






引言:
在金融市场中,投资者始终在寻求一种策略来最大化他们的收益并最小化风险。马科维茨模型(Markowitz Model),作为现代投资组合理论的基石,为我们提供了一个框架来构建这样的策略。然而,在实践中,我们经常发现基于历史数据构建的有效前沿(Efficient Frontier)组合在后续的时间段测试中表现并不如预期,甚至失去了其应有的曲线特征。这背后的原因是什么呢?如何使模型具备实用性?
一、马科维茨模型简介
马科维茨模型,也被称为均值-方差模型,它假设投资者是理性的,他们只关心投资组合的预期收益和风险(方差)。模型通过求解一个二次规划问题,找到在给定的预期收益水平下风险最小的投资组合,或者在给定的风险水平下预期收益最大的投资组合。这些投资组合的集合构成了有效前沿。
二、编程实现
现代投资者可以通过编程来寻找有效前沿(Efficient Frontier)组合。
作为编程新手在参考文章和AI辅助下磕磕绊绊完成了编程。如果有什么错误请指正。欢迎修改其中的代码,将功能分模块函数化。
参考文章链接:https://blog.csdn.net/weixin_41963050/article/details/121373388
编程的时候有些问题,原文计算了相关系数,但是对模型本身没有作用。
找前沿组合还是靠蒙特卡洛模拟。是否有更好的方法?
100%的仓位分到10个股票上,步长为1%,可以0-100%的话有4万亿种可能,测试一亿种不重复组合也才测了4万分之一的组合。用这个方法只能处理较少的股票组合和较粗的仓位精度。
import pandas as pd
import numpy as np
import akshare as ak
import matplotlib.pyplot as plt
from datetime import datetime
# 准备股票代码
stock_list = ['600176',
'002594',
'002080',
'000733',
'600373',
'300142',
'300498',
'002625',
'000519',
'603290',
'300502']
# 将股票代码从小到大排序
stock_list.sort()
# 设定准备数据的时间段
# 用作计算的数据时间段
start_date_cal = '20210701'
end_date_cal = '20210930'
# 用作测试的数据时间段
start_date_test = '20211001'
end_date_test = '20211115'
# 创建一个空的 DataFrame 来存储所有股票的数据
all_stocks_data = pd.DataFrame()
# 遍历股票列表并获取数据
for stock_code in stock_list:
df = ak.stock_zh_a_hist(symbol=stock_code, adjust="hfq", start_date=min(start_date_cal, start_date_test),
end_date=max(end_date_cal, end_date_test))
if not df.empty:
# 添加一个表示股票代码的列
df['股票代码'] = stock_code
# 将这个股票的数据追加到 all_stocks_data 中
all_stocks_data = pd.concat([all_stocks_data, df], ignore_index=True)
# 划分计算数据集和测试数据集
all_stocks_data_cal = all_stocks_data[all_stocks_data['日期'] < datetime.strptime(start_date_test, '%Y%m%d').date()][
['日期', '股票代码', '收盘']]
all_stocks_data_test = all_stocks_data[all_stocks_data['日期'] >= datetime.strptime(start_date_test, '%Y%m%d').date()][[
'日期', '股票代码', '收盘']]
############################################
data_for_cal = pd.DataFrame()
data_for_test = pd.DataFrame()
