






什么是大语言模型
大语言模型(Large Language Model,LLM)是一种基于深度学习技术的人工智能模型,具有强大的语言理解、生成和处理能力。以下是关于它的详细介绍:
模型架构与原理
- 大语言模型通常基于 Transformer 架构,这种架构具有出色的并行计算能力和长序列处理能力,能够捕捉文本中的长期依赖关系。它由多个编码器和解码器层组成,每个层包含自注意力机制、前馈神经网络等组件。
- 自注意力机制允许模型在处理每个位置的单词时,动态地关注文本中的其他相关位置,从而更好地理解文本的语义和语法结构。前馈神经网络则对自注意力机制的输出进行进一步的特征提取和变换,以生成最终的语言表示。
训练数据与规模
- 大语言模型需要在海量的文本数据上进行训练,这些数据来源广泛,包括但不限于互联网上的文章、书籍、新闻、社交媒体等。通过对大量文本的学习,模型能够掌握语言的各种模式、规律和语义信息。
- 模型的规模通常非常庞大,参数数量可达数十亿甚至数千亿。例如,GPT-3 模型具有 1750 亿个参数,如此大规模的参数使得模型能够学习到丰富的语言知识,从而具备强大的语言处理能力。
能力与应用
- 语言理解:能够理解输入文本的语义、语法和上下文信息,例如回答问题、进行文本分类、情感分析等。例如,在阅读理解任务中,模型可以根据给定的文本内容,准确回答关于文章细节、主旨、推理等方面的问题。
- 语言生成:可以生成自然流畅的文本,如文章写作、对话生成、机器翻译等。比如,根据给定的主题生成一篇完整的新闻报道,或者与用户进行自然的对话交流。
- 知识推理:利用预训练模型中蕴含的知识进行推理和判断,例如常识推理、逻辑推理等。例如,当被问到 “鸟会飞,企鹅是鸟,企鹅会飞吗?” 时,模型能够根据其所学的知识进行正确的推理和回答。
局限性
- 知识准确性:尽管大语言模型能够生成看似合理的文本,但它并不总是准确的,可能会生成错误或误导性的信息。
- 可解释性:模型的决策过程相对复杂,难以解释其生成结果的具体原因和依据,这给应用带来了一定的风险和不确定性。
- 计算资源需求:训练和部署大语言模型需要大量的计算资源,包括高性能的 GPU 集群等,这增加了模型的使用成本和门槛。
安装 LangChain
安装 LangChain 的过程相对简便,以下是详细的安装步骤和注意事项:
1. 环境准备
确保已安装 Python 3.8.1 或更高版本:
python --version # 检查Python版本
若未安装 Python,可从官网下载或使用包管理器(如brew、apt)安装。
2. 安装 LangChain
