)primary:复杂查询中最外层的select
3)subquery:包含在select中的子查询(不在from的子句中)
4)derived:包含在from子句中的子查询。mysql会将查询结果放入一个临时表中,此临时表也叫衍生表。
5)union:在union中的第二个和随后的select,UNION RESULT为合并的结果
③ table列
表示当前行访问的是哪张表。当from中有子查询时,table列的格式为,表示当前查询依赖id=N行的查询,所以先执行id=N行的查询,如上面select_type列图4所示。当有union查询时,UNION RESULT的table列的值为<union1,2>,1和2表示参与union的行id。
④ partitions列
查询将匹配记录的分区。 对于非分区表,该值为 NULL。
⑤ type列
此列表示关联类型或访问类型。也就是MySQL决定如何查找表中的行。依次从最优到最差分别为:system > const > eq_ref > ref > range > index > all。
1)NULL:MySQL能在优化阶段分解查询语句,在执行阶段不用再去访问表或者索引。
2)system、const:MySQL对查询的某部分进行优化并把其转化成一个常量(可以通过show warnings命令查看结果)。system是const的一个特例,表示表里只有一条元组匹配时为system。
3)eq_ref:主键或唯一键索引被连接使用,最多只会返回一条符合条件的记录。简单的select查询不会出现这种type。
4)ref:相比eq_ref,不使用唯一索引,而是使用普通索引或者唯一索引的部分前缀,索引和某个值比较,会找到多个符合条件的行。
5)range:通常出现在范围查询中,比如in、between、大于、小于等。使用索引来检索给定范围的行。
6)index:扫描全索引拿到结果,一般是扫描某个二级索引,二级索引一般比较少,所以通常比ALL快一点。
7)ALL:全表扫描,扫描聚簇索引的所有叶子节点。
⑥ possible_keys列
此列显示在查询中可能用到的索引。如果该列为NULL,则表示没有相关索引,可以通过检查where子句看是否可以添加一个适当的索引来提高性能。
⑦ key列
此列显示MySQL在查询时实际用到的索引。在执行计划中可能出现possible_keys列有值,而key列为null,这种情况可能是表中数据不多,MySQL认为索引对当前查询帮助不大而选择了全表查询。如果想强制MySQL使用或忽视possible_keys列中的索引,在查询时可使用force index、ignore index。
⑧ key_len列
此列显示MySQL在索引里使用的字节数,通过此列可以算出具体使用了索引中的那些列。索引最大长度为768字节,当长度过大时,MySQL会做一个类似最左前缀处理,将前半部分字符提取出做索引。当字段可以为null时,还需要1个字节去记录。
⑨ ref列
此列显示key列记录的索引中,表查找值时使用到的列或常量。常见的有const、字段名
⑩ rows列
此列是MySQL在查询中估计要读取的行数。注意这里不是结果集的行数。
⑪ Extra列
此列是一些额外信息。常见的重要值如下:
1)Using index:使用覆盖索引(如果select后面查询的字段都可以从这个索引的树中获取,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值,这种情况一般可以说是用到了覆盖索引)。
2)Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖。
3)Using index condition:查询的列不完全被索引覆盖,where条件中是一个查询的范围。
4)Using temporary:MySQL需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的。
5)Using filesort:将使用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。
6)Select tables optimized away:使用某些聚合函数(比如 max、min)来访问存在索引的某个字段时。
(2)索引
①分类
1)单值索引:即一个索引只包含单个列,一个表可以有多个单列索引
2)唯一索引:索引列的值必须唯一,但允许有空值
3)复合索引:即一个索引包含多个列
②基本语法
创建:
CREATE [UNIQUE] INDEX indexname ON table(colums);
③命令
删除:
DROP INDEX [indexname] ON table;
查看:
SHOW INDEX FROM tablename;
④使用 ALTER 添加数据表索引有四种
1)添加一个主键,索引值必须是唯一的,且不能为 NULL
ALTER TABLE tablename ADD PRMARY KEY(column_list)
2)索引的值必须是唯一的(除了 NULL 外,NULL 可能会出现多次)