data_for_cal_all = pd.DataFrame()
data_for_test_all = pd.DataFrame()
for stock_code in stock_list:
data_for_cal = all_stocks_data_cal.loc[all_stocks_data_cal['股票代码'] == stock_code].copy()
data_for_test = all_stocks_data_test.loc[all_stocks_data_test['股票代码'] == stock_code].copy()
# 获取第一天的收盘价
first_close_price = data_for_cal['收盘'].iloc[0]
# 获取测试集第一天收盘价
first_close_price_test = data_for_test['收盘'].iloc[0]
data_for_cal['收盘_比率'] = data_for_cal['收盘'] / first_close_price # 计算比率并添加到新列
data_for_test['收盘_比率'] = data_for_test['收盘'] / first_close_price_test # 计算比率并添加到新列
# 初始化一个新的DataFrame列来存储每天的相对收益率
data_for_cal['日收益率'] = 0.0
data_for_test['日收益率'] = 0.0
# 使用shift方法来获取前一天的收盘比率,并计算每天的相对收益率
# 注意:第一天的收益率是NaN,因为没有前一天的数据可以比较
data_for_cal['日收益率'] = (data_for_cal['收盘_比率'] - data_for_cal['收盘_比率'].shift(1)) / data_for_cal[
'收盘_比率'].shift(1)
data_for_test['日收益率'] = (data_for_test['收盘_比率'] - data_for_test['收盘_比率'].shift(1)) / data_for_test[
'收盘_比率'].shift(1)
# 替换第一天的NaN值为0,或者你可以选择删除第一天,因为通常没有前一天的数据来比较
data_for_cal.loc[data_for_cal.index[0], '日收益率'] = 0
# 或者,如果你想要忽略第一天的NaN值,可以使用dropna方法(但这会删除第一行)
# filtered_data = filtered_data.dropna(subset=['日收益率'])
# 结果保存到data_for_cal_all
data_for_cal_all = pd.concat([data_for_cal_all, data_for_cal])
# 结果保存到data_for_test_all
data_for_test_all = pd.concat([data_for_test_all, data_for_test])
# 计算各股票的日收益率的相关矩阵
data_for_cal_all['日收益率'] = data_for_cal_all['日收益率'].fillna(0)
pivot_table = data_for_cal_all.pivot_table(index='日期', columns='股票代码', values='日收益率', aggfunc='mean')
pivot_table_test = data_for_test_all.pivot_table(index='日期', columns='股票代码', values='日收益率', aggfunc='mean')
correlation_matrix = pivot_table.corr()
correlation_matrix_test = pivot_table_test.corr()
# 保存相关矩阵到csv文件
# 将股票代码转换为字符串,以便在csv文件中正确显示
correlation_matrix.columns = [str(col) for col in correlation_matrix.columns]
correlation_matrix_test.columns = [str(col) for col in correlation_matrix_test.columns]
correlation_matrix.to_csv('correlation_matrix.csv')
