







之前学习了 C++ 中原子变量的内存顺序,现在我们来看看原子变量和内存顺序的应用 – 无锁队列。本文介绍单写单读和多写多读的无锁队列的简单实现,从中可以看到无锁数据结构设计的一些基本思路。
何谓无锁?
为了实现一个线程安全的数据结构,最简单的方法就是加锁。对于队列来说,应该对入队和出队操作加锁。
template <typename T>
void queue::push(const T &val) {
std::lock_guard<std::mutex> guard(m_lock);
auto node = new node(val);
...
}
template <typename T>
T queue::pop() {
std::lock_guard<std::mutex> guard(m_lock);
...
}
这样的队列的问题是,同一时间只能有一个线程执行入队和出队操作,这样队列的操作实际是串行化的。如果有多个线程同时访问同一个队列,这个队列可能会成为并发的瓶颈。为了解决这个问题,在一些场景下我们可以考虑使用无锁队列。
无锁数据接口可以分为三类:
nonblocking 结构:
- 使用自旋锁而不是互斥量,不会出现上下文切换。
- 不能算是无锁 (lock-free),它并不允许并发访问,同样存在操作串行化的问题。
lock-free 结构:
- 精心设计的操作,通过 CAS (compare and swap) 原子操作实现并发访问。多个线程可以同时访问。
- 存在类似自旋锁的循环,需要在循环中检查和等待。
wait-free 结构:不存在类似自旋锁的循环,操作只需要执行确定数量的指令。
单写单读的队列
单写单读的队列比较简单,这里我们使用循环队列实现。如下图所示,队列维护两个指针 head 和 tail,分别指向队首和队尾。tail 始终指向 dummy 节点,这样 tail == head 表示队列为空,(tail + 1) % Cap == head 表示队列已满,不用维护 size 成员。
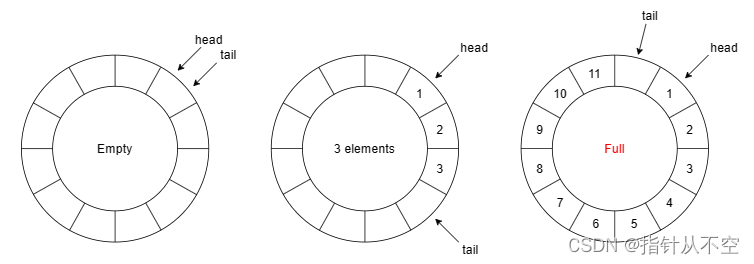
入队的时候移动 tail 指针,而出队的时候移动 head 指针,两个操作并无冲突。不过,出队前需要读取 tail 指针,判断 tail != head 确认队列不为空。同理入队时也要判断 (tail + 1) % Cap != head 以确认队列不满。由于存在多个线程读写这两个指针,因此它们都应该是原子变量。
此外,由于两个操作在不同线程中执行,我们还需考虑内存顺序。如果初始队列为空,线程 a 先执行入队操作,线程 b 后执行出队操作,则线程 a 入队操作的内容要对线程 b 可见。
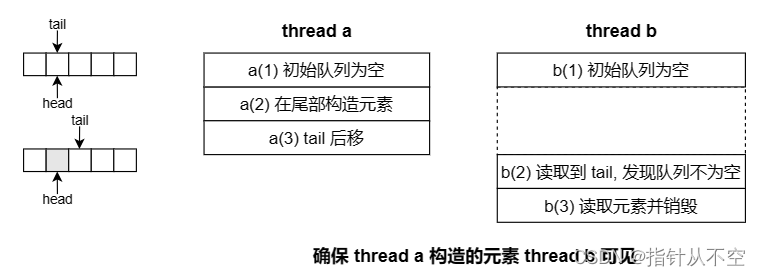
为了做到这一点,需要有 a(2) happens-before b(3)。 而 a(3) 和 b(2) 分别修改了读取了 tail,所以应该利用原子变量同步,使得 a(3) synchronizes-with b(2)。可以在 a(3) 写入 tail 的操作中使用 release,b(2) 读取 tail 的操作中使用 acquire 实现同步。
同理,如果初始队列满,线程 a 先执行出队操作,线程 b 后执行入队操作,则线程 a 出队操作的结果要对线程 b 可见。 出队的时候需要调用出队元素的析构函数,要保证出队元素正常销毁后才能在那个位置写入新元素,否则会导致内存损坏。可以在出队写入 head 的操作中使用 release,入队读取 head 的操作中使用 acquire 实现出队 synchronizes-with 入队。
template <typename T, size_t Cap>
class spsc : private allocator<T> {
T *data;
atomic<size_t> head{0}, tail{0};
public:
spsc(): data(allocator<T>::allocate(Cap)) {}
spsc(const spsc&) = delete;
spsc &operator=(const spsc&) = delete;
spsc &operator=(const spsc&) volatile = delete;
bool push(const T &val) {
return emplace(val);
}
bool push(T &&val) {
return emplace(std::move(val));
}
template <typename ...Args>
bool emplace(Args && ...args) { // 入队操作
size_t t = tail.load(memory_order_relaxed);
if ((t + 1) % Cap == head.load(memory_order_acquire)) // (1)
return false;
allocator<T>::construct(data + t, std::forward<Args>(args)...);
// (2) synchronizes-with (3)