ALTER TABLE tablename ADD UNIQUE index_name(column_list)
3)添加普通索引,索引值可出现多次
ALTER TABLE tablename ADD INDEX indexname(column_list)
4)指定索引为 FULLTEXT,用于全文索引
ALTER TABLE tablename ADD FULLTEXT indexname(column);
⑤mysql 索引类型:
1)BTree 索引
2)Hash 索引
3)full-text 全文索引
4)R-Tree 索引
⑥哪些情况创建索引
1)主键自动建立唯一索引
2)频繁作为查询条件的字段应该创建索引
3)查询中与其他表关联的字段,外键关系创建索引
4)频繁更新的字段不适合创建索引—因为每次更新不仅要更新数据还要更新索引
5)Where 条件里用不到的字段不创建索引
6)单键/组合索引的选择问题(在高并发下倾向创建组合索引)
7)查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度—索引和order by 、desc 撞车
8)查询中统计或者分组字段
⑦哪些情况不要创建索引
1)表记录太少
2)经常增删改的表
3)数据重复分布平均的表字段(如果某个数据列包含很多重复内容,建立索引没有太大效果)
假如一个表有10w行记录,有一个字段sex,只有0和1这两种值,且分布概率为50%,那么建立索引一般不会提高数据库查询速度。索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000 条数据,表索引列有1980个不同的值,那么这个索引的选择 性就是1980/2000=0.99.一个索引的选择性越接近 1,这个索引的效率就越高。
(3)慢查询
①查询是否开启慢查询日志
show variables like 'slow_query_log';
②启用慢查询日志
set global slow_query_log='ON'
③查询超过多少秒的记录到慢查询日志中:
show variables like 'long_query_time';
④设置超X秒就记录慢查询sql:
SET GLOBAL long_query_time=10;
SET long_query_time=10;
⑤查看慢查询日志位置:
show variables like 'slow_query_log_file%';
(4)死锁
在使用mysql运行某些语句时,会因数据量太大等原因而导致死锁,没有反应。这个时候,kill掉某个正在消耗资源的query语句即可。但遇到死锁的情况后,需要对造成死锁的原因进行分析,从而寻找优化方案。
查询当前锁的信息:
– 查看正在锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
– 查看等待锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
– 首先查询是否锁表
SHOW OPEN TABLES WHERE In_use > 0;
kill掉某个正在消耗资源的query语句:
(1)-- 查看当前mysql中各个线程状态
show processlist;
(2)-- KILL掉id的命令:
kill 125698;
四、性能分析
复杂SQL优化方案:
1.使用EXPLAIN关键词检查SQL。EXPLAIN可以帮你分析你的查询语句或是表结构的性能瓶颈,EXPLAIN 的查询结果显示帮你分析你的索引主键被如何利用的,你的数据表是如何被搜索和排序的,是否有全表扫描等。
2.查询的条件尽量使用索引字段,如某一个表有多个条件,就尽量使用复合索引查询,复合索引使用要注意字段的先后顺序。
3.多表关联尽量用join,减少子查询的使用。表的关联字段如果能用主键就用主键,也就是尽可能的使用索引字段。如果关联字段不是索引字段可以根据情况考虑添加索引。
4.尽量使用limit进行分页批量查询,不要一次全部获取。
5.绝对避免select *的使用,尽量select具体需要的字段,减少不必要字段的查询。
6.尽量将or 转换为 union all。
7.尽量避免使用is null或is not null。
8.要注意like的使用,前模糊和全模糊不会走索引。
9.Where后的查询字段尽量减少使用函数,因为函数会造成索引失效。
10.避免使用不等于(!=),因为它不会使用索引。
11.用exists代替in,not exists代替not in,效率会更好。
12.避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤,这个处理需要排序,总计等操作。
在此鸣谢以下几位分享知识的伙伴
参考:
https://blog.csdn.net/Hmj050117/article/details/112428329
https://blog.csdn.net/m0_60920163/article/details/119751013
















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