correlation_matrix_test.to_csv('correlation_matrix_test.csv')
pivot_table_close = data_for_cal_all.pivot_table(index='日期', columns='股票代码', values='收盘_比率', aggfunc='mean')
# 初始化列表来存储结果
returns = []
volatilities = []
# 蒙特卡洛模拟的次数
num_simulations = 10000
# 初始化结果DataFrame
results = pd.DataFrame(columns=['Total_Return', 'Volatility'] + [stock_list[i-1] for i in range(1, len(stock_list) + 1)])
# 蒙特卡洛模拟
for i in range(num_simulations):
# 生成随机仓位比例
raw_allocations = np.random.rand(len(stock_list))
# 归一化
allocations = raw_allocations / raw_allocations.sum()
# 四舍五入到最近的1%步长
rounded_allocations = np.round(allocations * 100) / 100
# 重新归一化确保总和为1
rounded_allocations = rounded_allocations / rounded_allocations.sum()
# 计算投资组合的日收益率
portfolio_returns = pivot_table.mul(rounded_allocations, axis=1).sum(axis=1)
# 计算投资组合总收益率
total_return = (1 + portfolio_returns).prod()-1
# 计算波动率(使用标准差)
volatility = portfolio_returns.std()
# 存储结果(在这个例子中,我们只模拟了一次)
returns.append(total_return)
volatilities.append(volatility)
# 将结果保存到DataFrame中
result_row = {
'Total_Return': total_return,
'Volatility': volatility,
}
for j, alloc in enumerate(rounded_allocations, 1):
result_row[stock_list[j-1]] = alloc
results = pd.concat([results, pd.DataFrame([result_row])], ignore_index=True)
# 把有效前沿组合选出来
results['ReturnsRound'] = round(results['Total_Return'], 2)
returns_range = pd.DataFrame(sorted(results['ReturnsRound'])).drop_duplicates()[0].tolist()
vol_min_idx_l = []
for i in returns_range:
vol_min = results[results['ReturnsRound'] == i].Volatility.min()
vol_min_idx = results[results['Volatility'] == vol_min].index[0]
vol_min_idx_l.append(vol_min_idx)
# 保存有效前沿组合到csv
results.loc[vol_min_idx_l].to_csv('efficient_frontier_portfolio.csv')
results.loc[vol_min_idx_l].plot('Volatility', 'Total_Return', kind='scatter', alpha=0.3)
plt.show()
# 计算有效前沿组合在测试时间段的收益率
RandomPortfolios = results.loc[vol_min_idx_l].drop(['ReturnsRound', 'Volatility', 'Total_Return'], axis=1)