tail.store((t + 1) % Cap, memory_order_release); // (2)
return true;
}
bool pop(T &val) { // 出队操作
size_t h = head.load(memory_order_relaxed);
if (h == tail.load(memory_order_acquire)) // (3)
return false;
val = std::move(data[h]);
allocator<T>::destroy(data + h);
// (4) synchronizes-with (1)
head.store((h + 1) % Cap, memory_order_release); // (4)
return true;
}
};
这种单写单读的无锁队列的两种操作可以同时执行,主要是因为它们操作不同的端点:一个操作尾部(tail),另一个操作头部(head)。由于每个操作只修改它各自的端点,并且使用原子操作来确保内存顺序,因此两个操作互不干扰,可以安全地并发执行。
此外,由于每次操作都只是简单地移动头部或尾部指针,并在必要时对元素进行构造或销毁,操作的复杂度固定,这就保证了操作的 wait-free 特性,即在有限的步骤内必定完成,不会因为其他线程的干预而延迟。
多写多读的队列
单读写队列的局限
为了说明前面实现的单写单读队列无法执行多写多读,我们来看一个例子。
bool spsc<T, Cap>::pop(T &val) {
size_t h = head.load(); // (1)
if (h == tail.load())
return false;
val = std::move(data[h]); // (2)
allocator<T>::destroy(data + h);
head.store((h + 1) % Cap); // (3)
return true;
}
假设有两个线程 a 和 b 同时调用 pop,执行顺序是 a(1), b(1), b(2) a(2)。这种情况下,线程 a 和线程 b 都读到相同的 head 指针,存储在变量 h 中。当 a(2) 尝试读取 data[h] 时,其中的数据已经在 b(2) 中被 move 走了。因此这样的队列不允许多个线程同时执行 pop 操作。
解决抢占问题
可以看到,整个 pop 函数是一个非原子过程,一旦这个过程别其他线程抢占,就会出问题。
如何解决这个问题呢?在无锁数据结构中,一种常用的做法是不断重试。具体的做法是,在非原子过程的最后一步设计一个 CAS 操作,如果过程被其他线程抢占,则 CAS 操作失败,并重新执行整个过程。否则 CAS 操作成功,完成整个过程的最后一步。
bool spsc<T, Cap>::pop(T &val) {
size_t h;
do {
h = head.load(); // (1)
if (h == tail.load())
return false;
val = data[h]; // (2)
} while (!head.compare_exchange_strong(h, (h + 1) % Cap)); // (3)
return true;
}
首先注意到我们不再使用 std::move 和 allocator::destroy,而是直接复制,使得循环体内的操作不会修改队列本身。(3) 是整个过程的最后一步,也是唯一会修改队列的一步,我们使用了一个 CAS 操作。只有当 head 的值等于第 (1) 步获取的值的时候,才会移动 head 指针,并且返回 true 跳出循环,否则就不断重试。
这样如果多个线程并发执行 pop,则只有成功执行 (3) 的线程被视为成功执行了整个过程,其它的线程都会因为被抢占,导致执行 (3) 的时候 head 被修改,因而与局部变量 h 不相等,导致 CAS 操作失败。这样它们就要重试整个过程。
类似的思路也可以用在 push 上,看看如果我们用同样的方式修改 push 会怎样:
bool spsc<T, Cap>::push(const T &val) {
size_t t;
do {
t = tail.load(); // (1)
if ((t + 1) % Cap == head.load())
return false;
data[t] = val; // (2)
} while (!tail.compare_exchange_strong(t, (t + 1) % Cap)); // (3)
return true;
}
与 pop 操作不同,push 操作的第 (2) 步需要对 data[t] 赋值,导致循环体内的操作会修改队列。假设 a,b 两个线程的执行顺序是 a(1),a(2),b(1),b(2),a(3)。 a 可以成功执行到 (3),但是入队的值却被 b(2) 覆盖掉了。
我们尝试将赋值操作 data[t] = val 移到循环的外面,这样循环体内的操作就不会修改队列了。当循环退出时,能确保 tail 向后移动了一格,且 t 指向 tail 移动前的位置。这样并发的时候就不会有其他线程覆盖我们写入的值。