使用pip安装 LangChain 的核心库:
pip install langchain
可选依赖:
根据具体需求,安装额外的工具和集成(例如 OpenAI、Hugging Face 等):
# 常用依赖示例
pip install langchain openai chromadb tiktoken pdfplumber # 按需选择
3. 配置 API 密钥(以 OpenAI 为例)
若使用 OpenAI 模型,需设置 API 密钥:
# Linux/macOS
export OPENAI_API_KEY="your-openai-api-key"
# Windows
set OPENAI_API_KEY="your-openai-api-key"
或在代码中设置:
import os
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
4. 验证安装
通过以下代码验证 LangChain 是否正常工作:
from langchain.llms import OpenAI
# 初始化模型(需已配置API密钥)
llm = OpenAI(temperature=0.7)
# 生成文本
text = llm("请介绍一下人工智能的发展历程。")
print(text)
常见问题与解决方案
版本冲突:
使用虚拟环境隔离依赖:
python -m venv myenv # 创建虚拟环境
source myenv/bin/activate # 激活环境(Linux/macOS)
myenv\Scripts\activate # 激活环境(Windows)
网络问题:
使用国内镜像源加速下载:
pip install langchain -i https://pypi.tuna.tsinghua.edu.cn/simple
特定工具安装失败:
例如chromadb依赖问题,可尝试:
pip install chromadb --no-binary chromadb
OpenAI API
关于 ChatGPT 和 GPT-4,我想就没有必要赘言了,网上已经有太多资料了。但是要继续咱们的 LangChain 实战课,你需要对 OpenAI 的 API 有进一步的了解。因为,LangChain 本质上就是对各种大模型提供的 API 的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。
因此,要了解 LangChain 的底层逻辑,需要了解大模型的 API 的基本设计思路。而目前接口最完备的、同时也是最强大的大语言模型,当然是 OpenAI 提供的 GPT 家族模型。