Returns_test = []
for i in range(results.loc[vol_min_idx_l].shape[0]):
Returns_test.append((pivot_table_test.mul(RandomPortfolios.iloc[i], axis=1).sum(axis=1)+1).prod()-1)
RandomPortfolios['Returns_test'] = Returns_test
# 计算夏普比率
RandomPortfolios['Sharpe_Ratio'] = (RandomPortfolios['Returns_test'] - 0.03) / results.loc[vol_min_idx_l].Volatility
RandomPortfolios['Volatility'] = results.loc[vol_min_idx_l].Volatility
# 保存有效前沿组合在测试时间段的结果
RandomPortfolios.to_csv('efficient_frontier_portfolio_test.csv')
# 绘制有效前沿组合在测试时间段的收益率
RandomPortfolios.plot('Volatility', 'Returns_test', kind='scatter', alpha=0.3)
plt.show()
三、历史数据与有效前沿实测
通过使用akshare库来获取历史股票数据,并基于这些数据来构建有效前沿。然而,历史数据只能反映过去的市场情况,它并不能完全预测未来的市场走势。因此,基于历史数据构建的有效前沿组合在未来市场中的表现存在很大的不确定性。
在实践中,我们经常发现基于历史数据构建的有效前沿(Efficient Frontier)组合在后续的时间段测试中表现并不如预期,甚至失去了其应有的曲线特征。
通过和参考文章同样的设置,进行一万次投骰子,收益率精度为0.01的情况下,同一时间段模拟的结果如下(竖轴为收益率,横轴为波动率):
备注:原文对收益率可能没有-1且计算的是年化收益率,我这没有年化,精度还是0.01,所以数据点要少不少。可以自行年化或者把精度调整到0.001
计算集前沿组合散点图 测试集同样组合的散点图
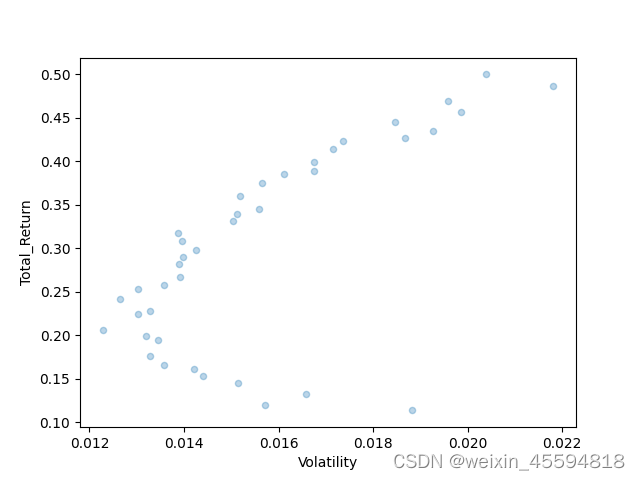
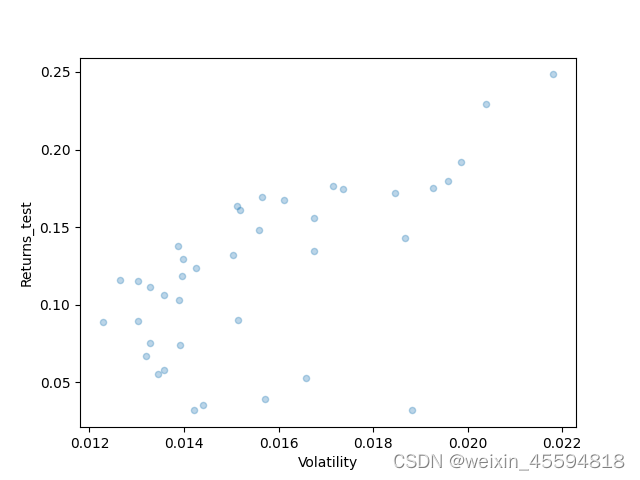
同样股票换一个时间段后
start_date_cal = '20240101'
end_date_cal = '20240331'
start_date_test = '20240401'
end_date_test = '20240515'
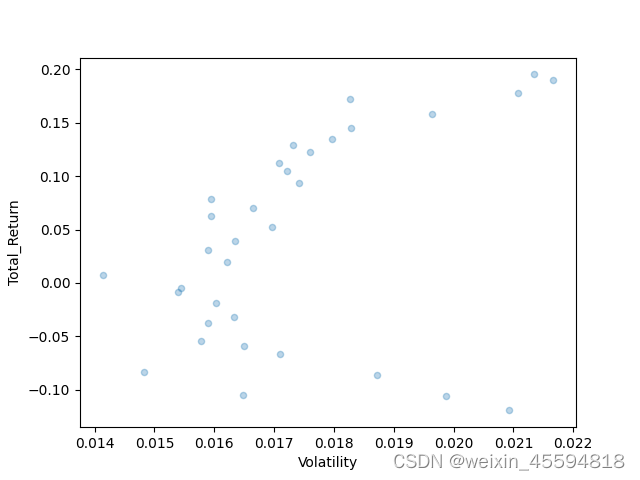
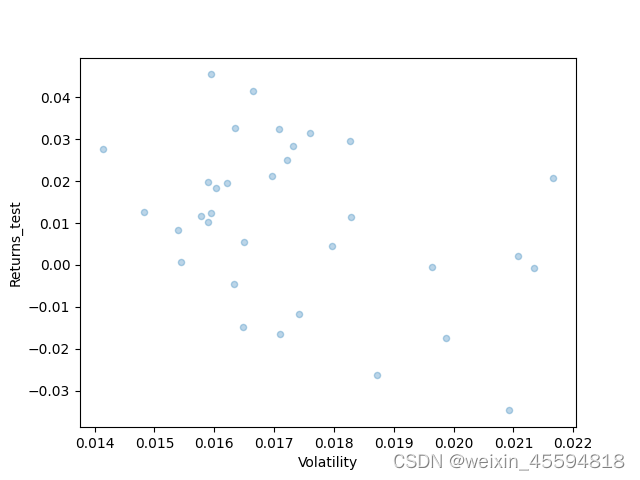
如图所示,3个月数据用于计算,10000次模拟得到的前沿组合在后一个半月的表现没有规律。
各位可以尝试不同股票和日期组合
四、为什么历史数据的前沿组合在后续测试中表现不佳?
-
市场变动性:金融市场是高度变动和不确定的。过去的市场情况可能无法准确反映未来的市场走势。因此,基于历史数据构建的投资组合在未来市场中可能不再是最优的。
-
模型假设的局限性:马科维茨模型基于一系列假设,如投资者是理性的、市场是有效的等。然而,这些假设在现实中可能并不完全成立。例如,投资者可能受到情绪、偏见等因素的影响,市场也可能存在信息不对称、操纵等问题。
-
参数估计的误差:在构建有效前沿时,我们需要估计股票的预期收益、协方差等参数。然而,这些参数的估计可能存在误差,尤其是在样本量较小或市场波动较大的情况下。这些误差可能导致我们构建的投资组合偏离真实的有效前沿。
-
测试时间段的选择:选择两个不同的时间段来获取数据和进行测试的情况下。如果这两个时间段的市场环境存在显著差异(如牛市和熊市),那么基于历史数据构建的投资组合在后续测试中的表现可能会受到很大影响。
五、思考
如何使马科维茨模型具备实用性?可能有几种方向,一起探讨一下。
1.调整参数,例如更多的模拟次数,根据市场周期调整计算集等。
2.定期模拟,更加频繁的调整组合仓位。
3.结合其他方法...

















 2462
2462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