bool spsc<T, Cap>::push(const T &val) {
size_t t;
do {
t = tail.load(); // (1)
if ((t + 1) % Cap == head.load())
return false;
} while (!tail.compare_exchange_strong(t, (t + 1) % Cap)); // (2)
data[t] = val; // (3)
return true;
}
但是这样做的问题是,我们先移动 tail 指针再对 data[t] 赋值,会导致 push 与 pop 并发不正确。回顾下 pop 的代码:
bool spsc<T, Cap>::pop(T &val) {
size_t h;
do {
h = head.load();
if (h == tail.load()) // (4)
return false;
val = data[h]; // (5)
} while (!head.compare_exchange_strong(h, (h + 1) % Cap));
return true;
}
同样假设有两个线程 a 和 b,假设队列初始为空:
- 线程 a 调用 push,执行 a(1),a(2)。tail 被更新,然后切换到线程 b。
- 线程 b 调用 pop,执行 b(4)。因为 tail 被更新,因此判断队列不为空。
- 执行到 b(5),会读取到无效的值。
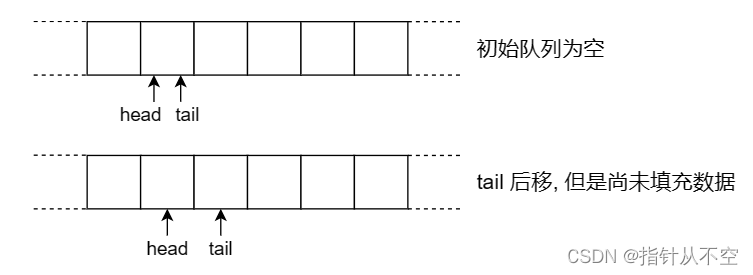
为了实现 push 与 pop 的并发,push 对 data[t] 的写入必须 happens-before ,pop 对 data[h] 的读取。因此这就要求 push 操作先对 data[t] 赋值,再移动 tail 指针。可是前面为了实现 push 与 push 的并发我们又让 push 操作先移动 tail 再对 data[t] 赋值。如何解决这一矛盾呢?
解决办法是引入一个新的指针 write,用于 push 与 pop 同步。它表示 push 操作写到了哪个位置。
template <typename T, size_t Cap>
class ring_buffer {
T data[Cap];
atomic<size_t> head{0}, tail{0}, write{0};
public:
ring_buffer() = default;
ring_buffer(const ring_buffer&) = delete;
ring_buffer &operator=(const ring_buffer&) = delete;
ring_buffer &operator=(const ring_buffer&) volatile = delete;
bool push(const T &val) {
size_t t, w;
do {
t = tail.load();
if ((t + 1) % Cap == head.load())
return false;
} while (!tail.compare_exchange_weak(t, (t + 1) % Cap)); // (1)
data[t] = val; // (2)
do {
w = t;
} while (!write.compare_exchange_weak(w, (w + 1) % Cap)); // (3), (3) synchronizes-with (4)
return true;
}
bool pop(T &val) {
size_t h;
do {
h = head.load();
if (h == write.load()) // (4) 读 write 的值
return false;
val = data[h]; // (5)
} while (!head.compare_exchange_strong(h, (h + 1) % Cap));
return true;
}
};
push 操作的基本步骤是:
- 移动 tail。
- 对 data[t] 赋值,t 等于 tail 移动前的位置。
- 移动 write,write 移动后等于 tail。
而 pop 操作使用 write 指针判断队列中是否有元素,因为有 (3) “ synchronizes-with ” (4),所以 (2) “happens-before” (5),pop 能读到 push 写入的值。在 push 函数中,只有在当前的 write 等于 t 时才将 write 移动一格,能确保最终 write 等于 tail。
这种多写多读的无锁队列的两种操作可以同时执行,但是每种操作都有可能要重试,因此属于 lock-free 结构。
考虑内存顺序
前面例子使用默认的内存顺序,也就是 memory_order_seq_cst。为了优化性能,可以使用更宽松的内存顺序。而要考虑内存顺序,就要找出其中的 happens-before 的关系。