当然,要使用 OpenAI API,你需要先用科学的方法进行注册,并得到一个 API Key。
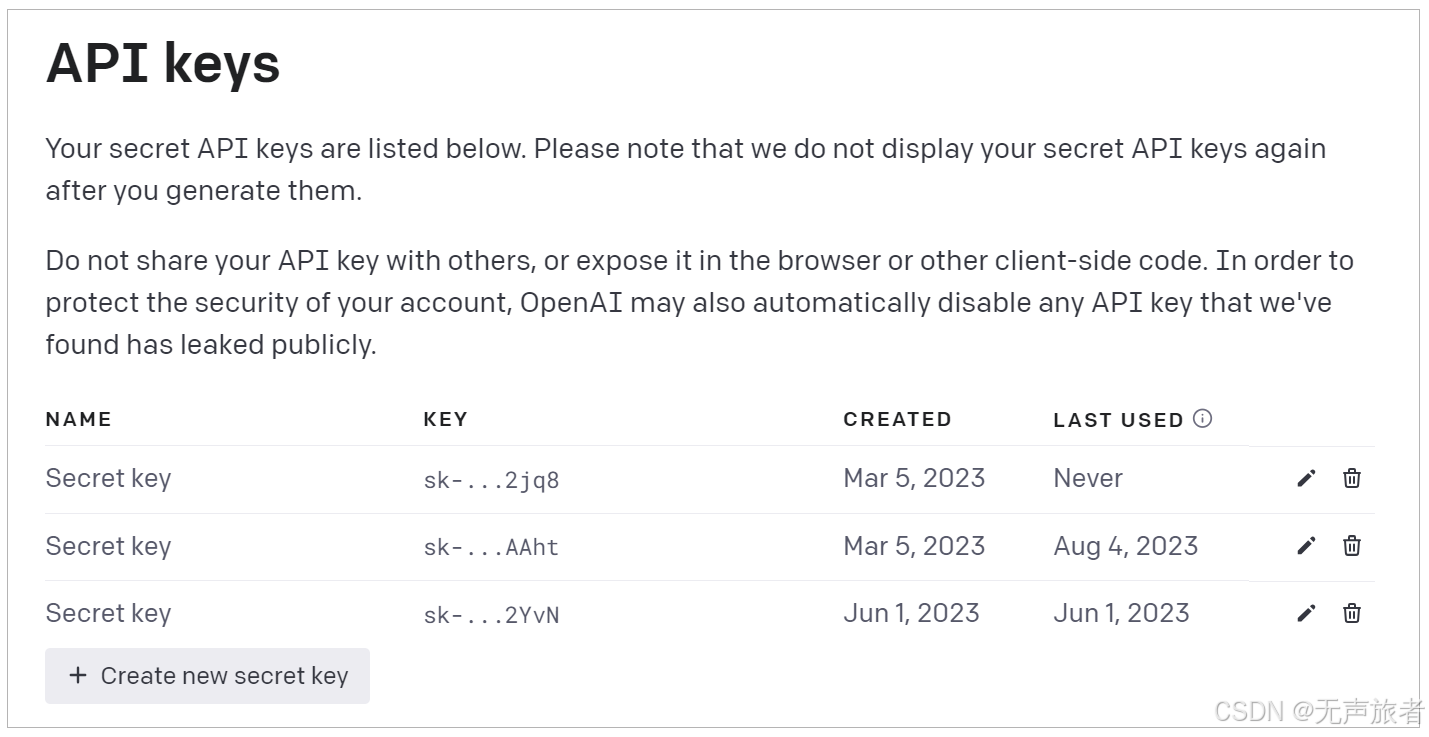
有了 OpenAI 的账号和 Key,你就可以在面板中看到各种信息,比如模型的费用、使用情况等。下面的图片显示了各种模型的访问数量限制信息。其中,TPM 和 RPM 分别代表 tokens-per-minute、requests-per-minute。也就是说,对于 GPT-4,你通过 API 最多每分钟调用 200 次、传输 40000 个字节。
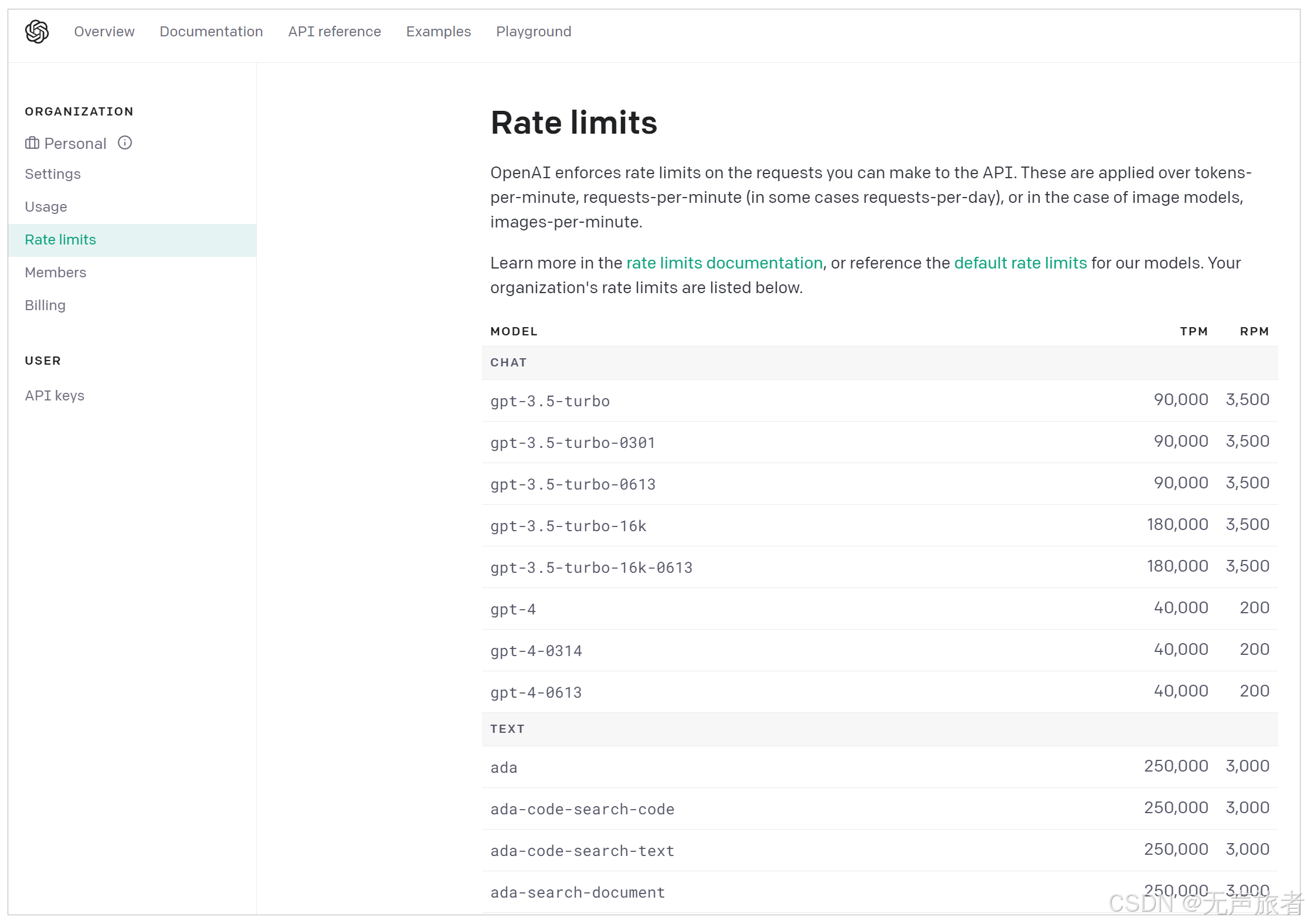
这里,我们需要重点说明的两类模型,就是图中的 Chat Model 和 Text Model。这两类 Model,是大语言模型的代表。当然,OpenAI 还提供 Image、Audio 和其它类型的模型,目前它们不是 LangChain 所支持的重点,模型数量也比较少。
- Chat Model,聊天模型,用于产生人类和 AI 之间的对话,代表模型当然是 gpt-3.5-turbo(也就是 ChatGPT)和 GPT-4。当然,OpenAI 还提供其它的版本,gpt-3.5-turbo-0613 代表 ChatGPT 在 2023 年 6 月 13 号的一个快照,而 gpt-3.5-turbo-16k 则代表这个模型可以接收 16K 长度的 Token,而不是通常的 4K。(注意了,gpt-3.5-turbo-16k 并未开放给我们使用,而且你传输的字节越多,花钱也越多)
- Text Model,文本模型,在 ChatGPT 出来之前,大家都使用这种模型的 API 来调用 GPT-3,文本模型的代表作是 text-davinci-003(基于 GPT3)。而在这个模型家族中,也有专门训练出来做文本嵌入的 text-embedding-ada-002,也有专门做相似度比较的模型,如 text-similarity-curie-001。
上面这两种模型,提供的功能类似,都是接收对话输入(input,也叫 prompt),返回回答文本(output,也叫 response)。下一篇我会例举进一步说明。
延伸阅读
探秘 Cursor 核心:解锁系统提示词的进阶之路
智能推荐系统中个性化推荐 Agent 的高效构建:核心模块与关键技术解析
中转API教程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