前面分析了,push 中的赋值操作 data[t] = val 要 “ happens-before ” pop 中的读取操作 val = data[h],这是通过 write 原子变量实现的:push 中对 write 的修改要 “ synchronizes-with ” pop 中对 write 的读取。因此 push 修改 write 的 CAS 操作应该使用 release,pop 读取 write 时则应使用 acquire。
同理,当队列初始为满的时候,先运行 pop 在运行 push,要保证 pop 中的读取操作 val = data[h] “ happens-before ” push 中的赋值操作 data[t] = val。
这是通过 head 原子变量实现的:pop 中对 head 的修改要 “ synchronizes-with ” push 中对 head 的读取。因此 pop 修改 head 的 CAS 操作应该使用 release,push 读取 head 时则应使用 acquire。
bool ring_buffer<T, Cap>::push(const T &val) {
size_t t, w;
do {
t = tail.load(memory_order_relaxed); // (1)
if ((t + 1) % Cap == head.load(memory_order_acquire)) //(2)
return false;
} while (!tail.compare_exchange_weak(t, (t + 1) % Cap, memory_order_relaxed)); // (3)
data[t] = val; // (4), (4) happens-before (8)
do {
w = t;
} while (!write.compare_exchange_weak(w, (w + 1) % Cap,
memory_order_release, memory_order_relaxed)); // (5), (5) synchronizes-with (7)
return true;
}
bool ring_buffer<T, Cap>::pop(T &val) {
size_t h;
do {
h = head.load(memory_order_relaxed); // (6)
if (h == write.load(memory_order_acquire)) // (7)
return false;
val = data[h]; // (8), (8) happens-before (4)
} while (!head.compare_exchange_strong(h, (h + 1) % Cap,
memory_order_release, memory_order_relaxed)); // (9), (9) synchronizes-with (2)
return true;
}
push 与 push 并发移动 tail 指针的时候,只影响到 tail 本身。因此 (1) 和 (3) 对 tail 读写使用 relaxed 就可以了。同样 push 与 push 并发移动 write 指针时,也不需要利用它做同步,因此 (5) 处的做法是
write.compare_exchange_weak(w, (w + 1) % Cap,
memory_order_release, memory_order_relaxed)
成功时使用 release,为了与 pop 同步。而失败时使用 relaxed 就可以了。
同理, pop 与 pop 并发移动 head 时,也影响到 head 本身。因此 (6) 读取 head 使用 relaxed 即可。而 (9) 处为了与 push 同步,成功时要使用 release,失败时使用 relaxed 即可。
优势与缺陷
优势
实现简单,容易理解 (相比更复杂的链式结构)。
无锁高并发,虽然存在循环重试,但是这只会在相同操作并发的时候出现。push 不会因为与 pop 并发而重试,反之亦然。
缺陷
这样队列只应该存储标量,不应该存储对象 (但是可以存储指针),原因如下:
- pop 中会循环执行 val = data[h] ,对象的拷贝会有性能开销。
- push 中执行 data[t] = val 类似,如果拷贝时间过长,可能会导致并发执行 push 的线程一直等待。
- 如果 push 中 data[t] = val 抛出了异常, 可能会导致并发执行 push 的线程死锁
不能存储智能指针。因为出队后对象仍然在 data 数组里,并没有销毁。
容量是固定的,不能动态扩容。
性能测试
设置不同的生产者和消费者线程数量,每个生产者向依次队列里插入 10000 个元素。下面是测试结果, “ XpYc ” 表示 X 个生产者 Y 个消费者,纵坐标为耗时。
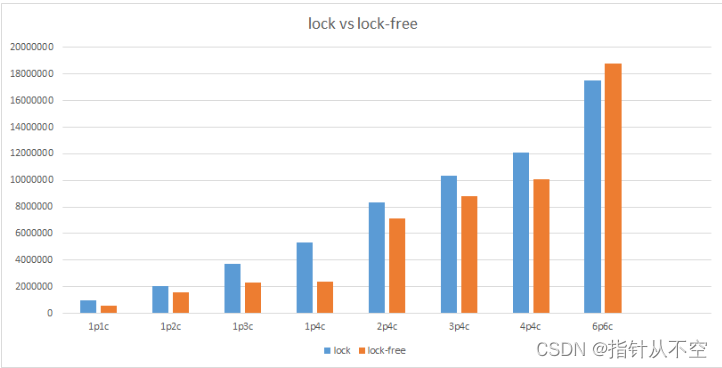
可以看到无锁队列并不总是最快, 当生产者数量增多时, 性能开始下降, 因为入队的时候需要抢占 tail 和 write。














 3269
3269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









